图像金字塔技术在很多层面上都有着广泛的应用,很多开源的工具也都有对他们的建立写了专门的函数,比如IPP,比如OpenCV等等,这方面的理论文章特别多,我不需要赘述,但是我发现大部多分开源的代码的实现都不是严格意义上的金字塔,而是做了一定的变通,这种变通常常为了快捷的实现类似的效果,虽然这种变通不太会影响金字塔的效果,但是我这里希望从严格意义上对该算法进行优化,比如简要贴一下下面的某个高斯金字塔的代码:
public static Mat[] build(Mat img, int level) {
Mat[] gaussPyr = new Mat[level];
Mat mask = filterMask(img);
Mat tmp = new Mat();
Imgproc.filter2D(img, tmp, -1, mask);
gaussPyr[0] = tmp.clone();
Mat tmpImg = img.clone();
for (int i = 1; i < level; i++) {
// resize image
Imgproc.resize(tmpImg, tmpImg, new Size(), 0.5, 0.5, Imgproc.INTER_LINEAR);
// blur image
tmp = new Mat();
Imgproc.filter2D(tmpImg, tmp, -1, mask);
gaussPyr[i] = tmp.clone();
}
return gaussPyr;
}
private static Mat filterMask(Mat img) {
double[] h = { 1.0 / 16.0, 4.0 / 16.0, 6.0 / 16.0, 4.0 / 16.0, 1.0 / 16.0 };
Mat mask = new Mat(h.length, h.length, img.type());
for (int i = 0; i < h.length; i++) {
for (int j = 0; j < h.length; j++) {
mask.put(i, j, h[i] * h[j]);
}
}
return mask;
}上面的过程是对原图线进行双线性的下采样插值,然后再对采样后的图进行一定的高斯模糊。我们说这样做未尝不可,而真正的高斯金字塔的建立过程是:对上一级的数据进行高斯模糊(5x5)得到结果T,然后删除T的奇数行和奇数列数据作为下一级的结果(以0为下标起点的行列)。在此过程中使用到的高斯模糊的权重矩阵的形式如下所示:
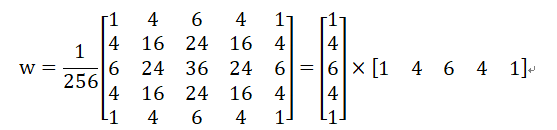
应该说,上面的过程用伪代码表示应该是:
Imgproc.filter2D(tmpImg, tmp, -1, mask);
Imgproc.resize(tmp, tmp, new Size(), 0.5, 0.5, Imgproc.INTER_NEARESTNEIGHBOR); 即先高斯模糊,然后在使用最近领插值缩小一半,和上面代码中的先双性缩小一半,再进行高斯模糊还是有区别的。从编程优化的角度考虑,我们没有必要完整的对上一级进行高斯模糊,而只需要进行偶数行和偶数列的计算,然后赋值到下一层数据中,而进一步考虑上述矩阵的特殊性,可以通过减少重复计算以及合并相同系数项等手段来优化。对于边缘(2行2列)的像素,把他单独提取出来,减少中间数据的边缘判断可进一步提高速度。
再提出第一版C语言代码之前,我们来要看下各层金字塔的大小问题,如果上一层的大小位偶数,则下一层直接就除以2,但是如果是奇数,则除2时需要向上取整,比如宽某层的宽度尺寸为101,则之后的各层依次为101->51->26->13->7->4->2->1。
再看看前面权重矩阵的式子最右边那个乘法,那表示这个权重矩阵是行列可分离的,我们可以先计算行的加权,然后再利用这个加权值计算列的加权,也可以先计算列然后再计算行,这样原本每个像素处的25个乘法和多24次加法就可以减少为10次乘法和9次加法。对于沿着宽度方向的更新计算,我们还可以充分利用列方向的重叠累计信息,减少计算量,一个可行的简单的代码如下所示:
int IM_DownSample8U_C1(unsigned char *Src, unsigned char *Dest, int SrcW, int SrcH, int StrideS, int DstW, int DstH, int StrideD, int Channel)
{
if ((Channel != 1) && (Channel != 3) && (Channel != 4)) return IM_STATUS_NOTSUPPORTED;
if (DstW != ((SrcW + 1) >> 1) || DstH != ((SrcH + 1) >> 1)) return IM_STATUS_INVALIDPARAMETER; // 尺寸匹配
int Status = IM_STATUS_OK;
if (Channel == 1)
{
int Sum1, Sum2, Sum3, Sum4, Sum5;
for (int Y = 1; Y < DstH - 1; Y++) // 不处理边缘部分数据
{
unsigned char *LinePD = Dest + Y * StrideD ;
unsigned char *P1 = Src + (Y * 2 - 2) * StrideS;
unsigned char *P2 = P1 + StrideS;
unsigned char *P3 = P2 + StrideS;
unsigned char *P4 = P3 + StrideS;
unsigned char *P5 = P4 + StrideS;
Sum3 = P1[0] + ((P2[0] + P4[0]) << 2) + P3[0] * 6 + P5[0];
Sum4 = P1[1] + ((P2[1] + P4[1]) << 2) + P3[1] * 6 + P5[1];
Sum5 = P1[2] + ((P2[2] + P4[2]) << 2) + P3[2] * 6 + P5[2];
for (int X = 1; X < DstW - 1; X++)
{
Sum1 = Sum3; Sum2 = Sum4; Sum3 = Sum5;
Sum4 = P1[3] + ((P2[3] + P4[3]) << 2) + P3[3] * 6 + P5[3];
Sum5 = P1[4] + ((P2[4] + P4[4]) << 2) + P3[4] * 6 + P5[4];
LinePD[X] = (Sum1 + ((Sum2 + Sum4) << 2) + Sum3 * 6 + Sum5 + 128) >> 8; // 注意四舍五入
P1 += 2; P2 += 2; P3 += 2; P4 += 2; P5 += 2;
}
}
}
else if (Channel == 3)
{
}
else if (Channel == 4)
{
}
for (int X = 0; X < DstW; X++)
{
//IM_DownSamplePerPixel8U(Src, Dest, SrcW, SrcH, StrideS, DstW, DstH, StrideD, Channel, X, 0); // 第一行及最后一行
//IM_DownSamplePerPixel8U(Src, Dest, SrcW, SrcH, StrideS, DstW, DstH, StrideD, Channel, X, DstH - 1);
}
for (int Y = 1; Y < DstH - 1; Y++)
{
//IM_DownSamplePerPixel8U(Src, Dest, SrcW, SrcH, StrideS, DstW, DstH, StrideD, Channel, 0, Y); // 第一列及最后一列
//IM_DownSamplePerPixel8U(Src, Dest, SrcW, SrcH, StrideS, DstW, DstH, StrideD, Channel, DstW - 1, Y);
}
return IM_STATUS_OK;
}注意到,在单通道的示例里,我们用了5个中间变量,分别记录了某个位置5列像素的累加和,在移动到下一个目标像素时,由于我们是隔行隔列采样的,因此移动到下一个像素时只有3个位置时重叠的,也就是说只有3个分量可以重复利用,另外两个必须重新计算。
上面的代码是先计算列方向,然后在计算行方向的,基本上不需要额外的内存,我们再来试下先计算行方向的累积值,再处理列方向的方案:
int IM_DownSample8U_C2(unsigned char *Src, unsigned char *Dest, int SrcW, int SrcH, int StrideS, int DstW, int DstH, int StrideD, int Channel)
{
if ((Channel != 1) && (Channel != 3) && (Channel != 4)) return IM_STATUS_NOTSUPPORTED;
if (DstW != ((SrcW + 1) >> 1) || DstH != ((SrcH + 1) >> 1)) return IM_STATUS_INVALIDPARAMETER; // 尺寸匹配
int Status = IM_STATUS_OK;
unsigned short *Sum0 = (unsigned short *)malloc(DstW * Channel * sizeof(unsigned short));
unsigned short *Sum1 = (unsigned short *)malloc(DstW * Channel * sizeof(unsigned short));
unsigned short *Sum2 = (unsigned short *)malloc(DstW * Channel * sizeof(unsigned short));
unsigned short *Sum3 = (unsigned short *)malloc(DstW * Channel * sizeof(unsigned short));
unsigned short *Sum4 = (unsigned short *)malloc(DstW * Channel * sizeof(unsigned short));
if ((Sum0 == NULL) || (Sum1 == NULL) || (Sum2 == NULL) || (Sum3 == NULL) || (Sum4 == NULL))
{
Status = IM_STATUS_OUTOFMEMORY;
goto FreeMemroy;
}
for (int Y = 1; Y < DstH - 1; Y++) // 不处理边缘部分数据
{
unsigned char *LinePD = Dest + Y * StrideD;
if (Y == 1)
{
IM_DownSampleLine8U_C(Src + 0 * StrideS, Sum0, DstW, Channel);
IM_DownSampleLine8U_C(Src + 1 * StrideS, Sum1, DstW, Channel);
IM_DownSampleLine8U_C(Src + 2 * StrideS, Sum2, DstW, Channel);
IM_DownSampleLine8U_C(Src + 3 * StrideS, Sum3, DstW, Channel);
IM_DownSampleLine8U_C(Src + 4 * StrideS, Sum4, DstW, Channel);
}
else
{
unsigned short *Temp1 = Sum0, *Temp2 = Sum1;
Sum0 = Sum2; Sum1 = Sum3; Sum2 = Sum4;
Sum3 = Temp1; Sum4 = Temp2;
IM_DownSampleLine8U_C(Src + (Y * 2 + 1) * StrideS, Sum3, DstW, Channel);
IM_DownSampleLine8U_C(Src + (Y * 2 + 2) * StrideS, Sum4, DstW, Channel);
}
for (int X = Channel; X < (DstW - 1) * Channel; X++)
{
LinePD[X] = (Sum0[X] + ((Sum1[X] + Sum3[X]) << 2) + Sum2[X] * 6 + Sum4[X] + 127) >> 8;
}
}
for (int X = 0; X < DstW; X++)
{
//IM_DownSamplePerPixel8U(Src, Dest, SrcW, SrcH, StrideS, DstW, DstH, StrideD, Channel, X, 0); // 第一行及最后一行
//IM_DownSamplePerPixel8U(Src, Dest, SrcW, SrcH, StrideS, DstW, DstH, StrideD, Channel, X, DstH - 1);
}
for (int Y = 1; Y < DstH - 1; Y++)
{
//IM_DownSamplePerPixel8U(Src, Dest, SrcW, SrcH, StrideS, DstW, DstH, StrideD, Channel, 0, Y); // 第一列及最后一列
//IM_DownSamplePerPixel8U(Src, Dest, SrcW, SrcH, StrideS, DstW, DstH, StrideD, Channel, DstW - 1, Y);
}
FreeMemroy:
if (Sum0 != NULL) free(Sum0);
if (Sum1 != NULL) free(Sum1);
if (Sum2 != NULL) free(Sum2);
if (Sum3 != NULL) free(Sum3);
if (Sum4 != NULL) free(Sum4);
return Status;
}其中IM_DownSampleLine8U_C函数如下所示:
// 一行像素的下取样算法,权重系数为1 4 6 4 1,并且是隔列取样
void IM_DownSampleLine8U_C(unsigned char *Src, unsigned short *Dest, int DstLen, int Channel)
{
// 只处理中间有效范围内的数,第一个和最后一个不处理
if (Channel == 1)
{
for (int Y = 1, Index = 2; Y < DstLen - 1; Y++, Index += 2)
{
Dest[Y] = Src[Index - 2] + ((Src[Index - 1] + Src[Index + 1] ) << 2) + Src[Index] * 6 + Src[Index + 2];
}
}
else if (Channel == 3) // 一个load语句可以包含5个完整像素,可以处理1个目标像素,3个分量占6个字节,不好保存,因此,一次性处理2个目标像素就好保存了
{
}
else if (Channel == 4) // 4个通道的一次性只处理一个像素的,需要访问源图像20个字节范围
{
}
}注意到上述代码在结构上和第一版本其实差不多,不过多了5行临时内存,在更新行权重的时候也是只需要更新2行的,而无需整体更新。
我们对这两种方案进行了速度测试,由于本身这个的执行速度就比较块,因此我们对算法进行了100次计算,对于第一级为1920*1080大小的灰度图,下一级的高斯金字塔大小为960*540像素,算法C1测试的结果为267ms,算法C2的执行速度约为256ms,这说明他们本质上不存在大的速度差异(这里的时间都不包括处理边缘像素的,后面还要讨论,并且高斯金字塔也是采用unsigned char类型数据来保存的)。
在某些场合,我们还需要加快这个过程的速度,因此我考虑使用SSE优化他,考虑以上两种实现方式,哪一种更有利于SSE的处理呢,由于第一种方式前后的依赖比较强,用SSE做不是不可以,但估计效率不会有提升,需要太多次数据重组了,而第二种方式的由中间数据计算最后的结果很明显可以使用SSE处理,即下面的这三行代码:
for (int X = Channel; X < (DstW - 1) * Channel; X++)
{
LinePD[X] = (Sum0[X] + ((Sum1[X] + Sum3[X]) << 2) + Sum2[X] * 6 + Sum4[X] + 127) >> 8;
}这里的Sum是16位的,LinePD是8位的。替换的代码如下所示:
int BlockSize = 8, Block = (DstW - 1 - 1) * Channel / BlockSize;
for (int X = Channel; X < Block * BlockSize + Channel; X += BlockSize)
{
__m128i S0 = _mm_loadu_si128((__m128i *)(Sum0 + X));
__m128i S1 = _mm_loadu_si128((__m128i *)(Sum1 + X));
__m128i S2 = _mm_loadu_si128((__m128i *)(Sum2 + X));
__m128i S3 = _mm_loadu_si128((__m128i *)(Sum3 + X));
__m128i S4 = _mm_loadu_si128((__m128i *)(Sum4 + X));
__m128i Sum = _mm_add_epi16(_mm_add_epi16(_mm_add_epi16(_mm_add_epi16(S0, S4), _mm_slli_epi16(_mm_add_epi16(S1, S3), 2)), _mm_mullo_epi16(S2, _mm_set1_epi16(6))), _mm_set1_epi16(127));
_mm_storel_epi64((__m128i *)(LinePD + X), _mm_packus_epi16(_mm_srli_epi16(Sum, 8), _mm_setzero_si128()));
}
for (int X = Block * BlockSize + Channel; X < (DstW - 1) * Channel; X++)
{
LinePD[X] = (Sum0[X] + ((Sum1[X] + Sum3[X]) << 2) + Sum2[X] * 6 + Sum4[X] + 127) >> 8;
}这么个简单的改动,速度大概到了180ms。
有点麻烦的是IM_DownSampleLine8U_C这个函数的优化,其核心代码如下:
for (int Y = 1, Index = 2; Y < DstLen - 1; Y++, Index += 2)
{
Dest[Y] = Src[Index - 2] + ((Src[Index - 1] + Src[Index + 1] ) << 2) + Src[Index] * 6 + Src[Index + 2];
}最简单的SSE处理方式是加载5次不同位置的Src值,然后将数据转换为16位,再进行加法和乘法计算。
int ValidLen = DstLen - 2; // -2是因为第一和最后一个点的部分取样值是不在有效范围内的
int BlockSize = 8, Block = ValidLen / BlockSize;
for (int Y = 1; Y < Block * BlockSize + 1; Y += BlockSize)
{
int Index = (Y - 1) * 2;
__m128i SrcV0 = _mm_cvtepu8_epi16(_mm_loadl_epi64((__m128i *)(Src + Index)));
__m128i SrcV1 = _mm_cvtepu8_epi16(_mm_loadl_epi64((__m128i *)(Src + Index + 1)));
__m128i SrcV2 = _mm_cvtepu8_epi16(_mm_loadl_epi64((__m128i *)(Src + Index + 2)));
__m128i SrcV3 = _mm_cvtepu8_epi16(_mm_loadl_epi64((__m128i *)(Src + Index + 3)));
__m128i SrcV4 = _mm_cvtepu8_epi16(_mm_loadl_epi64((__m128i *)(Src + Index + 4)));
_mm_storeu_si128((__m128i *)(Dest + Y), _mm_add_epi16(_mm_add_epi16(SrcV0, SrcV1), _mm_add_epi16(_mm_slli_epi16(_mm_add_epi16(SrcV1, SrcV3), 2), _mm_mullo_epi16(SrcV2, _mm_set1_epi16(6)))));
}
for (int Y = Block * BlockSize + 1; Y < DstLen - 1; Y++)
{
Dest[Y] = Src[Y * 2 - 2] + Src[Y * 2 - 1] * 4 + Src[Y * 2] * 6 + Src[Y * 2 + 1] * 4 + Src[Y * 2 + 2];
}一次性处理8个像素,需要多次加载内存,原以为速度会有问题,结果一测,速度居然飙升到40ms,单次只需要0.4ms了。真的很高兴。
但是和普通的C比较一下,似乎结果不对啊,仔细分析,原来是因为这个对Src取样计算时每次是隔一个点取一个样的,而上述代码侧连续采样的,那怎么办呢?
也很简单,我们使用_mm_loadu_si128一次性加载16个字节,然后每隔一个像素就置0,这样就相当于把剩下的8个像素的值直接变为了16位数据了,一举两得。如下所示:
int ValidLen = DstLen - 2; // -2是因为第一和最后一个点的部分取样值是不在有效范围内的
int BlockSize = 8, Block = ValidLen / BlockSize;
__m128i Mask = _mm_setr_epi8(255, 0, 255, 0, 255, 0, 255, 0, 255, 0, 255, 0, 255, 0, 255, 0);
for (int Y = 1; Y < Block * BlockSize + 1; Y += BlockSize)
{
int Index = (Y - 1) * 2;
__m128i SrcV0 = _mm_and_si128(_mm_loadu_si128((__m128i *)(Src + Index + 0)), Mask);
__m128i SrcV1 = _mm_and_si128(_mm_loadu_si128((__m128i *)(Src + Index + 1)), Mask);
__m128i SrcV2 = _mm_and_si128(_mm_loadu_si128((__m128i *)(Src + Index + 2)), Mask);
__m128i SrcV3 = _mm_and_si128(_mm_loadu_si128((__m128i *)(Src + Index + 3)), Mask);
__m128i SrcV4 = _mm_and_si128(_mm_loadu_si128((__m128i *)(Src + Index + 4)), Mask);
_mm_storeu_si128((__m128i *)(Dest + Y), _mm_add_epi16(_mm_add_epi16(SrcV0, SrcV4), _mm_add_epi16(_mm_slli_epi16(_mm_add_epi16(SrcV1, SrcV3), 2), _mm_mullo_epi16(SrcV2, _mm_set1_epi16(6)))));
}
for (int Y = Block * BlockSize + 1; Y < DstLen - 1; Y++)
{
Dest[Y] = Src[Y * 2 - 2] + Src[Y * 2 - 1] * 4 + Src[Y * 2] * 6 + Src[Y * 2 + 1] * 4 + Src[Y * 2 + 2];
}我们上面用的and运算来将有关位置0,当然还可以使用 shuffle指令来得到同样的结果,速度大概也就稍微慢一点,大概再45ms。
实际上,在这里的由于权重有一些特殊性,比如有2个1,2个4,4还可以用移位实现,如果是一些其他不太有规律的权重,比如 3 7 9 7 3这种,我们实际上还有一种优化方式来处理,因为在SSE里还有一个_mm_maddubs_epi16这个指令,他可以一次性实现16个字节数*16个signed char,然后再两两相加保存到8个short类型中去,比如上面的代码也可以用下面的方式实现:
int ValidLen = DstLen - 2; // -2是因为第一和最后一个点的部分取样值是不在有效范围内的
int BlockSize = 6, Block = ValidLen / BlockSize;
// Src S0 S1 S2 S3 S4 S5 S6 S7 S8 S9 S10 S11 S12 S13 S14 S15 // 16个像素
// Dst D1 D2 D3 D4 D5 D6 // 有效位置的只有6个结果
// 1 4 6 4 1 4 6 4 1 4 6 4 1 4 6 4
__m128i Cof = _mm_setr_epi8(1, 4, 6, 4, 1, 4, 6, 4, 1, 4, 6, 4, 1, 4, 6, 4); // 用同一个系数不影响,因为后面反正抛弃了后半部分的累加 //__m128i Cof1 = _mm_setr_epi8(1, 4, 6, 4, 1, 4, 6, 4, 1, 4, 6, 4, 1, 4, 6, 4);
// 1 4 6 4 1 4 6 4 1 4 6 4 1 4 6 4
//__m128i Cof2 = _mm_setr_epi8(1, 4, 6, 4, 1, 4, 6, 4, 0, 0, 0, 0, 0, 0, 0, 0);
for (int Y = 1; Y < Block * BlockSize + 1; Y += BlockSize)
{
// S0 S1 S2 S3 S4 S5 S6 S7 S8 S9 S10 S11 S12 S13 S14 S15
__m128i SrcV = _mm_loadu_si128((__m128i *)(Src + (Y - 1) * 2));
// S0 S1 S2 S3 S2 S3 S4 S5 S4 S5 S6 S7 S6 S7 S8 S9
__m128i Src1 = _mm_shuffle_epi8(SrcV, _mm_setr_epi8(0, 1, 2, 3, 2, 3, 4, 5, 4, 5, 6, 7, 6, 7, 8, 9));
// S8 S9 S10 S11 S10 S11 S12 S13 S4 S6 S8 S10 S12 S14 0 0
__m128i Src2 = _mm_shuffle_epi8(SrcV, _mm_setr_epi8(8, 9, 10, 11, 10, 11, 12, 13, 4, 6, 8, 10, 12, 14, -1, -1));
// S0 + S1 * 4 S2 * 6 + S3 * 4 S2 + S3 * 4 S4 * 6 + S5 * 4 S4 + S5 * 4 S6 * 6 + S7 * 4 S6 + S7 * 4 S8 * 6 + S9 * 4
__m128i Dst1 = _mm_maddubs_epi16(Src1, Cof); // _mm_maddubs_epi16(Src1, Cof1);
// S8 + S9 * 4 S10 * 6 + S11 * 4 S10 + S11 * 4 S12 * 6 + S13 * 4 0 0 0 0 0 0 0 0
__m128i Dst2 = _mm_maddubs_epi16(Src2, Cof); // _mm_maddubs_epi16(Src1, Cof2);
// S0 + S1 * 4 + S2 * 6 + S3 * 4 S2 + S3 * 4 + S4 * 6 + S5 * 4 S4 + S5 * 4 + S6 * 6 + S7 * 4 S6 + S7 * 4 + S8 * 6 + S9 * 4 S8 + S9 * 4 + S10 * 6 + S11 * 4 S10 + S11 * 4 + S12 * 6 + S13 * 4
__m128i Dst12 = _mm_hadd_epi16(Dst1, Dst2);
// S0 + S1 * 4 + S2 * 6 + S3 * 4 + S4 S2 + S3 * 4 + S4 * 6 + S5 * 4 + S6 S4 + S5 * 4 + S6 * 6 + S7 * 4+ S8 S6 + S7 * 4 + S8 * 6 + S9 * 4 + S10 S8 + S9 * 4 + S10 * 6 + S11 * 4 + S12 S10 + S11 * 4 + S12 * 6 + S13 * 4 + S14
__m128i Dst = _mm_add_epi16(Dst12, _mm_unpackhi_epi8(Src2, _mm_setzero_si128()));
_mm_storeu_epi96((__m128i *)(Dest + Y), Dst);
}
for (int Y = Block * BlockSize + 1; Y < DstLen - 1; Y++)
{
Dest[Y] = Src[Y * 2 - 2] + Src[Y * 2 - 1] * 4 + Src[Y * 2] * 6 + Src[Y * 2 + 1] * 4 + Src[Y * 2 + 2];
}在本例中,上述代码执行100次要50几毫秒,比前面的慢了,但是这里的组合确实是蛮有味道的,各种数据的灵活应用也是值得参考的。我反而更欣赏这段代码。
以上谈及的均是单通道的算法,如果是BGR 3个通道或者BGRA 4个通道的图像数据,情况就会复杂一些,但是同样的道理,可以使用shuffle来调整位置,然后使用类似的方式处理。
我们来谈谈浮点版本的高斯金字塔,这个再很多情况下也有需求,毕竟有很多算法是再浮点上进行处理的,那浮点版本的普通C的代码其实和C语言是差不多的,只需要将有关数据类型改为浮点就可以了,那对于其核心的DownSampleLine函数,也是我们优化的关键和难点,由于SSE一次性只能加载4个浮点数,如果还是和刚才处理字节数据那样,隔一个数取一个数,那么利用SSE一次性只能处理2个像素,而我们通过下面的美好的优化方式,一次性就能处理4个像素了,而且代码也很优美,我很是喜欢。
void IM_DownSampleLine32F(float *Src, float *Dest, int DstLen, int Channel)
{
// 只处理中间有效范围内的数,第一个和最后一个不处理
if (Channel == 1)
{
int ValidLen = DstLen - 2; // -2是因为第一和最后一个点的部分取样值是不在有效范围内的
int BlockSize = 4, Block = ValidLen / BlockSize;
// Src S0 S1 S2 S3 S4 S5 S6 S7 S8 S9 S10 S11 // 12个数据
// Dst D1 D2 D3 D4 // 有效位置的只有4个结果
// 1 4 6 4
__m128 Cof = _mm_setr_ps(1.0f, 4.0f, 6.0f, 4.0f);
for (int Y = 1; Y < Block * BlockSize + 1; Y += BlockSize)
{
// S0 S1 S2 S3
__m128 SrcV0 = _mm_loadu_ps(Src + (Y - 1) * 2);
// S4 S5 S6 S7
__m128 SrcV1 = _mm_loadu_ps(Src + (Y - 1) * 2 + 4);
// S8 S9 S10 S11
__m128 SrcV2 = _mm_loadu_ps(Src + (Y - 1) * 2 + 8); // 下一次加载时的SrcV0和本次的SrcV2时相同的,测试过用变量赋值,结果区别不大
// S0 S1 * 4 S2 * 6 S3 * 4
__m128 Sum0 = _mm_mul_ps(SrcV0, Cof);
// S2 S3 * 4 S4 * 6 S5 * 4
__m128 Sum1 = _mm_mul_ps(_mm_shuffle_ps(SrcV0, SrcV1, _MM_SHUFFLE(1, 0, 3, 2)), Cof);
// S4 S5 * 4 S6 * 6 S7 * 4
__m128 Sum2 = _mm_mul_ps(SrcV1, Cof);
// S6 S7 * 4 S8 * 6 S9 * 4
__m128 Sum3 = _mm_mul_ps(_mm_shuffle_ps(SrcV1, SrcV2, _MM_SHUFFLE(1, 0, 3, 2)), Cof);
// S0 + S1 * 4 + S2 * 6 + S3 * 4 S2 + S3 * 4 + S4 * 6 + S5 * 4 S4 + S5 * 4 + S6 * 6 + S7 * 4 S6 + S7 * 4 + S8 * 6 + S9 * 4
__m128 Dst = _mm_hadd_ps(_mm_hadd_ps(Sum0, Sum1), _mm_hadd_ps(Sum2, Sum3));
// S0 + S1 * 4 + S2 * 6 + S3 * 4 + S4 S2 + S3 * 4 + S4 * 6 + S5 * 4 + S6 S4 + S5 * 4 + S6 * 6 + S7 * 4 + S8 S6 + S7 * 4 + S8 * 6 + S9 * 4 + S10
Dst = _mm_add_ps(Dst, _mm_shuffle_ps(SrcV1, SrcV2, _MM_SHUFFLE(2, 0, 2, 0)));
_mm_storeu_ps(Dest + Y, Dst);
}
for (int Y = Block * BlockSize + 1; Y < DstLen - 1; Y++)
{
Dest[Y] = Src[Y * 2 - 2] + Src[Y * 2 - 1] * 4 + Src[Y * 2] * 6 + Src[Y * 2 + 1] * 4 + Src[Y * 2 + 2];
}
}
}具体的每句代码的意思根据我上面的注释应该很容易能弄懂的,我就不加解释了。
最后,我们来关注下边缘的处理,边缘部分由于取样时会超出图像边界,因此,需要做判断,一种合理的方式是采用镜像数据,此时可以保证权重一定是256,我做了一个简单的函数:
int IM_DownSamplePerPixel8U(unsigned char *Src, unsigned char *Dest, int SrcW, int SrcH, int StrideS, int DstW, int DstH, int StrideD, int Channel, int X, int Y)
{
if ((Channel != 1) && (Channel != 3) && (Channel != 4)) return IM_STATUS_NOTSUPPORTED;
if (X < 0 || X >= DstW || Y < 0 || Y >= DstH) return IM_STATUS_INVALIDPARAMETER;
int Sum, SumB, SumG, SumR, SumA;
const int Kernel[25] = {
1, 4, 6, 4, 1,
4, 16, 24, 16, 4,
6, 24, 36, 24, 6,
4, 16, 24, 16, 4,
1, 4, 6, 4, 1 }; // 高斯卷积核
Sum = SumB = SumG = SumR = SumA = 128; // 128是用于四舍五入的
for (int J = -2; J <= 2; J++)
{
int YY = IM_GetMirrorPos_Ex(SrcH, Y * 2 + J); // YY = Clamp(Y * 2 + J, 0, SrcH - 1); 在上一级中的Y坐标要乘以2, 使用Clamp速度会稍微慢一点
for (int I = -2; I <= 2; I++)
{
int Weight = Kernel[(J + 2) * 5 + (I + 2)]; // 严格的按照卷积公式进行计算,没必要用中间变量去优化他了
int XX = IM_GetMirrorPos_Ex(SrcW, X * 2 + I); // XX = Clamp(X * 2 + I, 0, SrcW - 1); 用EX这个版本的保证边缘的部分不会有重复的像素,不然取样就不对了
unsigned char *Sample = Src + YY * StrideS + XX * Channel;
if (Channel == 1)
{
Sum += Sample[0] * Weight;
}
else if (Channel == 3)
{
}
else if (Channel == 4)
{
}
}
}
int Index = Y * StrideD + X * Channel;
if (Channel == 1)
{
Dest[Index] = Sum >> 8;
}
else if (Channel == 3)
{
}
else if (Channel == 4)
{
}
return IM_STATUS_OK;
}为了程序完整,我们最后再加上周边像素的处理,然而我们发现一个严重的问题,再没有处理四周的函数中,我们运行100次SSE的耗时大约是45ms,一旦加入边缘像素的处理,这个耗时我们发现75ms,而普通C语言版本里由原来的260ms变为290ms,我们可能感受不到大的区别,但SSE的优化后,边缘部分居然占用了40%的耗时,因此,此时边缘特殊像素的处理就成了核心的事情了。
一种可行的优化方式就是类似于我前面做的Sobel边缘检测时方式,先对数据进行扩展,然后对扩展后的数据进行处理,此时边缘部分的处理已经被包括到SSE里去了,我尚未实践此方案的可行性和速度效果,相信应该不成问题。
附本文相关工程代码供参考:https://files.cnblogs.com/files/Imageshop/GaussPyramid.rar

原文出处:https://www.cnblogs.com/Imageshop/p/10263676.html
来源:oschina
链接:https://my.oschina.net/u/4302665/blog/3271075