一、为什么要使用消息队列?
1、 削峰
当有大并发产生的时候,数据会堆积在MQ中,消费端保持平稳的消费能力,不会给后端服务造成太大压力;
2、解耦
传统模式: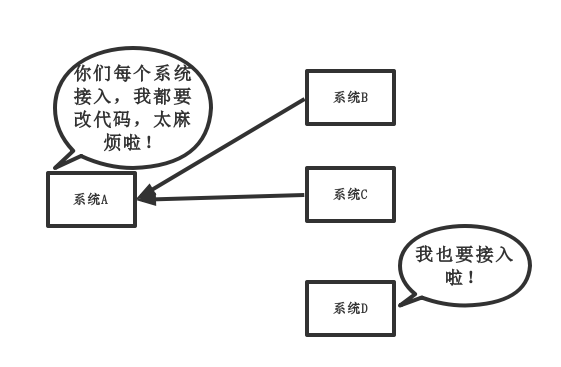
传统模式的缺点:
- 系统间耦合性太强,如上图所示,系统A在代码中直接调用系统B和系统C的代码,如果将来D系统接入,系统A还需要修改代码,过于麻烦!
中间件模式: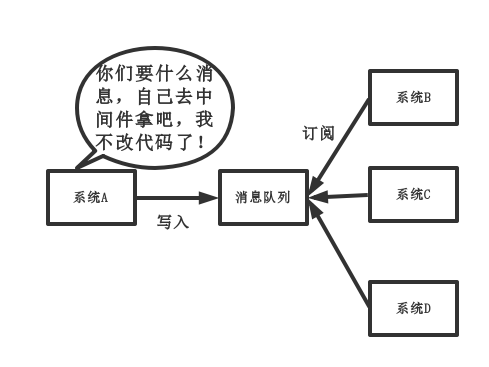
中间件模式的的优点:
- 将消息写入消息队列,需要消息的系统自己从消息队列中订阅,从而系统A不需要做任何修改。
3、异步
异步可以大大提高响应的速度;
二、使用消息队列的缺点?
1、一定程度上降低了系统的可用性
在不使用第三方组件的情况下,只有部署服务的机器挂了,进程才会出问题;
但是使用第三方消息队列,增加了一种宕机的可能,就是消息队列服务挂了也会导致进程出问题;
2、系统复杂性增加
- 代码复杂:需要引入第三方服务相关代码;本来只是一个方法调用而已。
- 需要考虑消息队列服务的一些问题, 如何保证消息不被重复消费?如何保证保证消息可靠传输?
三、消息队列的选型
来一个对比表:
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | kafka |
|---|---|---|---|---|
| 开发语言 | java | erlang | java | scala |
| 单机吞吐量 | 万级 | 万级 | 10万级 | 10万级 |
| 时效性 | ms级 | us级 | ms级 | ms级以内 |
| 可用性 | 高(主从架构) | 高(主从架构) | 非常高(分布式架构) | 非常高(分布式架构) |
| 功能特性 | 成熟的产品,在很多公司得到应用;有较多的文档;各种协议支持较好 | 基于erlang开发,所以并发能力很强,性能极其好,延时很低;管理界面较丰富 | MQ功能比较完备,扩展性佳 | 只支持主要的MQ功能,像一些消息查询,消息回溯等功能没有提供,毕竟是为大数据准备的,在大数据领域应用广。 |
综合上面的材料得出以下两点:
(1)中小型软件公司,建议选RabbitMQ.一方面,erlang语言天生具备高并发的特性,而且他的管理界面用起来十分方便。正所谓,成也萧何,败也萧何!他的弊端也在这里,虽然RabbitMQ是开源的,然而国内有几个能定制化开发erlang的程序员呢?所幸,RabbitMQ的社区十分活跃,可以解决开发过程中遇到的bug,这点对于中小型公司来说十分重要。不考虑rocketmq和kafka的原因是,一方面中小型软件公司不如互联网公司,数据量没那么大,选消息中间件,应首选功能比较完备的,所以kafka排除。不考虑rocketmq的原因是,rocketmq是阿里出品,如果阿里放弃维护rocketmq,中小型公司一般抽不出人来进行rocketmq的定制化开发,因此不推荐。
(2)大型软件公司,根据具体使用在rocketMq和kafka之间二选一。一方面,大型软件公司,具备足够的资金搭建分布式环境,也具备足够大的数据量。针对rocketMQ,大型软件公司也可以抽出人手对rocketMQ进行定制化开发,毕竟国内有能力改JAVA源码的人,还是相当多的。至于kafka,根据业务场景选择,如果有日志采集功能,肯定是首选kafka了。具体该选哪个,看使用场景。
四、各个消息队列是如何保证高可用的?
Kafka
是通过Zookeeper结合Kafka的replica机制实现的高可用。
Kafka的每个partition会有多个replica,并且Kafka会均匀的将一个partition的所有replica分布在不同的机器上。
当一台broker挂掉的时候,首先数据不会丢失,另外,Zookeeper会利用ZAB协议在replica中选举出一个leader出来,所以服务也不太会受影响;
RocketMQ
ActiveMQ
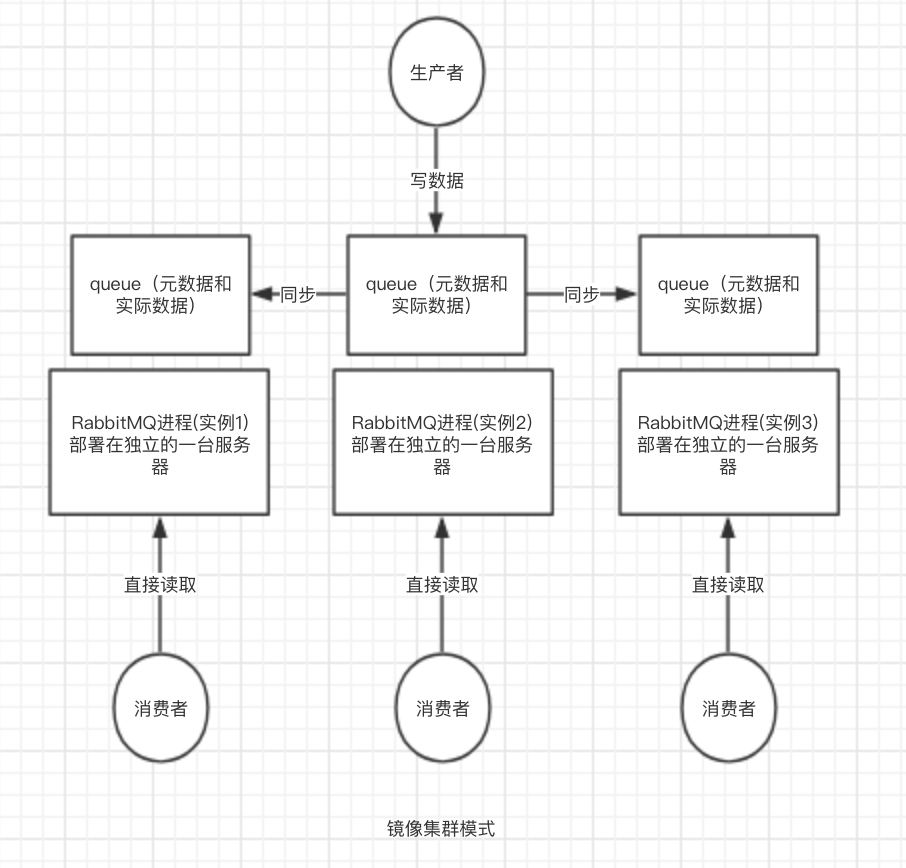
RabbitMQ
Master-slave主从同步
参考:
来源:oschina
链接:https://my.oschina.net/weiweiblog/blog/4470220