懒人区:想直接安装的可以点这个链接。
---------------------------------分割线---------------
缘由:
在官方的Paddle-Inference-Demo中,建议Paddle版本>=1.7。
而个人能找到的资源最高的版本是Nvidia论坛的1.6.3版本的paddlepaddle-gpu。以及文档中提供的0.0.0版本(链接)。https://forums.developer.nvidia.com/t/paddlepadd-gpu-1-6-3-for-jetson-nano-now-available/111655
在跑Demo的过程中,发现文档中给出的版本没有Paddle-TensorRT的功能,虽然可以使用GPU加速。但是总感觉有TensorRT但却用不上很膈应。
另外,Nvidia论坛放出的版本虽然支持TensorRT,但是版本低于Paddle-Inference-Demo要求的1.7以上。在查阅1.6和1.7的文档后,发现API有很大的不同。
我根据1.6.3支持的API对yolov3的demo修改后,**发现推理的结果有很大出入。**参见我在Github提的issue。当然,在运行过程中也会报model和lib版本不一致的错误。*推测是不同版本支持的算子可能不一样(或者实现)? *
而且,已有能搜到的教程完全没有提及TensorRT的功能如何添加,我来填坑
在Jetson 上编译Paddle(带TensorRT):
1. Jetson nano环境
JetPack4.3
Found Paddle host system: ubuntu, version: 18.04.3
-- Found Paddle host system's CPU: 4 cores
-- CXX compiler: /usr/bin/c++, version: GNU 7.5.0
-- C compiler: /usr/bin/cc, version: GNU 7.5.0
2. 编译前的准备
安装所需的依赖:
sudo pip install virtualenv
sudo apt-get install python3.6-dev liblapack-dev gfortran libfreetype6-dev libpng-dev libjpeg-dev zlib1g-dev patchelf python3-opencv
对nano的设置
sudo nvpmodel -m 0 && sudo jetson_clocks #打开性能模式
#增加swap空间,防止爆内存
swapoff -a
sudo fallocate -l 15G /swapfile
sudo chmod 600 /var/swapfile
sudo mkswap /swapfile
sudo swapon /swapfile
swapon -a
sudo swapon --show#用来查看结果
ulimit -n 2048 #最大的文件打开数量
上方的设置一定要打开,swap空间的大小可以根据自己存储卡的大小设置,建议8G及以上。 (稳妥一点,我用6G的时候爆过)
更改文件:在NvInferRuntime.h中Class IPluginFactory里添加虚析构函数。如果还有报没有virtual的析构函数时改法是一致的。
virtual ~IPluginFactory() {}
3. 编译流程
首先克隆Paddle的Github(慢的自己想办法 )。
git clone https://github.com/paddlepaddle/paddle
查看可用的版本:
git tag
切换版本:
git checkout v2.0.0-alpha0 #我使用的是2.0.0,因为不是稳定版,名称不同
安装NCCL
git clone https://github.com/NVIDIA/nccl.git
make -j4
make install
建立虚拟python环境
这里有些说法:因为JetPack4.3的nano自带相应的cv2模块,不需要安装,只需要链接即可。因此我使用的是可以找到文件夹的方式去创建虚拟环境:
python3 -m venv name-of-env #在一个你可以记住的位置创建
链接cv2模块: 部分内容需要修改
ln -s /usr/lib/python3.6/dist-packages/cv2/python-3.6/cv2.cpython-36m-aarch64-linux-gnu.so(本机cv2) path-to-venv/name-of-venv/lib/python3.6/site-packages/cv2.so
使TensorRT对虚拟环境python可见
参见下方链接:https://docs.donkeycar.com/guide/robot_sbc/tensorrt_jetson_nano/
(注意你需要做的包括使CUDA、TensorRT都设为环境变量)
进入虚拟环境并测试cv2
source pd_env/bin/activate
#test cv2 in the following lines
...
安装必要的包:
包括cython、wheel、numpy(版本啥的目前我没遇到不兼容的)
进入克隆的Paddle,安装依赖:
cd Paddle
#安装运行Python Paddle需要的依赖(numpy,scipy etc)
#此处安装会比较慢
pip install -r python/requirements.txt
Cmake设置:
这里需要说明以下:Paddle的编译中如果使用TensorRT的话需要按照要求把库整理成一定的格式(打包的方式我再写一篇博客),并且添加环境变量。在编译子图功能的时候会用到。当然也可以修改cmake文件夹中的tensorrt.cmake,但不保证一定能成。(我试过,但最后用的是建议的方式,见issue。**稳妥点的方法是适应源代码的配置修改本地配置。**整理成如下格式。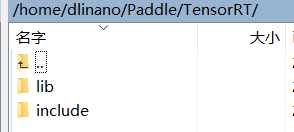
mkdir build
cd build/
其他配置可以看文档:链接
cmake .. \
-DWITH_CONTRIB=OFF \
-DWITH_MKL=OFF \
-DWITH_MKLDNN=OFF \
-DWITH_TESTING=OFF \
-DCMAKE_BUILD_TYPE=Release \
-DON_INFER=ON \
-DWITH_PYTHON=ON \
-DWITH_XBYAK=OFF \
-DWITH_NV_JETSON=ON \
-DPY_VERSION=3.6 \
-DTENSORRT_ROOT=/home/dlinano/Paddle/TensorRT \
-DCUDA_ARCH_NAME=Auto
开始编译:
make -j4
# 生成预测lib,生成fluid_inference_install_dir 即C++预测库目录
make inference_lib_dist
4. 安装paddlepaddle-gpu
# 安装python 库
pip install -U python/dist/*.whl #还是在build文件夹
5.跑通Demo
详情请见Paddle-Inference-Demo的GitHub,不抢别人的饭碗了 链接
效果:有兴趣的可以测测快了多少
中间使用到TRT的优化部分非常慢,请耐心等待。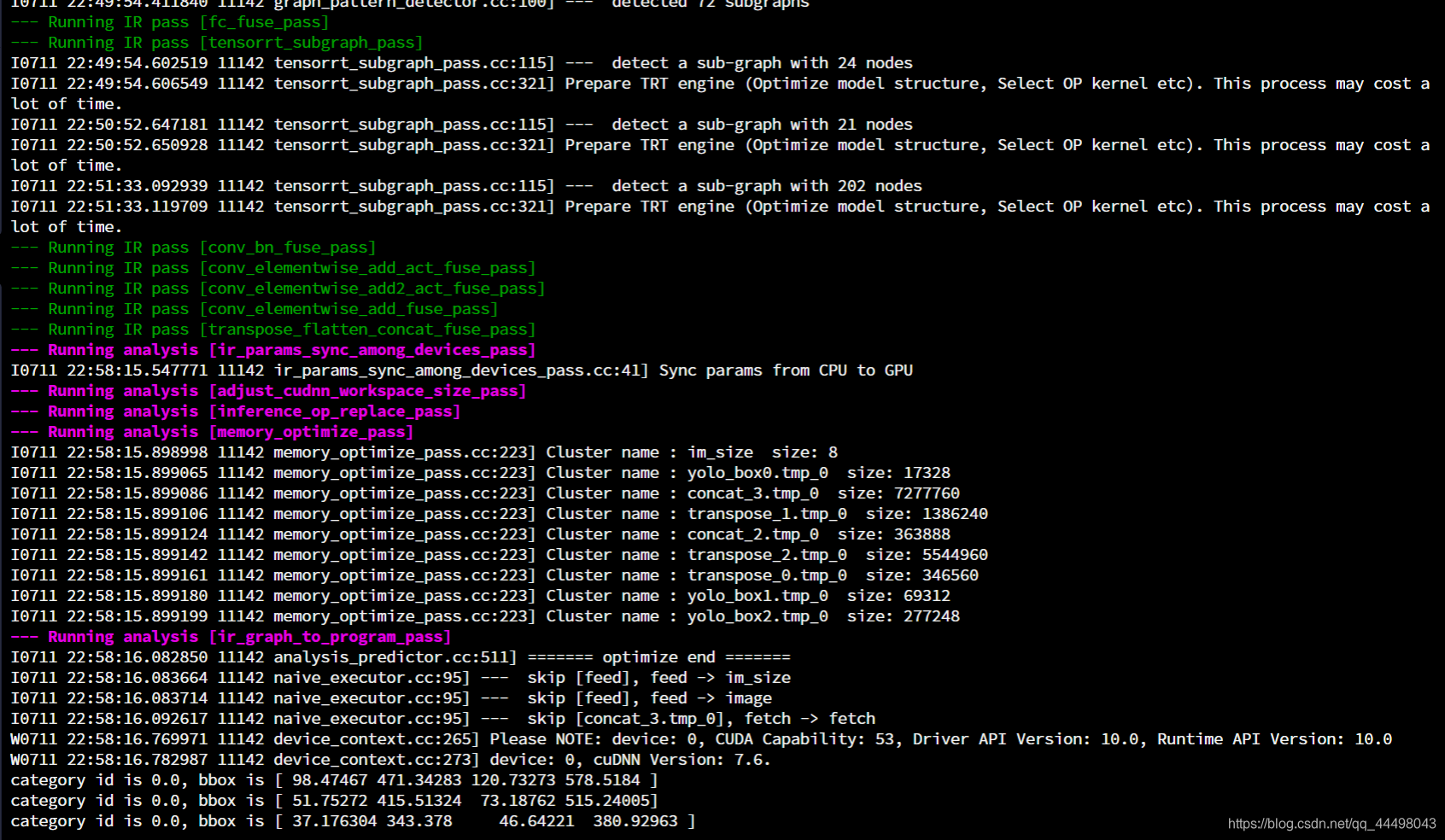
Trouble Shooting
1.缺少虚析构函数的问题(上面已经提及)
2.编译中没有错误提示挂了
paddle/fluid/operators/CMakeFiles/edit_distance_op.dir/edit_distance_op_generated_edit_distance_op.cu.o
nvcc error : 'cicc' died due to signal 9 (Kill signal)
问题在于swap区不够,内存爆了。
3.Too many files
这个问题上面的设置中提到过,需要开启最大能打开的文件数。
To be continued.
References:
https://www.jianshu.com/p/a352f538e4a1
https://paddle-inference.readthedocs.io/en/latest/user_guides/source_compile.html
https://www.paddlepaddle.org.cn/documentation/docs/zh/advanced_guide/inference_deployment/inference/build_and_install_lib_cn.html
https://paddle-inference.readthedocs.io/en/latest/optimize/paddle_trt.html
https://github.com/PaddlePaddle/Paddle-Inference-Demo/tree/master/python/yolov3
最后感谢Paddle技术人员在Github及时回答问题。
来源:oschina
链接:https://my.oschina.net/u/4375893/blog/4369069