本文来源于公众号【胖滚猪学编程】,转载请注明出处!
关于数据中台的概念和架构,我们在大白话 六问数据中台和数据中台全景架构及模块解析!一文入门中台架构师!两篇文章中都说明白了。从这一篇文章开始分享中台落地实战。
其实无论是数据中台还是数据平台,数据无疑都是核心中的核心,所以闭着眼睛想都知道数据汇聚是数据中台/平台的入口。纵观众多中台架构图,数据采集与汇聚都是打头阵的:
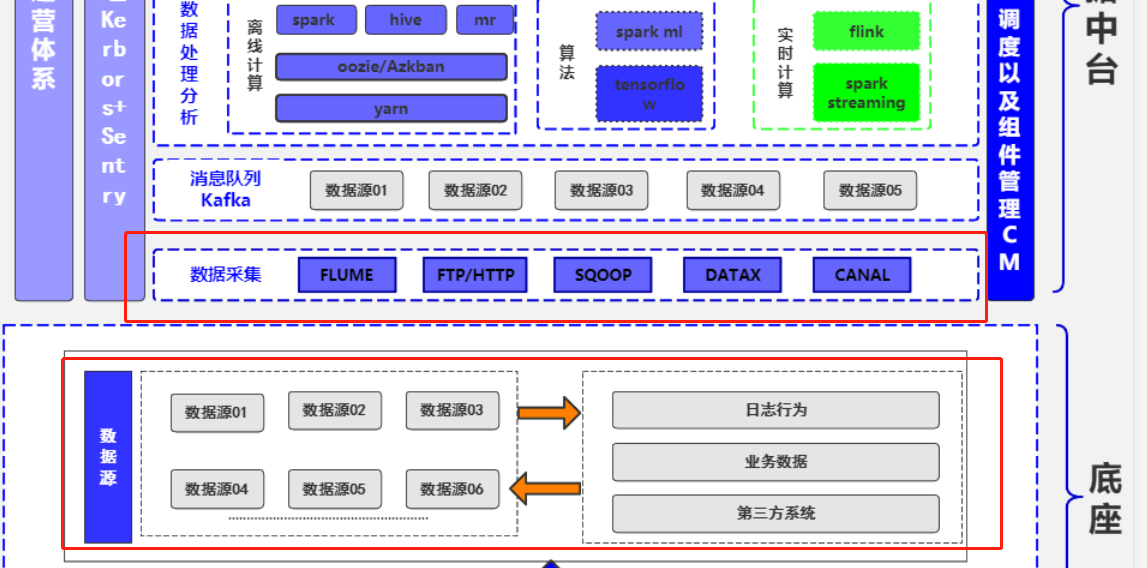
本文将从以下几个方面分享数据采集的方方面面:
一、企业数据来源 二、数据采集概念和价值 三、数据采集常用工具 四、数据采集系统设计原则 五、数据采集模块生产落地分享
有来源才能谈采集,因此我们先来归纳下企业中数据来源。
数据来源
企业中的数据来源极其多,但大都都离不开这几个方面:数据库,日志,前端埋点,爬虫系统等。
-
数据库我们不用多说,例如通常用mysql作为业务库,存储业务一些关键指标,比如用户信息、订单信息。也会用到一些Nosql数据库,一般用于存储一些不那么重要的数据。
-
日志也是重要数据来源,因为日志记录了程序各种执行情况,其中也包括用户的业务处理轨迹,根据日志我们可以分析出程序的异常情况,也可以统计关键业务指标比如PV,UV。
-
前端埋点同样是非常重要的来源,用户很多前端请求并不会产生后端请求,比如点击,但这些对分析用户行为具有重要的价值,例如分析用户流失率,是在哪个界面,哪个环节用户流失了,这都要靠埋点数据。
-
爬虫系统大家应该也不陌生了,虽然现在很多企业都声明禁止爬虫,但往往禁止爬取的数据才是有价值的数据,有些管理和决策就是需要竞争对手的数据作为对比,而这些数据就可以通过爬虫获取。
数据采集与抽取
刚刚说了这么多数据,可是它们分散在不同的网络环境和存储平台中,另外不同的项目组可能还要重复去收集同样的数据,因此数据难以利用,难以复用、难以产生价值。数据汇聚就是使得各种异构网络、异构数据源的数据,方便统一采集到数据中台进行集中存储,为后续的加工建模做准备。
-
数据汇聚可以是实时接入,比如Flume实时采集日志,比如Canal实时采集mysql的binlog。
-
也可以是**离线同步,**比如使用sqoop离线同步mysql数据到hive,使用DataX将mongo数据同步到hive。
技术选型
数据采集常用框架有Flume、Sqoop、LogStash、DataX、Canal,还有一些不算很主流但同样可以考虑的工具如WaterDrop、MaxWell。这些工具的使用都非常简单,学习成本较低。只不过实际使用中可能会有一些细节问题。但是总体来说难度不大。
所以重点还是应该了解每种工具的适用范围和优缺点。然后想清楚自己的需求是什么,实时还是离线?从哪种数据源同步到哪里?需要经过怎么样的处理?
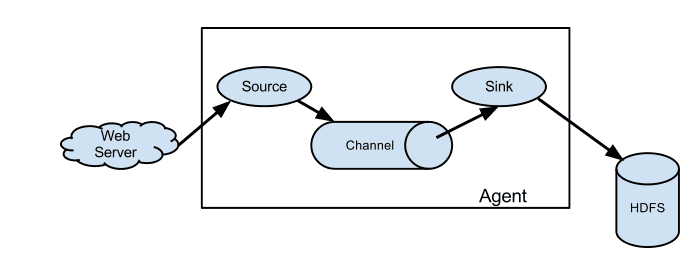
Flume
Flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。 Flume可以采集文件,socket数据包等各种形式源数据,又可以将采集到的数据输出到HDFS、hbase、hive、kafka等众多外部存储系统中。
Logstash
Logstash 即大名鼎鼎的ELK中的L。Logstash最常用于ELK(elasticsearch + logstash + kibane)中作为日志收集器使用
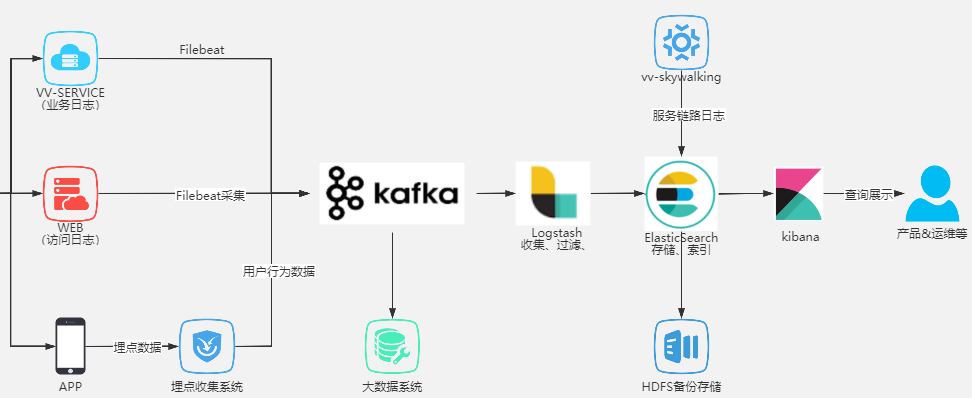
Logstash主要组成如下:
- inpust:必须,负责产生事件(Inputs generate events),常用:File、syslog、redis、beats(如:Filebeats)
- filters:可选,负责数据处理与转换(filters modify them),常用:grok、mutate、drop、clone、geoip
- outpus:必须,负责数据输出(outputs ship them elsewhere),常用:elasticsearch、file、graphite、statsd
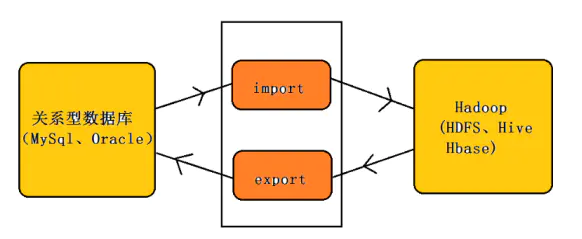
Sqoop
Sqoop主要用于在Hadoop(HDFS、Hive、HBase)与传统的数据库(mysql、postgresql…)间进行数据的传递,可以将一个关系型数据库中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
Datax
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS 等各种异构数据源之间高效的数据同步功能。
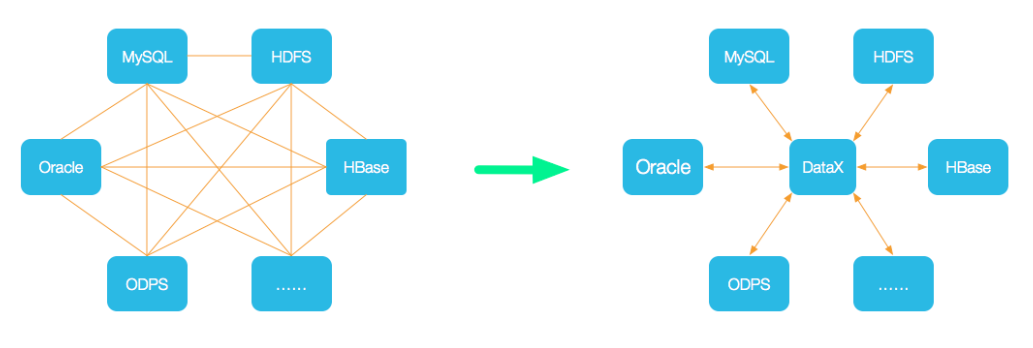
所支持的数据源如下,也可自行开发插件:
| 类型 | 数据源 | Reader(读) | Writer(写) | 文档 |
|---|---|---|---|---|
| RDBMS 关系型数据库 | MySQL | √ | √ | 读 、写 |
| Oracle | √ | √ | 读 、写 | |
| SQLServer | √ | √ | 读 、写 | |
| PostgreSQL | √ | √ | 读 、写 | |
| DRDS | √ | √ | 读 、写 | |
| 通用RDBMS(支持所有关系型数据库) | √ | √ | 读 、写 | |
| NoSQL数据存储 | OTS | √ | √ | 读 、写 |
| Hbase0.94 | √ | √ | 读 、写 | |
| Hbase1.1 | √ | √ | 读 、写 | |
| Phoenix4.x | √ | √ | 读 、写 | |
| Phoenix5.x | √ | √ | 读 、写 | |
| MongoDB | √ | √ | 读 、写 | |
| Hive | √ | √ | 读 、写 | |
| Cassandra | √ | √ | 读 、写 | |
| 无结构化数据存储 | TxtFile | √ | √ | 读 、写 |
| FTP | √ | √ | 读 、写 | |
| HDFS | √ | √ | 读 、写 | |
| Elasticsearch | √ | 写 | ||
| 时间序列数据库 | OpenTSDB | √ | 读 | |
| TSDB | √ | √ | 读 、写 |
Canal
canal 主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费

怎么用呢?启动canal-server 连上MySQL,再使用canal-client连接canal-server接收数据变更消息,拿到对应表和变更数据之后自行触发对应业务逻辑。更通用的是使用canal把数据变更直接投递到消息队列,使用消息队列消费者来处理逻辑,另外还支持canal落地到ES等地方。图中已经很详细了!
由于篇幅问题,本文不对这些工具做详细对比,想知道它们的优缺点吗?想知道该如何选型吗?去公众号【胖滚猪学编程】找答案吧!
数据落地
采集之后必然需要将数据落地,即存储层,常见的有:
- MYSQL、Oracle
- Hive、Hdfs
- HBase
- Redis
- ElasticSearch
- Tidb
- Mongo
学习Hive、HBase、ElasticSearch、Redis、请关注公众号【胖滚猪学编程】吧!
需要说明的是,数据采集之后往往会先发送给Kafka这种消息队列,然后才真正落地到各种存储层中。
数据汇聚设计原则
从中台的角度来考虑,笔者认为,数据汇聚层的设计需要考虑几个关键的因素:
-
设计之初就应该考虑支持各类数据源 ,支持不同来源、不同类型的数据源。数据汇聚层不是为某一种数据而生的,应该做到通用化。
-
需要支持不同时间窗口的数据采集,实时的、非实时的、历史的。
-
操作友好简单,即使是不懂技术的人,也可以方便的操作,进行数据同步;举例mysql同步到hive,你不应该让用户去填写复杂的sqoop任务参数,而是只需要选择源表和目的表,其他事情都交给中台去完成。
-
合理选择存储层,不同数据源应存储在不同的地方,比如日志数据肯定不适合mysql。
本文来源于公众号【胖滚猪学编程】,转载请注明出处!
生产落地分享
笔者马上要开始分享公司真实落地案例了!网上文章千篇一律,极少数会有实战落地分享!也欢迎各位大佬指教!
首先刚刚说到设计原则,应该考虑支持各类数据源 各类落地,应该分别考虑离线和实时采集、应该要操作友好简单,不懂技术也可操作。我们整体的设计也是以这几个原则作为指导的。想分别从离线和实时采集方面介绍一下公司落地方案:
离线采集
离线同步方面、在我司主要是会采集抽取如下图所示的几个数据源数据,最终落地到HIVE或者TIDB,落地到HIVE的作用我就不多说了,大家都比较熟悉。而落地到TIDB主要是支持实时查询、实时业务分析以及各类定时跑批报表。
下面通过mysql自助化同步到hive为例,分享自助化离线数据采集模块的系统设计。
首先通过数据中台源数据管理模块,将数据源的信息一一展示出来,用户按需勾选同步:
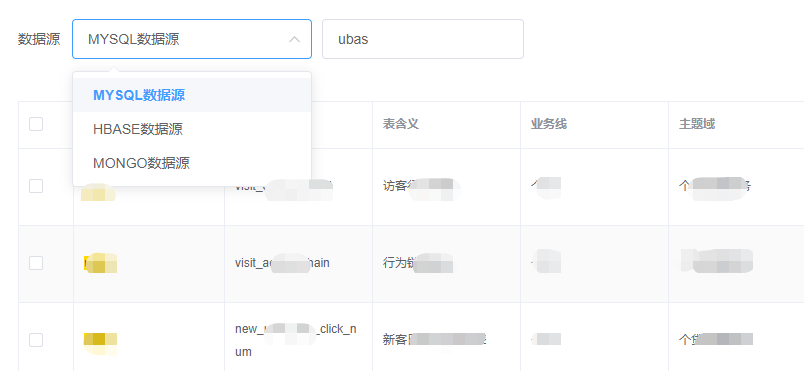
同步支持全量同步以及增量同步,支持附加配置,比如脱敏、加密、解密等。由于需要规范数仓表名、因此目的表名由系统自动生成,比如mysql同步到hive统一前缀ods_(后续在数仓规范中会详细说明,敬请关注公众号【胖滚猪学编程】)
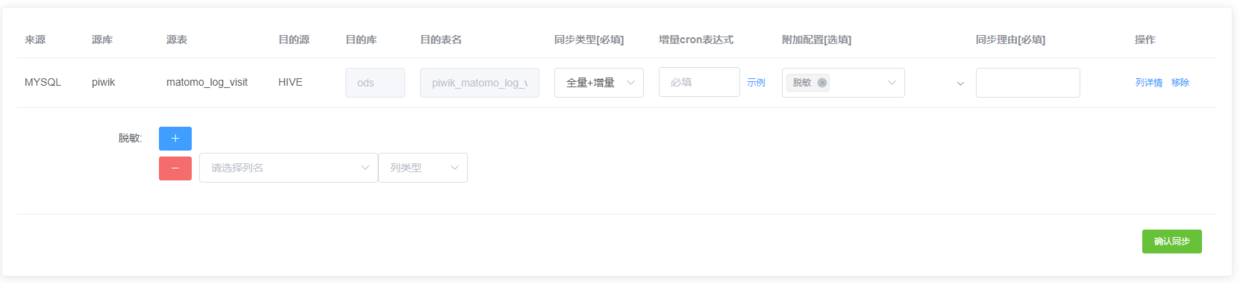
用户点击确认同步之后,首先会经过元数据管理系统,从元数据管理系统中查询出同步任务所需要的元信息(包括ip,端口,账户密码,列信息),组装成sqoop参数,将同步信息(包括申请人、申请理由、同步参数等信息)记录到mysql表中。然后调用工单系统经过上级领导审核。
工单系统审核后发消息给到mq,通过mq可实时获取到工单审核状态,如果审核通过,则在调度系统(基于EasyScheduler)自动生成任务,早期我司选择Azkaban,后来发现EasyScheduler多方面都完胜Azkaban,尤其在易用性、UI、监控方面。
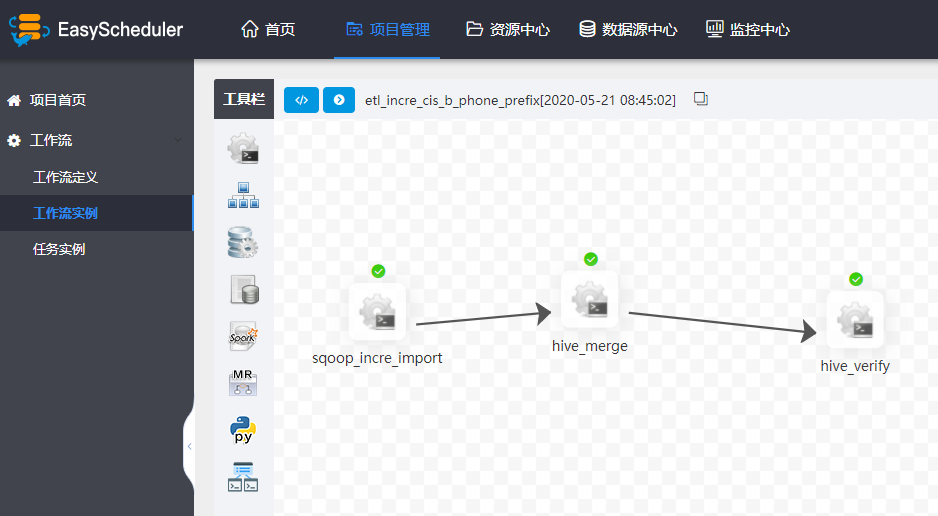
从图中可知mysql同步到hive涉及三个流程节点,以user表增量同步为例,第一步是通过sqoop任务将mysql数据同步到hive的ods_user_tmp表,第二步是将ods_user_tmp的数据merge到ods_user中(覆盖原有分区),第三步是做数据检验。
除了mysql同步到hive,其他数据源的同步也大同小异,关键是定义好流程模板(通常是shell脚本)和流程依赖,然后利用调度系统进行调度。
实时采集
实时采集模块,我司是基于Flink实时计算平台,具有如下特性:
- 支持多种数据源:Kafka、RocketMq、Hive等
- 支持多种落地:Kafka、JDBC、HDFS、ElasticSearch、RocketMq、HIVE等
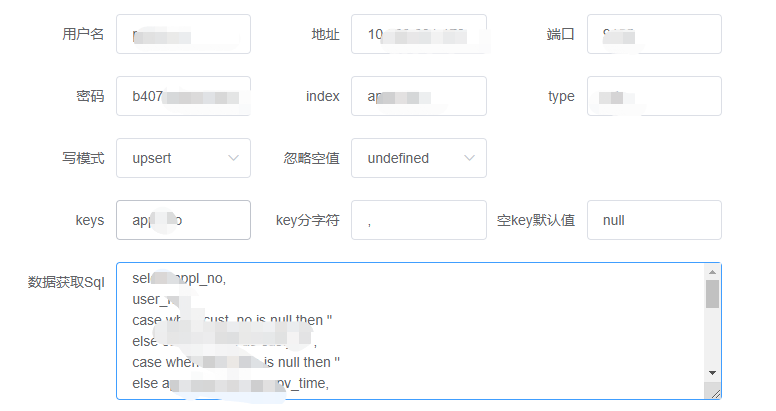
- 通用sql处理:数据处理直接配置一条sql即可
- 告警策略:支持多种告警策略,如流计算堆积batch的监测、应用的启动退出等。
在设计原则上,也充分考虑了扩展性、易用性,source、process、sink\dim(维表)均为插件化开发,方面后续扩展,界面化配置,自动生成DAG图,使得不懂技术的人也可以很快上手进行流计算任务开发:
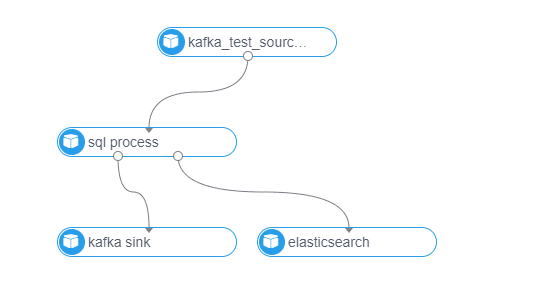
由于篇幅问题,细节问题不能一一说清,本人将在公众号【胖滚猪学编程】持续分享,欢迎关注。

本文来源于公众号【胖滚猪学编程】一个集颜值与才华于一身的女程序媛。以漫画形式让编程so easy and interesting。
来源:oschina
链接:https://my.oschina.net/u/3780452/blog/4286701