CHANGLOG
- 4/10/2020,展开背景介绍和方法、优化内容组织。
前言
2019年末的时候在工作中开始尝试使用机器阅读理解做信息抽取,通过调研发现多答案抽取领域一直鲜有人问津。不过伴随DROP的横空出世,也出现了2篇关于multi-span extraction的研究,在此分享下调研成果。
目录
- 背景介绍
- 任务定义
- 方法
- 总结
1. 背景介绍
机器阅读理解(Machine Reading Comprehension,MRC)因其开放性和交互性已成为NLP领域炙手可热的方向,头部企业及高校如Google、Facebook、斯坦福等纷纷下场厮杀,在众多相关比赛如SQuAD上达到或超越人类水平。

 SQuAD Leaderboard
SQuAD Leaderboard
尽管如此,现有的MRC处理现实场景下的QA问题依旧能力不足。原因有三:
- 现有的方法大多基于自然语言模型将问题和文档直接结合起来作为模型的输入,但由于模型一次能接受的文字输入长度有限,这么做往往会造成模型聚焦于从短段落中提取答案,而不是通过阅读整个内容页面找到合适的上下文,最后导致预测的答案并不能够很好的反映问题。
- 现有的中文机器阅读理解模型大多假设文档中一定有能回答问题的答案,而没有考虑如何处理无答案问题的情况,这样会导致模型的预测有所偏差。
- 现有的机器阅读理解模型大多假设文档中最多只有一个答案能回答问题,而没有考虑如何处理有多个答案问题的情况,这样会导致模型的预测结果有所遗漏。
MRC在业务场景上应用的难点主要有4点:
- 在垂直领域MRC标注数据较少的条件下,如何尽可能的提高模型效果。
- 在篇章长度不确定的情况下,如何设计通用的分段策略以降低错误预测答案的总体风险。
- 如何回答在文档中没有答案的问题。
- 如何回答在文档中有多个答案的问题。
不久前,新一代QA比赛DROP吸引了众多目光,其要求模型对上下文段落进行离散推理得到不同类型的最终答案。
2. 任务定义
机器阅读理解(Machine Reading Comprehension, MRC)任务主要是指让机器根据给定的文本回答与文本相关的问题,以此来衡量机器对自然语言的理解能力。
研究[1]归纳了四种广义的机器阅读理解任务:
- 完形填空
- 定义:给定文章 ,将其中的一个词或者实体 隐去作为待填空的问题,完形填空任务要求通过最大化条件概率 来利用正确的词或实体 进行填空。
- 数据集:CNN & Daily Mail、CBT、LAMBADA、Who-did-What、CLOTH、CliCR
- 多项选择
- 定义:给定文章 、问题和一系列候选答案集合,多项选择任务通过最大化条件概率来从候选答案集合 中挑选出正确答案回答问题 。
- 数据集:MCTest、RACE
- 片段抽取
- 定义:给定文章 (其中包含 n 个词)和问题 ,片段抽取任务通过最大化条件概率 来从文章中抽取连续的子序列作为问题的正确答案。
- 数据集:SQuAD、NewsQA、TriviaQA、DuoRC
- 自由作答
- 定义:给定文章 和问题 ,自由作答的正确答案 有时可能不是文章 的子序列,即 或 。自由作答任务通过最大化条件概率 来预测回答问题 的正确答案 。
- 数据集:bAbI、MS MARCO、SearchQA、NarrativeQA、DuReader
本文介绍的方法主要解决的是片段抽取任务中的多答案问题。
3. 方法
3.1 A Multi-Type Multi-Span Network for Reading Comprehension that Requires Discrete Reasoning (Hu et al., 2019)[2]
这篇文章是第一篇研究Multi-span extraction的paper。
3.1.1 模型
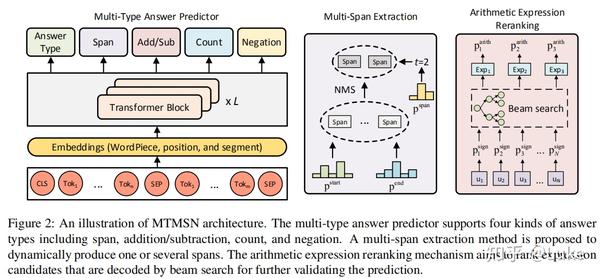 MTMSN模型架构
MTMSN模型架构
本文通过增加一个预测answer span的数目的分类子任务,结合non-maximum suppression (NMS) 算法,得到置信度最高且互不重叠的 个answer span。
具体思路如下图:
 MTMSN多答案抽取伪代码
MTMSN多答案抽取伪代码
3.1.2 实验
- Performance breakdown
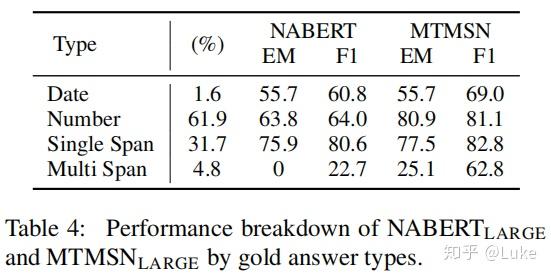 MTMSN Performance Breakdown
MTMSN Performance Breakdown
如上图所示,MTMSN与只能找到单个answer span的baseline NABERT相比,在mutli span类型的问题上的F1提升了超过40个点,EM也有超过25个点的提升,几乎是从0到1的重大突破。
- Effect of maximum number of spans
为了确定span数目分类子任务的最优类别数,作者在DROP的dev数据上调参,结果表明,将span数目建模成8分类任务的效果最佳。
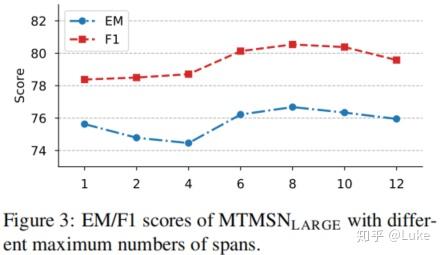 Effect of maximum number of spans
Effect of maximum number of spans
3.1.3 利弊
- 优点
- 继承并扩展了当前主流阅读理解模型的思路,更易于实现
- 缺点
- 引入了一个额外的span数目预测子任务,可能会造成更大的传递误差
3.2 Tag-based Multi-Span Extraction in Reading Comprehension (Efrat et al., 2019) [3]
本文富有创意地的结合了MRC和NER两种任务的思路处理多答案抽取,后续DROP的top solution大多延续了本文的思路。
3.2.1 多答案抽取基本思路
和single-span MRC的pointer network方法不同,本文将multi-span问题转化成序列标注任务。具体而言,对于:
- 预处理
对于multi-span answer span集合,使用BIO格式对输入文本序列打上标签, 其中用B标记answer span的开始,answer span标记片段的中间,O标记不属于答案片段的token。
- 模型结构
设计多输出head结构进行multi-task learning,E.g. answer type head + single-span head + multi-span head。
- 训练
优化所有输出head子任务的联合loss。
- 预测
有如下3种方法可以找到最可能的答案序列:
- Viterbi Decoding,NER的经典解码方法。优点是基于概率转移矩阵,能找到全局最优序列,缺点是计算代价高昂。
- Beam Search(文中采纳),保留top-k个预测结果,去除掉错误的序列。优点是在性能和精度之间取得了平衡,缺点是可能只找到局部最优。关于Beam Search技术,可以参考文章:十分钟读懂Beam Search 1:基础 @不刷知乎
- Greedy Tagging,直接拼接每个token上的预测标签作为最终的预测结果序列。优点是计算代价最小,缺点是容易陷入局部最优。
3.2.2 实验
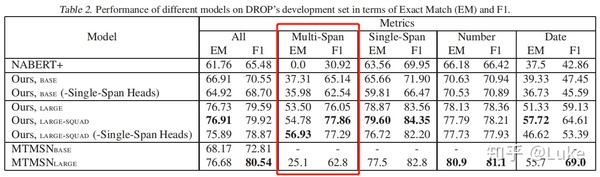 Tag_mspan Performance
Tag_mspan Performance
如上图所示,Tag-based Multi-Span Extraction与MTMSN相比,在mutli span类型的问题上的F1提升了超过15个点,EM也有超过31个点的提升,提升巨大。
3.2.3 利弊
- 优点
- 利用序列标注任务的特性,一个任务同时考虑预测答案及答案数目
- 缺点
- 可能会预测出过多的答案
4. 总结
在以往的机器阅读理解方案中,用户往往被要求将一个可能包含多答案的问题拆分成多个单答案问题,就实际使用体验而言确实谈不上好。而今,随着NLP技术的不断突破,学术界的目光也开始投向multi-span extraction的方向,这无疑是机器阅读理解技术落地的一大福音。
博主写文不易,如果觉得本文有所帮助请点个赞^_^,更多精彩内容欢迎关注公众号【AI充电站】。
参考
- ^Liu, Shanshan, et al. "Neural Machine Reading Comprehension: Methods and Trends."Applied Sciences9.18 (2019): 3698. https://arxiv.org/abs/1907.01118
- ^Hu, Minghao, et al. "A Multi-Type Multi-Span Network for Reading Comprehension that Requires Discrete Reasoning."arXiv preprint arXiv:1908.05514(2019). https://www.aclweb.org/anthology/D19-1170/
- ^Efrat, Avia, Elad Segal, and Mor Shoham. "Tag-based Multi-Span Extraction in Reading Comprehension."arXiv preprint arXiv:1909.13375(2019) https://arxiv.org/abs/1909.13375
来源:oschina
链接:https://my.oschina.net/u/4275752/blog/4259316