制作类似pascal voc格式的目标检测数据集:https://www.cnblogs.com/xiximayou/p/12546061.html
代码来源:https://github.com/amdegroot/ssd.pytorch
拷贝下来的代码好多坑要踩。。。
我将其上传到谷歌colab上,当前目录结构如下:
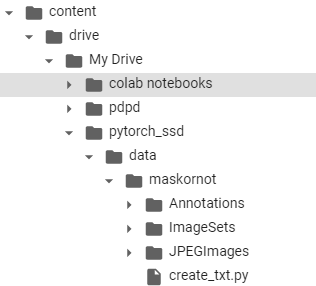


需要说明的是,虽然我们只有2类,但是,要加上背景一类,所以总共我们有3类。
首先我们要读取自己的数据集
在config.py中
# config.py
import os.path
# gets home dir cross platform
#HOME = os.path.expanduser("~")
HOME = os.path.expanduser("/content/drive/My Drive/pytorch_ssd/")
# for making bounding boxes pretty
COLORS = ((255, 0, 0, 128), (0, 255, 0, 128), (0, 0, 255, 128),
(0, 255, 255, 128), (255, 0, 255, 128), (255, 255, 0, 128))
MEANS = (104, 117, 123)
mask = {
'num_classes': 3,
'lr_steps': (80000, 100000, 120000),
'max_iter': 120000,
'feature_maps': [38, 19, 10, 5, 3, 1],
'min_dim': 300,
'steps': [8, 16, 32, 64, 100, 300],
'min_sizes': [30, 60, 111, 162, 213, 264],
'max_sizes': [60, 111, 162, 213, 264, 315],
'aspect_ratios': [[2], [2, 3], [2, 3], [2, 3], [2], [2]],
'variance': [0.1, 0.2],
'clip': True,
'name': 'MASK',
}
# SSD300 CONFIGS
voc = {
'num_classes': 21,
'lr_steps': (80000, 100000, 120000),
'max_iter': 120000,
'feature_maps': [38, 19, 10, 5, 3, 1],
'min_dim': 300,
'steps': [8, 16, 32, 64, 100, 300],
'min_sizes': [30, 60, 111, 162, 213, 264],
'max_sizes': [60, 111, 162, 213, 264, 315],
'aspect_ratios': [[2], [2, 3], [2, 3], [2, 3], [2], [2]],
'variance': [0.1, 0.2],
'clip': True,
'name': 'VOC',
}
coco = {
'num_classes': 201,
'lr_steps': (280000, 360000, 400000),
'max_iter': 400000,
'feature_maps': [38, 19, 10, 5, 3, 1],
'min_dim': 300,
'steps': [8, 16, 32, 64, 100, 300],
'min_sizes': [21, 45, 99, 153, 207, 261],
'max_sizes': [45, 99, 153, 207, 261, 315],
'aspect_ratios': [[2], [2, 3], [2, 3], [2, 3], [2], [2]],
'variance': [0.1, 0.2],
'clip': True,
'name': 'COCO',
}新建的mask.py中
"""VOC Dataset Classes
Original author: Francisco Massa
https://github.com/fmassa/vision/blob/voc_dataset/torchvision/datasets/voc.py
Updated by: Ellis Brown, Max deGroot
"""
from .config import HOME
import os.path as osp
import sys
import torch
import torch.utils.data as data
import cv2
import numpy as np
if sys.version_info[0] == 2:
import xml.etree.cElementTree as ET
else:
import xml.etree.ElementTree as ET
#类别,这里有两类,一类为mask:戴口罩,另一类为nomask:不带口罩
MASK_CLASSES
= ( # always index 0
'mask','nomask')
# note: if you used our download scripts, this should be right
MASK_ROOT = osp.join(HOME, "data/maskornot/")
class MASKAnnotationTransform(object):
"""Transforms a MASK annotation into a Tensor of bbox coords and label index
Initilized with a dictionary lookup of classnames to indexes
Arguments:
class_to_ind (dict, optional): dictionary lookup of classnames -> indexes
(default: alphabetic indexing of MASK's 2 classes)
keep_difficult (bool, optional): keep difficult instances or not
(default: False)
height (int): height
width (int): width
"""
def __init__(self, class_to_ind=None, keep_difficult=False):
self.class_to_ind = class_to_ind or dict(
zip(MASK_CLASSES, range(len(MASK_CLASSES))))
self.keep_difficult = keep_difficult
def __call__(self, target, width, height):
"""
Arguments:
target (annotation) : the target annotation to be made usable
will be an ET.Element
Returns:
a list containing lists of bounding boxes [bbox coords, class name]
"""
res = []
for obj in target.iter('object'):
difficult = int(obj.find('difficult').text) == 1
if not self.keep_difficult and difficult:
continue
name = obj.find('name').text.lower().strip()
bbox = obj.find('bndbox')
pts = ['xmin', 'ymin', 'xmax', 'ymax']
bndbox = []
for i, pt in enumerate(pts):
cur_pt = int(bbox.find(pt).text) - 1
# scale height or width
cur_pt = cur_pt / width if i % 2 == 0 else cur_pt / height
bndbox.append(cur_pt)
label_idx = self.class_to_ind[name]
bndbox.append(label_idx)
res += [bndbox] # [xmin, ymin, xmax, ymax, label_ind]
# img_id = target.find('filename').text[:-4]
return res # [[xmin, ymin, xmax, ymax, label_ind], ... ]
class MASKDetection(data.Dataset):
"""VOC Detection Dataset Object
input is image, target is annotation
Arguments:
root (string): filepath to VOCdevkit folder.
image_set (string): imageset to use (eg. 'train', 'val', 'test')
transform (callable, optional): transformation to perform on the
input image
target_transform (callable, optional): transformation to perform on the
target `annotation`
(eg: take in caption string, return tensor of word indices)
dataset_name (string, optional): which dataset to load
(default: 'VOC2007')
"""
#image_sets=[('2007', 'trainval'), ('2012', 'trainval')],
def __init__(self, root,
image_sets='trainval',
transform=None, target_transform=MASKAnnotationTransform(),
dataset_name='MASK'):
self.root = root
self.image_set = image_sets
self.transform = transform
self.target_transform = target_transform
self.name = dataset_name
self._annopath = osp.join('%s', 'Annotations', '%s.xml')
self._imgpath = osp.join('%s', 'JPEGImages', '%s.jpg')
self.ids = list()
for line in open(MASK_ROOT+'/ImageSets/Main/'+self.image_set+'.txt'):
self.ids.append((MASK_ROOT, line.strip()))
def __getitem__(self, index):
im, gt, h, w = self.pull_item(index)
return im, gt
def __len__(self):
return len(self.ids)
def pull_item(self, index):
img_id = self.ids[index]
target = ET.parse(self._annopath % img_id).getroot()
img = cv2.imread(self._imgpath % img_id)
height, width, channels = img.shape
if self.target_transform is not None:
target = self.target_transform(target, width, height)
if self.transform is not None:
target = np.array(target)
img, boxes, labels = self.transform(img, target[:, :4], target[:, 4])
# to rgb
img = img[:, :, (2, 1, 0)]
# img = img.transpose(2, 0, 1)
target = np.hstack((boxes, np.expand_dims(labels, axis=1)))
return torch.from_numpy(img).permute(2, 0, 1), target, height, width
# return torch.from_numpy(img), target, height, width
def pull_image(self, index):
'''Returns the original image object at index in PIL form
Note: not using self.__getitem__(), as any transformations passed in
could mess up this functionality.
Argument:
index (int): index of img to show
Return:
PIL img
'''
img_id = self.ids[index]
return cv2.imread(self._imgpath % img_id, cv2.IMREAD_COLOR)
def pull_anno(self, index):
'''Returns the original annotation of image at index
Note: not using self.__getitem__(), as any transformations passed in
could mess up this functionality.
Argument:
index (int): index of img to get annotation of
Return:
list: [img_id, [(label, bbox coords),...]]
eg: ('001718', [('dog', (96, 13, 438, 332))])
'''
img_id = self.ids[index]
anno = ET.parse(self._annopath % img_id).getroot()
gt = self.target_transform(anno, 1, 1)
return img_id[1], gt
def pull_tensor(self, index):
'''Returns the original image at an index in tensor form
Note: not using self.__getitem__(), as any transformations passed in
could mess up this functionality.
Argument:
index (int): index of img to show
Return:
tensorized version of img, squeezed
'''
return torch.Tensor(self.pull_image(index)).unsqueeze_(0)这个文件是拷贝voc0712.py进行修改的,修改的地方已标红。
还要注意的是在data文件夹下的__init__.py中
#from .voc0712 import VOCDetection, VOCAnnotationTransform, VOC_CLASSES, VOC_ROOT
#from .coco import COCODetection, COCOAnnotationTransform, COCO_CLASSES, COCO_ROOT, get_label_map
from .mask import MASKDetection, MASKAnnotationTransform, MASK_CLASSES, MASK_ROOT需要注销掉voc和coco,加上我们自定义的数据集
然后就要开始我们的一步步踩坑之旅了。
我们需要预训练的vgg权重,进入的weights目录下,输入:
!wget https://s3.amazonaws.com/amdegroot-models/vgg16_reducedfc.pth再来看看在ssd.py中我们改了些 什么:
(1)在开头加上

(2)加上mask,并修改类别

(3)删除掉self.priors = Variable(self.priorbox.forward(), volatile=True)中的volatile=True
由于新版的pytorch已经将Variable和Tensor进行合并,且移除了volatile,使用with torch.no_grad改为:
with torch.no_grad():
self.priors = self.priorbox.forward()在train.py中:
from data import *
from utils.augmentations import SSDAugmentation
from layers.modules import MultiBoxLoss
from ssd import build_ssd
import os
import sys
import time
import torch
from torch.autograd import Variable
import torch.nn as nn
import torch.optim as optim
import torch.backends.cudnn as cudnn
import torch.nn.init as init
import torch.utils.data as data
import numpy as np
import argparse
def str2bool(v):
return v.lower() in ("yes", "true", "t", "1")
parser = argparse.ArgumentParser(
description='Single Shot MultiBox Detector Training With Pytorch')
train_set = parser.add_mutually_exclusive_group()
parser.add_argument('--dataset', default='VOC', choices=['VOC', 'COCO','MASK'],
type=str, help='VOC or COCO')
parser.add_argument('--dataset_root', default=MASK_ROOT,
help='Dataset root directory path')
parser.add_argument('--basenet', default='vgg16_reducedfc.pth',
help='Pretrained base model')
parser.add_argument('--batch_size', default=32, type=int,
help='Batch size for training')
parser.add_argument('--resume', default=None, type=str,
help='Checkpoint state_dict file to resume training from')
parser.add_argument('--start_iter', default=0, type=int,
help='Resume training at this iter')
parser.add_argument('--num_workers', default=4, type=int,
help='Number of workers used in dataloading')
parser.add_argument('--cuda', default=True, type=str2bool,
help='Use CUDA to train model')
parser.add_argument('--lr', '--learning-rate', default=1e-3, type=float,
help='initial learning rate')
parser.add_argument('--momentum', default=0.9, type=float,
help='Momentum value for optim')
parser.add_argument('--weight_decay', default=5e-4, type=float,
help='Weight decay for SGD')
parser.add_argument('--gamma', default=0.1, type=float,
help='Gamma update for SGD')
parser.add_argument('--visdom', default=False, type=str2bool,
help='Use visdom for loss visualization')
parser.add_argument('--save_folder', default='weights/',
help='Directory for saving checkpoint models')
args = parser.parse_args()
if torch.cuda.is_available():
if args.cuda:
torch.set_default_tensor_type('torch.cuda.FloatTensor')
if not args.cuda:
print("WARNING: It looks like you have a CUDA device, but aren't " +
"using CUDA.\nRun with --cuda for optimal training speed.")
torch.set_default_tensor_type('torch.FloatTensor')
else:
torch.set_default_tensor_type('torch.FloatTensor')
if not os.path.exists(args.save_folder):
os.mkdir(args.save_folder)
def train():
if args.dataset == 'COCO':
if args.dataset_root == VOC_ROOT:
if not os.path.exists(COCO_ROOT):
parser.error('Must specify dataset_root if specifying dataset')
print("WARNING: Using default COCO dataset_root because " +
"--dataset_root was not specified.")
args.dataset_root = COCO_ROOT
cfg = coco
dataset = COCODetection(root=args.dataset_root,
transform=SSDAugmentation(cfg['min_dim'],
MEANS))
elif args.dataset == 'VOC':
if args.dataset_root == COCO_ROOT:
parser.error('Must specify dataset if specifying dataset_root')
cfg = voc
dataset = VOCDetection(root=args.dataset_root,
transform=SSDAugmentation(cfg['min_dim'],
MEANS))
elif args.dataset == "MASK":
if args.dataset_root == MASK_ROOT:
parser.error('Must specify dataset if specifying dataset_root')
cfg = mask
dataset = MASKDetection(root=args.dataset_root,
transform=SSDAugmentation(cfg['min_dim'],
MEANS))
if args.visdom:
import visdom
viz = visdom.Visdom()
ssd_net = build_ssd('train', cfg['min_dim'], cfg['num_classes'])
net = ssd_net
if args.cuda:
net = torch.nn.DataParallel(ssd_net)
cudnn.benchmark = True
if args.resume:
print('Resuming training, loading {}...'.format(args.resume))
ssd_net.load_weights(args.resume)
else:
vgg_weights = torch.load(args.save_folder + args.basenet)
print('Loading base network...')
ssd_net.vgg.load_state_dict(vgg_weights)
if args.cuda:
net = net.cuda()
if not args.resume:
print('Initializing weights...')
# initialize newly added layers' weights with xavier method
ssd_net.extras.apply(weights_init)
ssd_net.loc.apply(weights_init)
ssd_net.conf.apply(weights_init)
optimizer = optim.SGD(net.parameters(), lr=args.lr, momentum=args.momentum,
weight_decay=args.weight_decay)
criterion = MultiBoxLoss(cfg['num_classes'], 0.5, True, 0, True, 3, 0.5,
False, args.cuda)
net.train()
# loss counters
loc_loss = 0
conf_loss = 0
epoch = 0
print('Loading the dataset...')
epoch_size = len(dataset) // args.batch_size
print('Training SSD on:', dataset.name)
print('Using the specified args:')
print(args)
step_index = 0
if args.visdom:
vis_title = 'SSD.PyTorch on ' + dataset.name
vis_legend = ['Loc Loss', 'Conf Loss', 'Total Loss']
iter_plot = create_vis_plot('Iteration', 'Loss', vis_title, vis_legend)
epoch_plot = create_vis_plot('Epoch', 'Loss', vis_title, vis_legend)
data_loader = data.DataLoader(dataset, args.batch_size,
num_workers=args.num_workers,
shuffle=True, collate_fn=detection_collate,
pin_memory=True)
# create batch iterator
batch_iterator = iter(data_loader)
for iteration in range(args.start_iter, cfg['max_iter']):
if args.visdom and iteration != 0 and (iteration % epoch_size == 0):
update_vis_plot(epoch, loc_loss, conf_loss, epoch_plot, None,
'append', epoch_size)
# reset epoch loss counters
loc_loss = 0
conf_loss = 0
epoch += 1
if iteration in cfg['lr_steps']:
step_index += 1
adjust_learning_rate(optimizer, args.gamma, step_index)
# load train data
#images, targets = next(batch_iterator)
try:
images, targets = next(batch_iterator)
except StopIteration:
batch_iterator = iter(data_loader)
images, targets = next(batch_iterator)
if args.cuda:
images = images.cuda()
targets = [ann.cuda() for ann in targets]
else:
images = images
targets = [ann for ann in targets]
# forward
t0 = time.time()
out = net(images)
# backprop
optimizer.zero_grad()
loss_l, loss_c = criterion(out, targets)
loss = loss_l + loss_c
loss.backward()
optimizer.step()
t1 = time.time()
loc_loss += loss_l.data.item()
conf_loss += loss_c.data.item()
if iteration % 10 == 0:
print('timer: %.4f sec.' % (t1 - t0))
print('iter ' + repr(iteration) + ' || Loss: %.4f ||' % (loss.data.item()), end=' ')
if args.visdom:
update_vis_plot(iteration, loss_l.data.item(), loss_c.data.item(),
iter_plot, epoch_plot, 'append')
if iteration != 0 and iteration % 5000 == 0:
print('Saving state, iter:', iteration)
torch.save(ssd_net.state_dict(), 'weights/ssd300_MASK_' +
repr(iteration) + '.pth')
torch.save(ssd_net.state_dict(),
args.save_folder + '' + args.dataset + '.pth')
def adjust_learning_rate(optimizer, gamma, step):
"""Sets the learning rate to the initial LR decayed by 10 at every
specified step
# Adapted from PyTorch Imagenet example:
# https://github.com/pytorch/examples/blob/master/imagenet/main.py
"""
lr = args.lr * (gamma ** (step))
for param_group in optimizer.param_groups:
param_group['lr'] = lr
def xavier(param):
init.xavier_uniform_(param)
def weights_init(m):
if isinstance(m, nn.Conv2d):
xavier(m.weight.data)
m.bias.data.zero_()
def create_vis_plot(_xlabel, _ylabel, _title, _legend):
return viz.line(
X=torch.zeros((1,)).cpu(),
Y=torch.zeros((1, 3)).cpu(),
opts=dict(
xlabel=_xlabel,
ylabel=_ylabel,
title=_title,
legend=_legend
)
)
def update_vis_plot(iteration, loc, conf, window1, window2, update_type,
epoch_size=1):
viz.line(
X=torch.ones((1, 3)).cpu() * iteration,
Y=torch.Tensor([loc, conf, loc + conf]).unsqueeze(0).cpu() / epoch_size,
win=window1,
update=update_type
)
# initialize epoch plot on first iteration
if iteration == 0:
viz.line(
X=torch.zeros((1, 3)).cpu(),
Y=torch.Tensor([loc, conf, loc + conf]).unsqueeze(0).cpu(),
win=window2,
update=True
)
if __name__ == '__main__':
train()我们要在该改成我们自己数据集的地方改成使用自己的数据集。然后需要注意的几个地方:
- 报错:IndexError: invalid index of a 0-dim tensor. Use tensor.item() to convert a 0-dim tensor to a Python number,将data[0]改成data.item()
- 报错:StopIteration,将images, targets = next(batch_iterator)改成
try: images, targets = next(batch_iterator) except StopIteration: batch_iterator = iter(data_loader) images, targets = next(batch_iterator) - 报错xavier_uniform已经被弃用,使用xavier_uniform_代替
接着是在multibox_loss.py中,需要注意的地方:
报错:IndexError: The shape of the mask [32, 2990] at index 0 does not match the shape of the indexed tensor [95680, 1] at index 0类似的,解决方法:在这里加上

报错:UserWarning: size_average and reduce args will be deprecated, please use reduction='sum' instead. warnings.warn(warning.format(ret)),将
loss_c = F.cross_entropy(conf_p, targets_weighted, size_average=False)改成
loss_c = F.cross_entropy(conf_p, targets_weighted, reduction='sum')
基本上就是这么多问题了,最后需要注意的是,要使用相对较小的学习率,比如1e-5,不能设置为其默认值。
训练开始:
!python train.py --dataset MASK --dataset_root MASK_ROOT --learning-rate 1e-5部分结果:
Loading base network...
Initializing weights...
Loading the dataset...
Training SSD on: MASK
Using the specified args:
Namespace(basenet='vgg16_reducedfc.pth', batch_size=32, cuda=True, dataset='MASK', dataset_root='MASK_ROOT', gamma=0.1, lr=1e-05, momentum=0.9, num_workers=4, resume=None, save_folder='weights/', start_iter=0, visdom=False, weight_decay=0.0005)
/usr/local/lib/python3.6/dist-packages/torch/nn/_reduction.py:43: UserWarning: size_average and reduce args will be deprecated, please use reduction='sum' instead.
warnings.warn(warning.format(ret))
timer: 10.9482 sec.
iter 0 || Loss: 19.6539 || timer: 0.4676 sec.
iter 10 || Loss: 18.4427 || timer: 0.2489 sec.
iter 20 || Loss: 16.3053 || timer: 0.4680 sec.
iter 30 || Loss: 14.5833 || timer: 0.4679 sec.
iter 40 || Loss: 12.6759 || timer: 0.2453 sec.
iter 50 || Loss: 11.4251 || timer: 0.4731 sec.
iter 60 || Loss: 9.5738 || timer: 0.4748 sec.
......训练完成结果:这里只保存训练到了5000次迭代的结果
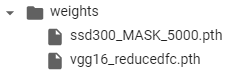
参考:
https://blog.csdn.net/weixin_43905350/article/details/100802246
https://blog.csdn.net/qq_30614451/article/details/100137358
https://cloud.tencent.com/developer/news/231868
https://blog.csdn.net/hitzijiyingcai/article/details/81636455
https://blog.csdn.net/dingkm666/article/details/88775428
来源:oschina
链接:https://my.oschina.net/u/4311641/blog/3300750