数据结构,跳表。跳表是redis的一个核心组件,也同时被广泛地运用到了各种缓存地实现当中,它的主要优点,就是可以跟红黑树、AVL等平衡树一样,做到比较稳定地插入、查询与删除。理论插入查询删除的算法时间复杂度为O(logN)。
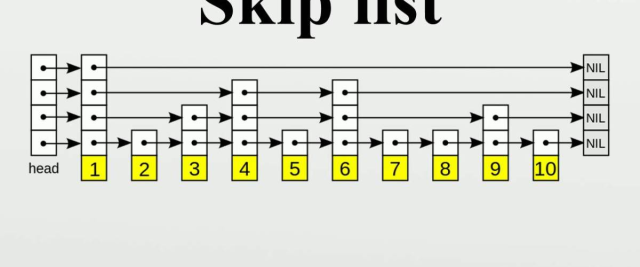
什么是跳表
链表,相信大家都不陌生,维护一个有序的链表是一件非常简单的事情,我们都知道,在一个有序的链表里面,查询跟插入的算法复杂度都是O(n)。

我们能不能进行优化呢,比如我们一次比较两个呢?那样不就可以把时间缩小一半?
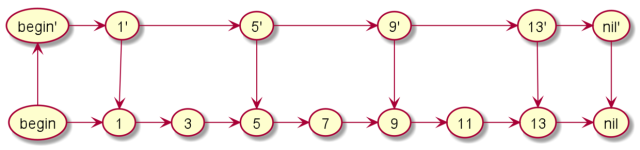
同理,如果我们4个4个比,那不就更快了?
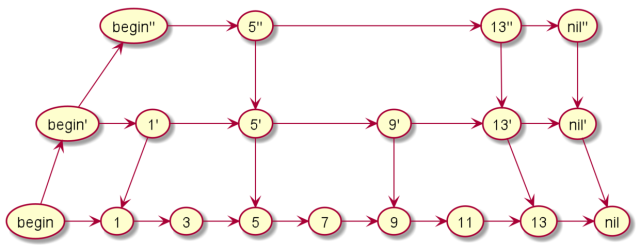
跳表就是这样的一种数据结构,结点是跳过一部分的,从而加快了查询的速度。跳表跟红黑树又有什么差别呢?既然两者的算法复杂度差不多,为什么Redis要使用跳表而不使用红黑树呢?跳表相对于红黑树,主要有这几个优点:1.代码相对简单,手写个跳表还有可能,手写个红黑树试试?
2.如果我们要查询一个区间里面的值,用平衡树可能会麻烦。这里的麻烦指的是实现和理解上,平衡二叉树查询一段区间也是可以做到的。3.删除一段区间,这个如果是平衡二叉树,就会相当困难,毕竟设计到树的平衡问题,而跳表则没有这种烦恼。好了,相信你对跳表已经有一些认识了,我们来简单介绍平衡二叉树的几个基本操作。
查询
假如我们要查询11,那么我们从最上层出发,发现下一个是5,再下一个是13,已经大于11,所以进入下一层,下一层的一个是9,查找下一个,下一个又是13,再次进入下一层。最终找到11。
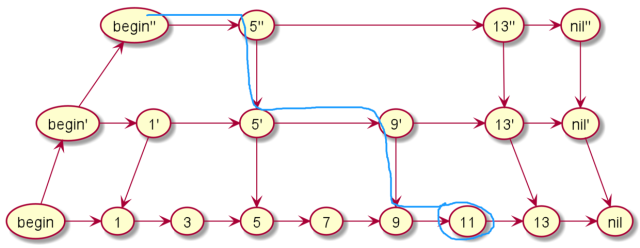
是不是非常的简单?我们可以把查找的过程总结为一条二元表达式(下一个是否大于结果?下一个:下一层)。理解跳表的查询过程非常重要,试试看查询其他数字,只要你理解了查询,后面两种都非常简单。
插入
插入的时候,首先要进行查询,然后从最底层开始,插入被插入的元素。然后看看从下而上,是否需要逐层插入。可是到底要不要插入上一层呢?我们都知道,我们想每层的跳跃都非常高效,越是平衡就越好(第一层1级跳,第二层2级跳,第3层4级跳,第4层8级跳)。但是用算法实现起来,确实非常地复杂的,并且要严格地按照2地指数次幂,我们还要对原有地结构进行调整。所以跳表的思路是抛硬币,听天由命,产生一个随机数,50%概率再向上扩展,否则就结束。这样子,每一个元素能够有X层的概率为0.5^(X-1)次方。反过来,第X层有多少个元素的数学期望大家也可以算一下。
删除
同插入一样,删除也是先查找,查找到了之后,再从下往上逐个删除。比较简单,就不再赘叙。
总结
跳表,用了计算机中一场非常用的解决问题的思路,随机。随机在深度学习与人工智能领域运用得非常的广泛。(不仅人会蒙,计算机也是很会蒙的)今天的介绍我们就讲到这里,如果你有兴趣,欢迎关注我,最近准备了一些AI相关的,苦于时间有限,整理后后面会和大家继续分享。
来源:oschina
链接:https://my.oschina.net/u/3730932/blog/3223096