1.状态机及形式语言基础
2. 版本1:仅仅匹配一个?
3. 版本2:如何匹配*?
4. 如何实现*, ?的匹配?
5. 如何实现根据输入的pattern,生成DFA状态机?
1. 状态机及形式语言基础
1.1 语言和文法
在计算机中存在下面两个比较重要的问题,一个问题提出之后,能否使用计算机来执行,如果能够执行的话,那么该怎么执行?这些都是计算模型需要解决的问题,为解决山这些问题,需要来首先了一下什么是形式语言,相对于自然语言而言,如何去描述一个形式语言(文法)?
自然语言就是日常的口头语言,将一个自然语言翻译成另外的一种自然语言的问题引出了“形式语言”的概念。下面就是一个迭代的定义:
1. 字母表V:含有有限元素的非空集合,其中包含终结符号(无法被替换的符号)记为T;非终结符号(简单的将是能够被替换的元素),记为N;定义开始符S为推导的开始。
2. 单词:定义在字母表V上的单词定义为V中元素组成的有限长度的字串。
3. 空串:没有符号的串,记为λ
4. V上所有单词的集合记为V*
5. 指明V*中的串能够被什么样的串替换的表达式称之为“产生式”
6. 有了上面的基础开始定义什么是文法:文法是由下面的是是部分组成:G = < V, T, S, P >,其中字母表V,有V上的所有的终结符组成的集合T,S为推导的开始符,P为产生式的集合。
7. 下面定义什么是语言L,由G生成的语言是由S能够推导出的所有终结符号构成的集合。
显然通过上面的定义同时类比自然语言:字母表相当于英语的26个字母。单词类似于自然语言的英语单词;文法就相当于英语的语法规则,例如(名词 + 动词 + 形容词, i am happy)。通过这些文法进而能够推导出英语的一系列句子,即是语言。这是一个简单的例子:
定义词汇表V ={S, A, a, b},定义终结符号T = { a, b },开始符号定义为S,产生式如下:
S -> aA S -> b A -> aa,那么通过上述文法说能够表达的语言的集合如下:
S -> aA -> aaa这是语言的其中之一,另外S -> b是另外一个,所以L(G) = { b, aaa }
1.2 文法的分类
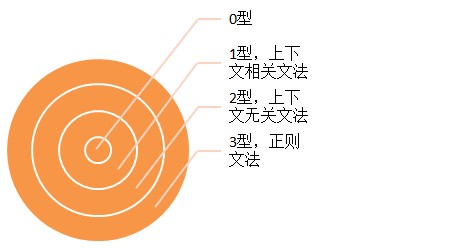
文法存在着多种分类方式,常见的是乔姆斯基分类方法。该方法将文法分为0型文法:对产生式没有要求;1型文法,存在两种产生式w1->w2,且|w1| > |w2|,或者是w1->λ;2型文法,只存在w1->w2的表达式,并且w1是一个非终结符的单个符号;3型文法,只存在w1->w2的形式,并且满足w1=A, 并且w2=aB或者w2=a,或者满足w1=S, w2=λ.通过上面的定义可以看出要求是越来越严格。其中1型文法也称之为上下文相关文法(如果想要使用某个产生是进行推导的话,必须要根据推导公式的上下文),2型文法同时也称为上下文无关文法。
1.3 有限状态机简介
1.3.1 定义
有限状态机M={S, I, O, f, g, s0}
S:有限状态集合
I:输入字母表
O: 输出字母表
f:状态转换函数
g:输出函数
s0:初始状态
状态机可以使用状态转换图或者是状态转换表来表示,状态转换图比较直观,状态转换表的话,比较容易编写程序。
1.3.2 NFA
NFA表示对于某个状态state和输出input的话,NFA的下一个状态不唯一 ,而是存在形成一个状态集合。
1.3.3 DFA
和NFA不同在于,DFA的下一个状态是唯一的。
1.3.4 如何将正则表达式转换成NFA?
只需按照下面的方法(Thompson),即可将正则表达式转换成NFA(http://tech.idv2.com/2006/05/08/parse-regex-with-DFA/):
1. 对于空记号ε,生成下面的NFA
![]()
2. 对于V的字母表中的元素a,生成下面的NFA
![]()
3. 令正则表达式s和t的NFA分别为N(s)和N(t)
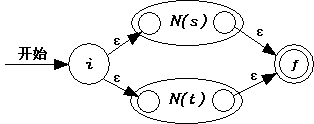
3.1 对于s|t,按照以下的方式生成NFA N(s|t)
3.2 对于st,按照以下的方式生成NFA N(st)
![]()
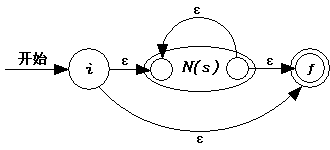
3.3 对于s*,按照以下的方式生成NFA N(s*)
3.4 对于(s),使用s本身的NFA N(s)
下面是一个具体的例子:
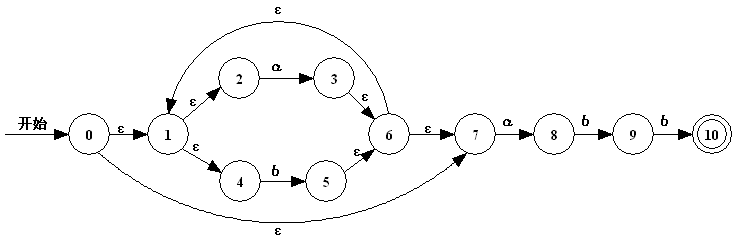
正则表达式r=(a|b)*abb转换成NFA之后,如下:
1.3.5 如何将NFA转换成DFA?
定义以下的操作。
end
1.4 如何进行语言识别简单通用模块?程序代码块结构。
基本的代码(示意代码,不准确)块如下:根据上面的状态机定义,首先定义初始状态state,定义输入ch,开始循环,如果没有到结尾,开始状态转换。

2. 版本1,如何识别一个?
// 简单正则表达式匹配函数
来源:https://www.cnblogs.com/xuqiang/archive/2011/03/25/1995542.html