
如果写过C和C++的小伙伴肯定都知道,程序中的内存管理是非常关键的,一不小心可能就会产生内存泄漏。
但是我们在写Python的时候好像从来没有关心过内存的处理,为什么可以这么爽?
在你爽的背后,实际上是Python在默默的帮你管理着,具体怎么实现的,听我慢慢道来。
一、引用计数
在Python中,使用了引用计数这一技术实现内存管理。
一个对象被创建完成后就有一个变量指向他,那么就说明他的引用计数为1,以后如果有其他变量指向他,引用计数也会相应增加,如果将一个变量不再执行这个对象,那么这个对象的引用计数减1。
如果一个对象没有任何变量指向他,也即引用计数为0,那么这个对象会被Python回收。
示例代码如下:
class Person(object):
def __init__(self,name):
self.name = name
def __del__(self):
print('%s执行了del函数'%self.name)
while True:
p1 = Person('p1')
p2 = Person('p2')
del p1
del p2
a = input('test:')
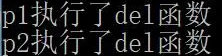
可以看到,两个对象的del函数都得到了执行。
二、循环引用
引用计数这一技术虽然可以在一定程度上解决内存管理的问题。但是还是有不能解决的问题,即循环引用。
比如现在有两个对象分别为a和b,a指向了b,b又指向了a,那么他们两的引用计数永远都不会为0。也即永远得不到回收。
看以下示例:
class Person(object):
def __init__(self,name):
self.name = name
def __del__(self):
print('%s执行了del函数'%self.name)
while True:
p1 = Person('p1')
p2 = Person('p2')
# 循环引用后,永远得不到释放
p1.next = p2
p2.prev = p1
del p1
del p2
a = input('test:')

可以看到,del函数是不会运行的,是因为循环引用导致两个对象得不到释放。
三、标记清除和分代回收
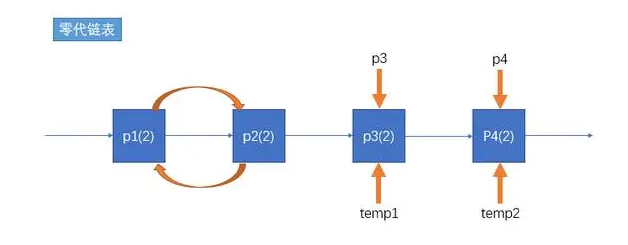
在Python程序中,每次你新创建了一个对象,那么就会将这个对象挂到一个叫做零代链表中(当然这个链表是Python内部的,Python开发者是没法访问到的)。
比如现在你在程序中创建四个Person对象,分别叫做p1、p2、p3以及p4,然后p1与p2之间互相引用,并且让p3和p4的引用计数为2,示例代码如下:
import sys
class Person(object):
def __init__(self,name):
self.name = name
self.next = None
self.prev = None
p1 = Person('p1')
p2 = Person('p2')
p3 = Person('p3')
p4 = Person('p4')
p1.next = p2
p2.prev = p1
temp1 = p3
temp2 = p4
print(sys.getrefcount(p1))
print(sys.getrefcount(p2))
print(sys.getrefcount(p3))
print(sys.getrefcount(p4))
以上代码实际上就会将p1和p2以及p3和p4挂在一个叫做零代链表中,示例图如下:

我们可以看到,这时候p1引用了p2,而p2又引用了p1,因此这两个对象产生了循环引用。在后期即使我删除了del p1以及del p2,那么这两个对象也会得不到释放。
因此这时候Python就启用了一个新的垃圾回收的机制。
如果创建的对象总和减去被释放的对象,达到一定的值(某个阈值),那么Python就会遍历这个零代链表,找到那些有相互引用的对象,将这些对象的引用计数减1,如果引用计数值为0了,那么就说明这个对象是可以被释放的,比如以上p1和p2,这时候就会释放p1和p2。
接下来再将没有被释放的对象,挪动到一个新的链表中,这个链表叫做一代链表。
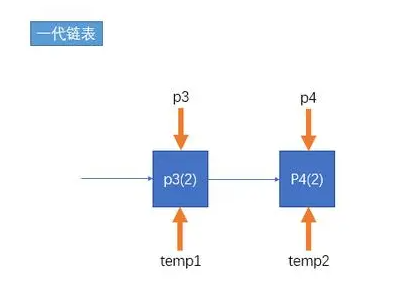
在零代链表清理的次数达到某个阈值后,Python会去遍历一代链表,将那些没有得到释放的对象移动到二代链表。同样的原理,如果一代链表清理的次数达到某个阈值后,Python会去遍历二代链表,把垃圾对象进行回收。
四、弱代假说
来看看代垃圾回收算法的核心行为:垃圾回收器会更频繁的处理新对象。一个新的对象即是你的程序刚刚创建的,而一个来的对象则是经过了几个时间周期之后仍然存在的对象。Python会在当一个对象从零代移动到一代,或是从一代移动到二代的过程中提升(promote)这个对象。
为什么要这么做?这种算法的根源来自于弱代假说(weak generational hypothesis)。这个假说由两个观点构成:首先是年轻的对象通常死得也快,而老对象则很有可能存活更长的时间。
假定现在我用Python创建一个新对象:

根据假说,我的代码很可能仅仅会使用ABC很短的时间。这个对象也许仅仅只是一个方法中的中间结果,并且随着方法的返回这个对象就将变成垃圾了。大部分的新对象都是如此般地很快变成垃圾。然而,偶尔程序会创建一些很重要的,存活时间比较长的对象-例如web应用中的session变量或是配置项。
通过频繁的处理零代链表中的新对象,Python的垃圾收集器将把时间花在更有意义的地方:它处理那些很快就可能变成垃圾的新对象。同时只在很少的时候,当满足阈值的条件,收集器才回去处理那些老变量。
文源网络,仅供学习之用,如有侵权,联系删除。
我将优质的技术文章和经验总结都汇集在了我的公众号【Python圈子】里。
在学习Python的道路上肯定会遇见困难,别慌,我这里有一套学习资料,包含40+本电子书,600+个教学视频,涉及Python基础、爬虫、框架、数据分析、机器学习等,不怕你学不会!还有学习交流群,一起学习进步~

来源:oschina
链接:https://my.oschina.net/u/4477231/blog/3212456