环境
storm有本地模式和集群模式,本地模式什么都不需要,知道storm jar包就可以运行了,我在windows下eclipse中使用maven进行本地模式的编程。storm编程一种可以继承BaseRichSpout和BaseBasicBolt类,另一种是实现IRichSpout和IRichBolt接口。
maven下载storm jar包
从storm官网上可以查到storm maven配置http://storm.apache.org/downloads.html
我这里使用的是storm-0.10.0
groupId: org.apache.storm
artifactId: storm-core
version: 0.10.0第一种方法 继承类
编写spout
package com.storm.stormDemo;
import java.util.Map;
import java.util.Random;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
public class RandomSpout extends BaseRichSpout{
private SpoutOutputCollector collector;
private static String[] words = {"happy","excited","angry"};
/* (non-Javadoc)
* @see backtype.storm.spout.ISpout#open(java.util.Map, backtype.storm.task.TopologyContext, backtype.storm.spout.SpoutOutputCollector)
*/
public void open(Map arg0, TopologyContext arg1, SpoutOutputCollector arg2) {
// TODO Auto-generated method stub
this.collector = arg2;
}
/* (non-Javadoc)
* @see backtype.storm.spout.ISpout#nextTuple()
*/
public void nextTuple() {
// TODO Auto-generated method stub
String word = words[new Random().nextInt(words.length)];
collector.emit(new Values(word));
}
/* (non-Javadoc)
* @see backtype.storm.topology.IComponent#declareOutputFields(backtype.storm.topology.OutputFieldsDeclarer)
*/
public void declareOutputFields(OutputFieldsDeclarer arg0) {
// TODO Auto-generated method stub
arg0.declare(new Fields("randomstring"));
}
}编写bolt
package com.storm.stormDemo;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Tuple;
public class SenqueceBolt extends BaseBasicBolt{
/* (non-Javadoc)
* @see backtype.storm.topology.IBasicBolt#execute(backtype.storm.tuple.Tuple, backtype.storm.topology.BasicOutputCollector)
*/
public void execute(Tuple input, BasicOutputCollector collector) {
// TODO Auto-generated method stub
String word = (String) input.getValue(0);
String out = "I'm " + word + "!";
System.out.println("out=" + out);
}
/* (non-Javadoc)
* @see backtype.storm.topology.IComponent#declareOutputFields(backtype.storm.topology.OutputFieldsDeclarer)
*/
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// TODO Auto-generated method stub
}
}编写主类
package com.storm.stormDemo;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.utils.Utils;
public class FirstTopo {
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new RandomSpout());
builder.setBolt("bolt", new SenqueceBolt()).shuffleGrouping("spout");
Config conf = new Config();
conf.setDebug(false);
if (args != null && args.length > 0) {
conf.setNumWorkers(3);
StormSubmitter.submitTopology(args[0], conf, builder.createTopology());
} else {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("firstTopo", conf, builder.createTopology());
Utils.sleep(3000);
cluster.killTopology("firstTopo");
cluster.shutdown();
}
}
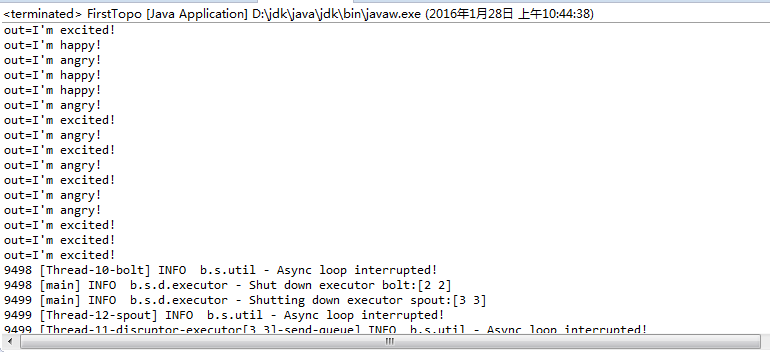
}执行结果
第二种方法 实现接口
编写spout
package com.storm.stormDemo;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.util.Map;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichSpout;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
public class WordReader implements IRichSpout {
private static final long serialVersionUID = 1L;
private SpoutOutputCollector collector;
private FileReader fileReader;
private boolean completed = false;
public boolean isDistributed() {
return false;
}
/**
* 这是第一个方法,里面接收了三个参数,第一个是创建Topology时的配置,
* 第二个是所有的Topology数据,第三个是用来把Spout的数据发射给bolt
* **/
public void open(Map conf, TopologyContext context,
SpoutOutputCollector collector) {
try {
//获取创建Topology时指定的要读取的文件路径
this.fileReader = new FileReader(conf.get("wordsFile").toString());
} catch (FileNotFoundException e) {
throw new RuntimeException("Error reading file ["
+ conf.get("wordFile") + "]");
}
//初始化发射器
this.collector = collector;
}
/**
* 这是Spout最主要的方法,在这里我们读取文本文件,并把它的每一行发射出去(给bolt)
* 这个方法会不断被调用,为了降低它对CPU的消耗,当任务完成时让它sleep一下
* **/
public void nextTuple() {
if (completed) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// Do nothing
}
return;
}
String str;
// Open the reader
BufferedReader reader = new BufferedReader(fileReader);
try {
// Read all lines
while ((str = reader.readLine()) != null) {
/**
* 发射每一行,Values是一个ArrayList的实现
*/
this.collector.emit(new Values(str), str);
}
} catch (Exception e) {
throw new RuntimeException("Error reading tuple", e);
} finally {
completed = true;
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("line"));
}
public void close() {
// TODO Auto-generated method stub
}
public void activate() {
// TODO Auto-generated method stub
}
public void deactivate() {
// TODO Auto-generated method stub
}
public void ack(Object msgId) {
System.out.println("OK:" + msgId);
}
public void fail(Object msgId) {
System.out.println("FAIL:" + msgId);
}
public Map<String, Object> getComponentConfiguration() {
// TODO Auto-generated method stub
return null;
}
}编写第一个bolt
package com.storm.stormDemo;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
public class WordNormalizer implements IRichBolt {
private OutputCollector collector;
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.collector = collector;
}
/**这是bolt中最重要的方法,每当接收到一个tuple时,此方法便被调用
* 这个方法的作用就是把文本文件中的每一行切分成一个个单词,并把这些单词发射出去(给下一个bolt处理)
* **/
public void execute(Tuple input) {
String sentence = input.getString(0);
String[] words = sentence.split(" ");
for (String word : words) {
word = word.trim();
if (!word.isEmpty()) {
word = word.toLowerCase();
// Emit the word
List a = new ArrayList();
a.add(input);
collector.emit(a, new Values(word));
}
}
//确认成功处理一个tuple
collector.ack(input);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
public void cleanup() {
// TODO Auto-generated method stub
}
public Map<String, Object> getComponentConfiguration() {
// TODO Auto-generated method stub
return null;
}
}编写第二个bolt
package com.storm.stormDemo;
import java.util.HashMap;
import java.util.Map;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class WordCounter implements IRichBolt {
Integer id;
String name;
Map<String, Integer> counters;
private OutputCollector collector;
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.counters = new HashMap<String, Integer>();
this.collector = collector;
this.name = context.getThisComponentId();
this.id = context.getThisTaskId();
}
public void execute(Tuple input) {
String str = input.getString(0);
if (!counters.containsKey(str)) {
counters.put(str, 1);
} else {
Integer c = counters.get(str) + 1;
counters.put(str, c);
}
// 确认成功处理一个tuple
collector.ack(input);
}
/**
* Topology执行完毕的清理工作,比如关闭连接、释放资源等操作都会写在这里
* 因为这只是个Demo,我们用它来打印我们的计数器
* */
public void cleanup() {
System.out.println("-- Word Counter [" + name + "-" + id + "] --");
for (Map.Entry<String, Integer> entry : counters.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
counters.clear();
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// TODO Auto-generated method stub
}
public Map<String, Object> getComponentConfiguration() {
// TODO Auto-generated method stub
return null;
}
}编写主类
package com.storm.stormDemo;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields;
import backtype.storm.utils.Utils;
public class WordCountTopologyMain {
public static void main(String[] args) throws InterruptedException {
//定义一个Topology
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("word-reader",new WordReader(),1);
builder.setBolt("word-normalizer", new WordNormalizer()).shuffleGrouping("word-reader");
builder.setBolt("word-counter", new WordCounter(),2).fieldsGrouping("word-normalizer", new Fields("word"));
//配置
Config conf = new Config();
conf.put("wordsFile", "f:/test.txt");
conf.setDebug(false);
//提交Topology
conf.put(Config.TOPOLOGY_MAX_SPOUT_PENDING, 1);
//创建一个本地模式cluster
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("Getting-Started-Toplogie", conf,builder.createTopology());
Utils.sleep(3000);
cluster.killTopology("Getting-Started-Toplogie");
cluster.shutdown();
}
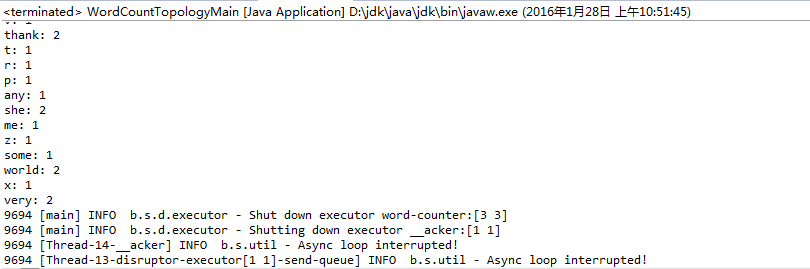
}执行结果
更多实例请参考:
http://ifeve.com/getting-started-with-storm6/
http://www.aboutyun.com/thread-8080-1-1.html
总结
在spout读取文件的时候,如果你设置spout的数量为2的时候,读取的数据就会重复,bolt就会处理重复的数据,这是我们在编写spout的时候要注意的。
来源:oschina
链接:https://my.oschina.net/u/2000675/blog/610753