-------------------LVS专题------------------------
LVS原理详解及部署之二:LVS原理详解(3种工作方式8种调度算法)
LVS原理详解及部署之五:LVS+keepalived实现负载均衡&高可用
-------------------------------------------------
一、集群简介
什么是集群
计算机集群简称集群是一种计算机系统,它通过一组松散集成的计算机软件和/或硬件连接起来高度紧密地协作完成计算工作。在某种意义上,他们可以被看作是一台计算机。集群系统中的单个计算机通常称为节点,通常通过局域网连接,但也有其它的可能连接方式。集群计算机通常用来改进单个计算机的计算速度和/或可靠性。一般情况下集群计算机比单个计算机,比如工作站或超级计算机性能价格比要高得多。
集群就是一组独立的计算机,通过网络连接组合成一个组合来共同完一个任务
LVS在企业架构中的位置:
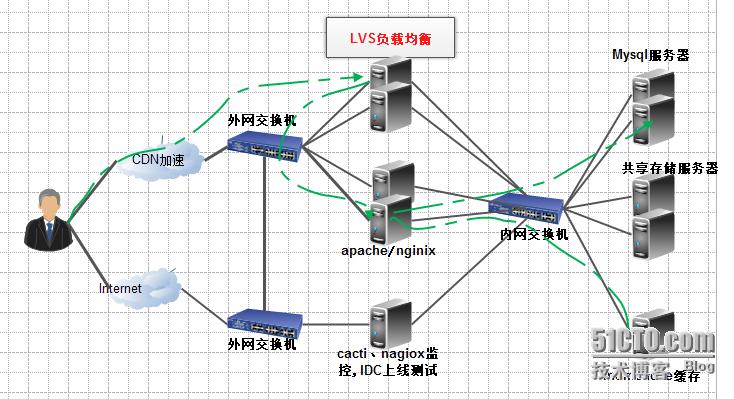
以上的架构只是众多企业里面的一种而已。绿色的线就是用户访问请求的数据流向。用户-->LVS负载均衡服务器--->apahce服务器--->mysql服务器&memcache服务器&共享存储服务器。并且我们的mysql、共享存储也能够使用LVS再进行负载均衡。
---------------小结-------------------------
集群:就是一组相互独立的计算机,通过高速的网络组成一个计算机系统,每个集群节点都是运行其自己进程的一个独立服务器。对网络用户来讲,网站后端就是一个单一的系统,协同起来向用户提供系统资源,系统服务。
-------------------------------------------
为什么要使用集群
集群的特点
1)高性能performance。一些需要很强的运算处理能力比如天气预报,核试验等。这就不是几台计算机能够搞定的。这需要上千台一起来完成这个工作的。
2)价格有效性
通常一套系统集群架构,只需要几台或数十台服务器主机即可,与动则上百王的专用超级计算机具有更高的性价比。
3)可伸缩性
当服务器负载压力增长的时候,系统能够扩展来满足需求,且不降低服务质量。
4)高可用性
尽管部分硬件和软件发生故障,整个系统的服务必须是7*24小时运行的。
集群的优势
1)透明性
如果一部分服务器宕机了业务不受影响,一般耦合度没有那么高,依赖关系没有那么高。比如NFS服务器宕机了其他就挂载不了了,这样依赖性太强。
2)高性能
访问量增加,能够轻松扩展。
3)可管理性
整个系统可能在物理上很大,但很容易管理。
4)可编程性
在集群系统上,容易开发应用程序,门户网站会要求这个。
集群分类及不同分类的特点
计算机集群架构按照功能和结构一般分成以下几类:
1)负载均衡集群(Loadbalancingclusters)简称LBC
2)高可用性集群(High-availabilityclusters)简称HAC
3)高性能计算集群(High-perfomanceclusters)简称HPC
4)网格计算(Gridcomputing)
网络上面一般认为是有三个,负载均衡和高可用集群式我们互联网行业常用的集群架构。
(1)负载均衡集群
负载均衡集群为企业提供了更为实用,性价比更高的系统架构解决方案。负载均衡集群把很多客户集中访问的请求负载压力可能尽可能平均的分摊到计算机集群中处理。客户请求负载通常包括应用程度处理负载和网络流量负载。这样的系统非常适合向使用同一组应用程序为大量用户提供服务。每个节点都可以承担一定的访问请求负载压力,并且可以实现访问请求在各节点之间动态分配,以实现负载均衡。
负载均衡运行时,一般通过一个或多个前端负载均衡器将客户访问请求分发到后端一组服务器上,从而达到整个系统的高性能和高可用性。这样计算机集群有时也被称为服务器群。一般高可用性集群和负载均衡集群会使用类似的技术,或同时具有高可用性与负载均衡的特点。
负载均衡集群的作用
1)分担访问流量(负载均衡)
2)保持业务的连续性(高可用)
(2)高可用性集群
一般是指当集群中的任意一个节点失效的情况下,节点上的所有任务自动转移到其他正常的节点上,并且此过程不影响整个集群的运行,不影响业务的提供。
类似是集群中运行着两个或两个以上的一样的节点,当某个主节点出现故障的时候,那么其他作为从 节点的节点就会接替主节点上面的任务。从节点可以接管主节点的资源(IP地址,架构身份等),此时用户不会发现提供服务的对象从主节点转移到从节点。
高可用性集群的作用:当一个机器宕机另一台进行接管。比较常用的高可用集群开源软件有:keepalive,heardbeat。
(3)高性能计算集群
高性能计算集群采用将计算任务分配到集群的不同计算节点儿提高计算能力,因而主要应用在科学计算领域。比较流行的HPC采用Linux操作系统和其它一些免费软件来完成并行运算。这一集群配置通常被称为Beowulf集群。这类集群通常运行特定的程序以发挥HPCcluster的并行能力。这类程序一般应用特定的运行库, 比如专为科学计算设计的MPI库。
HPC集群特别适合于在计算中各计算节点之间发生大量数据通讯的计算作业,比如一个节点的中间结果或影响到其它节点计算结果的情况。
常用集群软硬件
常用开源集群软件有:lvs,keepalived,haproxy,nginx,apache,heartbeat
常用商业集群硬件有:F5,Netscaler,Radware,A10等
二、LVS负载均衡集群介绍
负载均衡集群的作用:提供一种廉价、有效、透明的方法,来扩展网络设备和服务器的负载带宽、增加吞吐量,加强网络数据处理能力、提高网络的灵活性和可用性。
1)把单台计算机无法承受的大规模的并发访问或数据流量分担到多台节点设备上分别处理,减少用户等待响应的时间,提升用户体验。
2)单个重负载的运算分担到多台节点设备上做并行处理,每个节点设备处理结束后,将结果汇总,返回给用户,系统处理能力得到大幅度提高。
3)7*24小时的服务保证,任意一个或多个设备节点设备宕机,不能影响到业务。在负载均衡集群中,所有计算机节点都应该提供相同的服务,集群负载均衡获取所有对该服务的如站请求。
LVS介绍
LVS是linux virtual server的简写linux虚拟服务器,是一个虚拟的服务器集群系统,可以再unix/linux平台下实现负载均衡集群功能。该项目在1998年5月由章文嵩博士组织成立。
以下是LVS官网提供的4篇文章:(非常详细,我觉得有兴趣还是看官方文档比较正宗吧!!)
http://www.linuxvirtualserver.org/zh/lvs1.html
http://www.linuxvirtualserver.org/zh/lvs2.html
http://www.linuxvirtualserver.org/zh/lvs3.html
http://www.linuxvirtualserver.org/zh/lvs4.html
IPVS发展史
早在2.2内核时,IPVS就已经以内核补丁的形式出现。
从2.4.23版本开始ipvs软件就是合并到linux内核的常用版本的内核补丁的集合。
从2.4.24以后IPVS已经成为linux官方标准内核的一部分
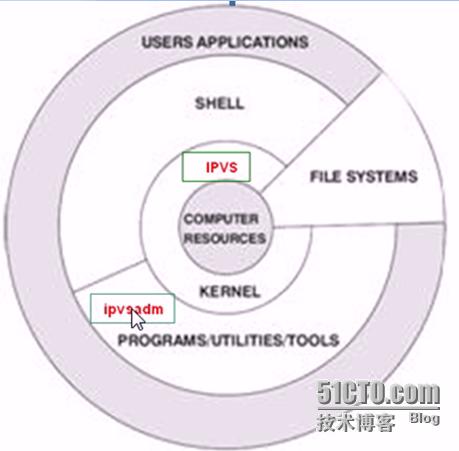
从上图可以看出lpvs是工作在内核层,我们不能够直接操作ipvs,vs负载均衡调度技术是在linux内核中实现的。因此,被称之为linux虚拟服务器。我们使用该软件配置lvs的时候,不能直接配置内核中的ipvs,而需要使用ipvs的管理工具ipvsadm进行管理。通过keepalived也可以管理LVS。
LVS体系结构与工作原理简单描述
LVS集群负载均衡器接受服务的所有入展客户端的请求,然后根据调度算法决定哪个集群节点来处理回复客户端的请求。
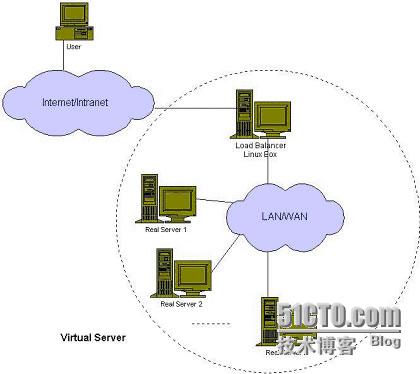
LVS虚拟服务器的体系如下图所示,一组服务器通过高速的局域网或者地理分布的广域网相互连接,在这组服务器之前有一个负载调度器(load balance)。负载调度器负责将客户的请求调度到真实服务器上。这样这组服务器集群的结构对用户来说就是透明的。客户访问集群系统就如只是访问一台高性能,高可用的服务器一样。客户程序不受服务器集群的影响,不做任何修改。
就比如说:我们去饭店吃饭点菜,客户只要跟服务员点菜就行。并不需要知道具体他们是怎么分配工作的,所以他们内部对于我们来说是透明的。此时这个服务员就会按照一定的规则把他手上的活,分配到其他人员上去。这个服务员就是负载均衡器(LB)而后面这些真正做事的就是服务器集群。
底下是官网提供的结构图:
LVS的基本工作过程
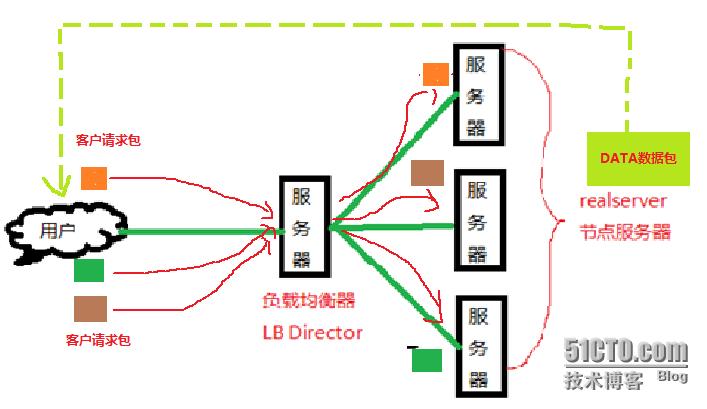
客户请发送向负载均衡服务器发送请求。负载均衡器接受客户的请求,然后先是根据LVS的调度算法(8种)来决定要将这个请求发送给哪个节点服务器。然后依据自己的工作模式(3种)来看应该如何把这些客户的请求如何发送给节点服务器,节点服务器又应该如何来把响应数据包发回给客户端。
恩,那这样我们就只要接下来搞懂LVS的3中工作模式,8种调度算法就可以了。
LVS的三种工作模式:
1)VS/NAT模式(Network address translation)
2)VS/TUN模式(tunneling)
3)DR模式(Direct routing)
1、NAT模式-网络地址转换
Virtualserver via Network address translation(VS/NAT)
这个是通过网络地址转换的方法来实现调度的。首先调度器(LB)接收到客户的请求数据包时(请求的目的IP为VIP),根据调度算法决定将请求发送给哪个后端的真实服务器(RS)。然后调度就把客户端发送的请求数据包的目标IP地址及端口改成后端真实服务器的IP地址(RIP),这样真实服务器(RS)就能够接收到客户的请求数据包了。真实服务器响应完请求后,查看默认路由(NAT模式下我们需要把RS的默认路由设置为LB服务器。)把响应后的数据包发送给LB,LB再接收到响应包后,把包的源地址改成虚拟地址(VIP)然后发送回给客户端。
调度过程IP包详细图:
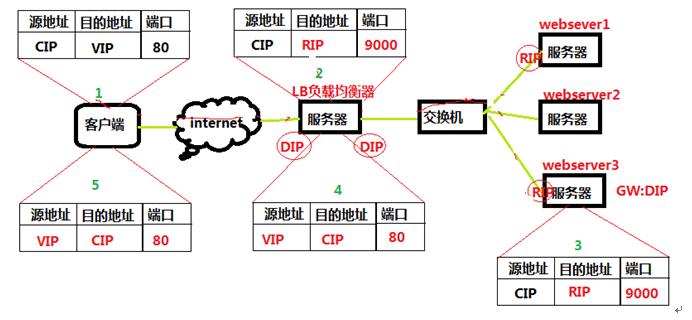
原理图简述:
1)客户端请求数据,目标IP为VIP
2)请求数据到达LB服务器,LB根据调度算法将目的地址修改为RIP地址及对应端口(此RIP地址是根据调度算法得出的。)并在连接HASH表中记录下这个连接。
3)数据包从LB服务器到达RS服务器webserver,然后webserver进行响应。Webserver的网关必须是LB,然后将数据返回给LB服务器。
4)收到RS的返回后的数据,根据连接HASH表修改源地址VIP&目标地址CIP,及对应端口80.然后数据就从LB出发到达客户端。
5)客户端收到的就只能看到VIP\DIP信息。
NAT模式优缺点:
1、NAT技术将请求的报文和响应的报文都需要通过LB进行地址改写,因此网站访问量比较大的时候LB负载均衡调度器有比较大的瓶颈,一般要求最多之能10-20台节点
2、只需要在LB上配置一个公网IP地址就可以了。
3、每台内部的节点服务器的网关地址必须是调度器LB的内网地址。
4、NAT模式支持对IP地址和端口进行转换。即用户请求的端口和真实服务器的端口可以不一致。
2、TUN模式
virtual server via ip tunneling模式:采用NAT模式时,由于请求和响应的报文必须通过调度器地址重写,当客户请求越来越多时,调度器处理能力将成为瓶颈。为了解决这个问题,调度器把请求的报文通过IP隧道转发到真实的服务器。真实的服务器将响应处理后的数据直接返回给客户端。这样调度器就只处理请求入站报文,由于一般网络服务应答数据比请求报文大很多,采用VS/TUN模式后,集群系统的最大吞吐量可以提高10倍。
VS/TUN的工作流程图如下所示,它和NAT模式不同的是,它在LB和RS之间的传输不用改写IP地址。而是把客户请求包封装在一个IP tunnel里面,然后发送给RS节点服务器,节点服务器接收到之后解开IP tunnel后,进行响应处理。并且直接把包通过自己的外网地址发送给客户不用经过LB服务器。
Tunnel原理流程图:
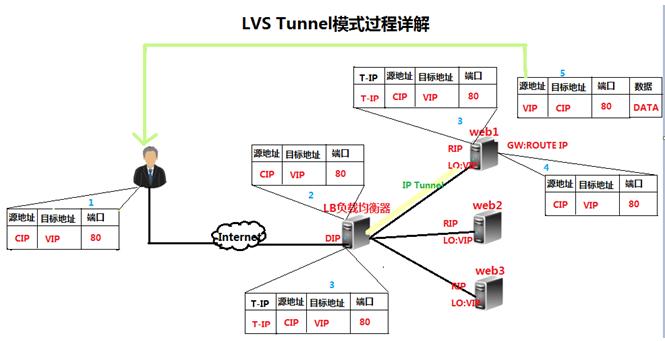
原理图过程简述:
1)客户请求数据包,目标地址VIP发送到LB上。
2)LB接收到客户请求包,进行IP Tunnel封装。即在原有的包头加上IP Tunnel的包头。然后发送出去。
3)RS节点服务器根据IP Tunnel包头信息(此时就又一种逻辑上的隐形隧道,只有LB和RS之间懂)收到请求包,然后解开IP Tunnel包头信息,得到客户的请求包并进行响应处理。
4)响应处理完毕之后,RS服务器使用自己的出公网的线路,将这个响应数据包发送给客户端。源IP地址还是VIP地址。(RS节点服务器需要在本地回环接口配置VIP,后续会讲)
3、DR模式(直接路由模式)
Virtual server via direct routing (vs/dr)
DR模式是通过改写请求报文的目标MAC地址,将请求发给真实服务器的,而真实服务器响应后的处理结果直接返回给客户端用户。同TUN模式一样,DR模式可以极大的提高集群系统的伸缩性。而且DR模式没有IP隧道的开销,对集群中的真实服务器也没有必要必须支持IP隧道协议的要求。但是要求调度器LB与真实服务器RS都有一块网卡连接到同一物理网段上,必须在同一个局域网环境。
DR模式是互联网使用比较多的一种模式。
DR模式原理图:
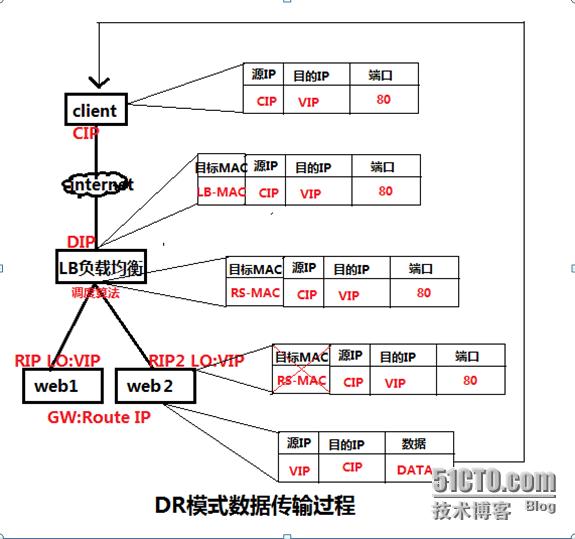
DR模式原理过程简述:
VS/DR模式的工作流程图如上图所示,它的连接调度和管理与NAT和TUN中的一样,它的报文转发方法和前两种不同。DR模式将报文直接路由给目标真实服务器。在DR模式中,调度器根据各个真实服务器的负载情况,连接数多少等,动态地选择一台服务器,不修改目标IP地址和目标端口,也不封装IP报文,而是将请求报文的数据帧的目标MAC地址改为真实服务器的MAC地址。然后再将修改的数据帧在服务器组的局域网上发送。因为数据帧的MAC地址是真实服务器的MAC地址,并且又在同一个局域网。那么根据局域网的通讯原理,真实复位是一定能够收到由LB发出的数据包。真实服务器接收到请求数据包的时候,解开IP包头查看到的目标IP是VIP。(此时只有自己的IP符合目标IP才会接收进来,所以我们需要在本地的回环借口上面配置VIP。另:由于网络接口都会进行ARP广播响应,但集群的其他机器都有这个VIP的lo接口,都响应就会冲突。所以我们需要把真实服务器的lo接口的ARP响应关闭掉。)然后真实服务器做成请求响应,之后根据自己的路由信息将这个响应数据包发送回给客户,并且源IP地址还是VIP。
DR模式小结:
1、通过在调度器LB上修改数据包的目的MAC地址实现转发。注意源地址仍然是CIP,目的地址仍然是VIP地址。
2、请求的报文经过调度器,而RS响应处理后的报文无需经过调度器LB,因此并发访问量大时使用效率很高(和NAT模式比)
3、因为DR模式是通过MAC地址改写机制实现转发,因此所有RS节点和调度器LB只能在一个局域网里面
4、RS主机需要绑定VIP地址在LO接口上,并且需要配置ARP抑制。
5、RS节点的默认网关不需要配置成LB,而是直接配置为上级路由的网关,能让RS直接出网就可以。
6、由于DR模式的调度器仅做MAC地址的改写,所以调度器LB就不能改写目标端口,那么RS服务器就得使用和VIP相同的端口提供服务。
官方三种负载均衡技术比较总结表:
| 工作模式 |
VS/NAT |
VS/TUN |
VS/DR |
| Real server (节点服务器) |
Config dr gw |
Tunneling |
Non-arp device/tie vip |
| Server Network |
Private |
LAN/WAN |
LAN |
| Server number (节点数量) |
Low 10-20 |
High 100 |
High 100 |
| Real server gateway |
Load balance |
Own router |
Own router |
| 优点 |
地址和端口转换 |
Wan环境加密数据 |
性能最高 |
| 缺点 |
效率低 |
需要隧道支持 |
不能跨域LAN |
LVS调度算法
最好参考此文章:http://www.linuxvirtualserver.org/zh/lvs4.html
Lvs的调度算法决定了如何在集群节点之间分布工作负荷。当director调度器收到来自客户端访问VIP的上的集群服务的入站请求时,director调度器必须决定哪个集群节点应该处理请求。Director调度器用的调度方法基本分为两类:
固定调度算法:rr,wrr,dh,sh
动态调度算法:wlc,lc,lblc,lblcr
| 算法 |
说明 |
| rr |
轮询算法,它将请求依次分配给不同的rs节点,也就是RS节点中均摊分配。这种算法简单,但只适合于RS节点处理性能差不多的情况 |
| wrr |
加权轮训调度,它将依据不同RS的权值分配任务。权值较高的RS将优先获得任务,并且分配到的连接数将比权值低的RS更多。相同权值的RS得到相同数目的连接数。 |
| Wlc |
加权最小连接数调度,假设各台RS的全职依次为Wi,当前tcp连接数依次为Ti,依次去Ti/Wi为最小的RS作为下一个分配的RS |
| Dh |
目的地址哈希调度(destination hashing)以目的地址为关键字查找一个静态hash表来获得需要的RS |
| SH |
源地址哈希调度(source hashing)以源地址为关键字查找一个静态hash表来获得需要的RS |
| Lc |
最小连接数调度(least-connection),IPVS表存储了所有活动的连接。LB会比较将连接请求发送到当前连接最少的RS. |
| Lblc |
基于地址的最小连接数调度(locality-based least-connection):将来自同一个目的地址的请求分配给同一台RS,此时这台服务器是尚未满负荷的。否则就将这个请求分配给连接数最小的RS,并以它作为下一次分配的首先考虑。 |
LVS调度算法的生产环境选型:
1、一般的网络服务,如http,mail,mysql等常用的LVS调度算法为:
a.基本轮询调度rr
b.加权最小连接调度wlc
c.加权轮询调度wrc
2、基于局部性的最小连接lblc和带复制的给予局部性最小连接lblcr主要适用于web cache和DB cache
3、源地址散列调度SH和目标地址散列调度DH可以结合使用在防火墙集群中,可以保证整个系统的出入口唯一。
实际适用中这些算法的适用范围很多,工作中最好参考内核中的连接调度算法的实现原理,然后根据具体的业务需求合理的选型。
-----------------后续自我小结--------------------------------------------------
基本上lvs的原理部分就到这里,个人还是觉得像要对LVS有一个比较全面的认识,还是需要去将官方文档认真的看过一遍。主要部分还是在于3种工作方式和8种调度算法。以及实际工作种什么样的生产环境适用哪种调度算法。
-------------------------------------------------------------------------------
来源:oschina
链接:https://my.oschina.net/u/1169079/blog/716987