源伞科技Pinpoint,作为BAT都在使用的一款静态代码分析工具,到底有什么领先于其他厂商的能力?
1. 扩展和部署功能对比
- 源伞科技Pinpoint现有的检查器可以通过简单的json配置文件扩展业务逻辑。比如敏感数据泄露到日志检查器,企业或许有很多自己的日志打印函数,我们可以通过人工配置指定,即可提高检测质量。
- 如果不想人工配置,Pinpoint有未公开发布的库函数学习工具,可以通过线下分析企业代码库自动学习和生成上述配置文件。
- Pinpoint对分布式多机扫描部署支持比Coverity好,并发扫描和结果合并x性能也比Coverity更强,能更好支持BAT级别的数千代码库扫描(已在BT部署验证)。
2. 分析能力对比
本节补充一些人工构造的例子介绍Pinpoint在分析能力上比Coverity强的部分。本节所有代码示例,Coverity均有误报或漏报。
- Pinpoint更懂数据流
- 精确深度的指针分析,深入分析内存中的程序行为
- 高深度高精度函数调用链分析,查找跨越多层函数的深度问题
示例代码如下: (链接:https://www.sourcebrella.com/online-showcase/?id=5b483da03a21cd078346028f),此示例代码基于空指针(Null Pointer Dereference)问题检测。 准备代码:
 代码中我们定义了一个base基类和两个衍生类,其中Derived1的doit函数返回了空指针(见(1))这个空指针随后会被用到。后边我们又定义了一个user类,里边有两个变量,dat1初始化为derived1类型(有空指针),dat2初始化为derived2类型,是安全的(见(2))。user类有一个swap函数交换两个变量的值,每交换一次,dat1和dat2的虚函数doit是否返回空指针会被交换一次,也就是是否安全的信息会被交换一次(见(3))。如果交换两次,实际上相当于没有效果。
然后我们创建confuser类,增加函数调用以及数据流的复杂度,其中所有的swap函数都会交换dat1和dat2的值,我们这里大量使用交换两次的方式,也就是交换再还原的方式,既没有改变任何状态,同时可以增加数据流复杂度(见(4))。最终有SwapData函数交换dat1和dat2, get1函数取dat1的值,get2函数取dat2的值(见(5))。其中get1函数和get2函数各自总计调用54次User::swapData(), 调用链最大长度为6 : get1()->f31()->f21()->f11()->swapData()->swapData1()->User::swapData()。
代码中我们定义了一个base基类和两个衍生类,其中Derived1的doit函数返回了空指针(见(1))这个空指针随后会被用到。后边我们又定义了一个user类,里边有两个变量,dat1初始化为derived1类型(有空指针),dat2初始化为derived2类型,是安全的(见(2))。user类有一个swap函数交换两个变量的值,每交换一次,dat1和dat2的虚函数doit是否返回空指针会被交换一次,也就是是否安全的信息会被交换一次(见(3))。如果交换两次,实际上相当于没有效果。
然后我们创建confuser类,增加函数调用以及数据流的复杂度,其中所有的swap函数都会交换dat1和dat2的值,我们这里大量使用交换两次的方式,也就是交换再还原的方式,既没有改变任何状态,同时可以增加数据流复杂度(见(4))。最终有SwapData函数交换dat1和dat2, get1函数取dat1的值,get2函数取dat2的值(见(5))。其中get1函数和get2函数各自总计调用54次User::swapData(), 调用链最大长度为6 : get1()->f31()->f21()->f11()->swapData()->swapData1()->User::swapData()。
触发空指针的代码如下:
 代码中我们先定义了一个confuser类的对象,同时由构造函数初始化为confuer.user.dat1不安全,confuser.user.dat2安全,然后经过了一系列的交换还原操作(见(6)),dat1和dat2的空指针安全性没有被修改,然后我们进入触发阶段(见(7)),由于没有被修改dat1对应的get1()函数的doit虚函数会返回空指针,而dat2对应的get2函数是安全的,然后我们交换一次(见(8)),结果就相反了,再交换回来(见(9)),结果又还原了。
这里pinpoint可以完全完美还原这里的每个信息,精确找到其中的空指针问题,这里涉及复杂的调用链以及调用关系,复杂的内存数据流(每次confusing.swapData会在内部隐式修改confusing.user.dat1和confusing.user.dat2的值),同变量在不同的程序位置值不相同,以及虚函数对应,每一个都是现有技术很难处理的。因为程序本身的复杂性,精确的建模往往无法规模化,所以很难同时做到深入以及精确的分析。Pinpoint用独创的整体分析技术【Qingkai Shi, Xiao Xiao, Rongxin Wu, Jinguo Zhou, Gang Fan, Charles Zhang. Pinpoint: Scalable and Precise Sparse Value-flow Analysis. PLDI.2018】可以精确分析理解整个流程。
代码中我们先定义了一个confuser类的对象,同时由构造函数初始化为confuer.user.dat1不安全,confuser.user.dat2安全,然后经过了一系列的交换还原操作(见(6)),dat1和dat2的空指针安全性没有被修改,然后我们进入触发阶段(见(7)),由于没有被修改dat1对应的get1()函数的doit虚函数会返回空指针,而dat2对应的get2函数是安全的,然后我们交换一次(见(8)),结果就相反了,再交换回来(见(9)),结果又还原了。
这里pinpoint可以完全完美还原这里的每个信息,精确找到其中的空指针问题,这里涉及复杂的调用链以及调用关系,复杂的内存数据流(每次confusing.swapData会在内部隐式修改confusing.user.dat1和confusing.user.dat2的值),同变量在不同的程序位置值不相同,以及虚函数对应,每一个都是现有技术很难处理的。因为程序本身的复杂性,精确的建模往往无法规模化,所以很难同时做到深入以及精确的分析。Pinpoint用独创的整体分析技术【Qingkai Shi, Xiao Xiao, Rongxin Wu, Jinguo Zhou, Gang Fan, Charles Zhang. Pinpoint: Scalable and Precise Sparse Value-flow Analysis. PLDI.2018】可以精确分析理解整个流程。
- Pinpoint精确分析每个数值
示例代码如下: (链接:https://www.sourcebrella.com/online-showcase/?id=5b483da03a21cd078346028f),此示例代码基于整数溢出(Integer Overflow)问题检测


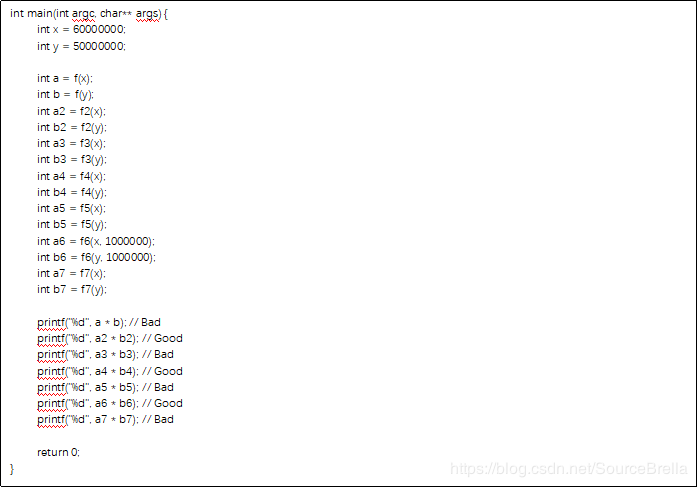 这里我们定义了7个场景,都是跨函数的数值赋值,然后由相应函数处理过的值进行乘积运算是否会越界的问题,其中f1是标准的越界问题,就是两个大数乘积是否越界,f2,f3使用了不同的全局变量做除数对导致不同的越界结果。Pinpoint精确建模了全局变量以及数值运算,并进行完整的约束求解,可以精确区分不同数值的大小。f4到f7同时又引入了程序执行路径的信息,不同的数值可以产生不同的执行路径,而不同的执行路径又可以产生不同的执行结果,pinpoint精确建模了每一个数值,即使是和要检测的目标(这里也就是整数溢出)无关。Pinpoint可以做到用精确的数值信息做执行路径的建模。
这里我们定义了7个场景,都是跨函数的数值赋值,然后由相应函数处理过的值进行乘积运算是否会越界的问题,其中f1是标准的越界问题,就是两个大数乘积是否越界,f2,f3使用了不同的全局变量做除数对导致不同的越界结果。Pinpoint精确建模了全局变量以及数值运算,并进行完整的约束求解,可以精确区分不同数值的大小。f4到f7同时又引入了程序执行路径的信息,不同的数值可以产生不同的执行路径,而不同的执行路径又可以产生不同的执行结果,pinpoint精确建模了每一个数值,即使是和要检测的目标(这里也就是整数溢出)无关。Pinpoint可以做到用精确的数值信息做执行路径的建模。
- Pinpoint精确理解多线程行为
- 精确建模线程间同步机制
- 精确匹配线程之间的共享内存
示例代码如下:
(链接:https://www.sourcebrella.com/online-showcase/?id=5b483da03a21cd078346028f),此示例代码基于数据竞争(Data Race)问题检测
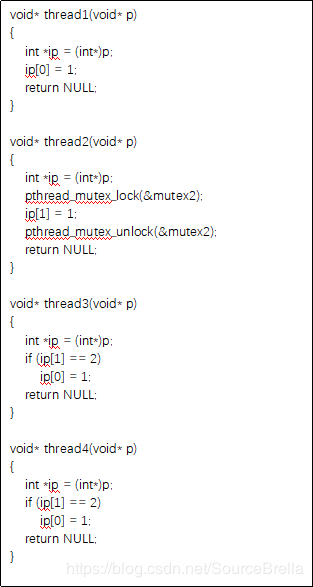
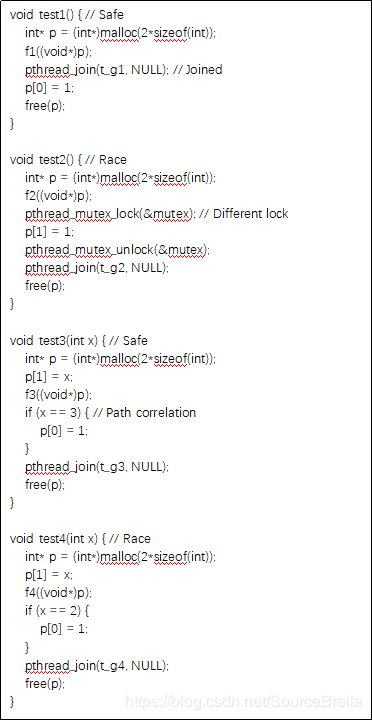
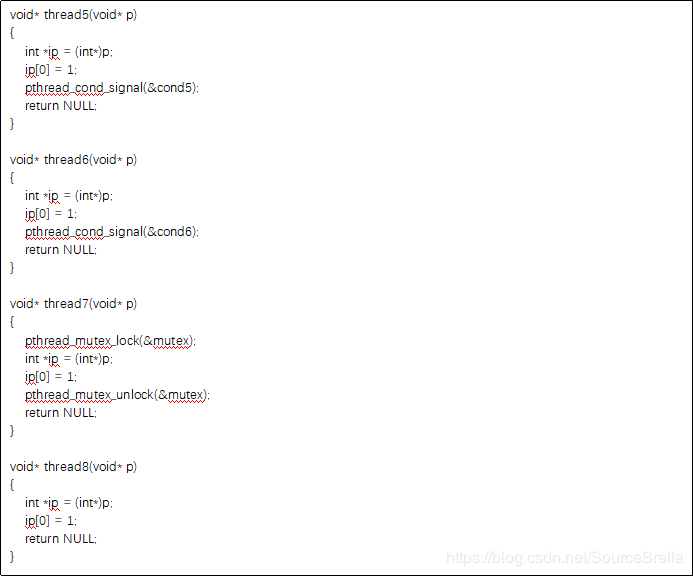
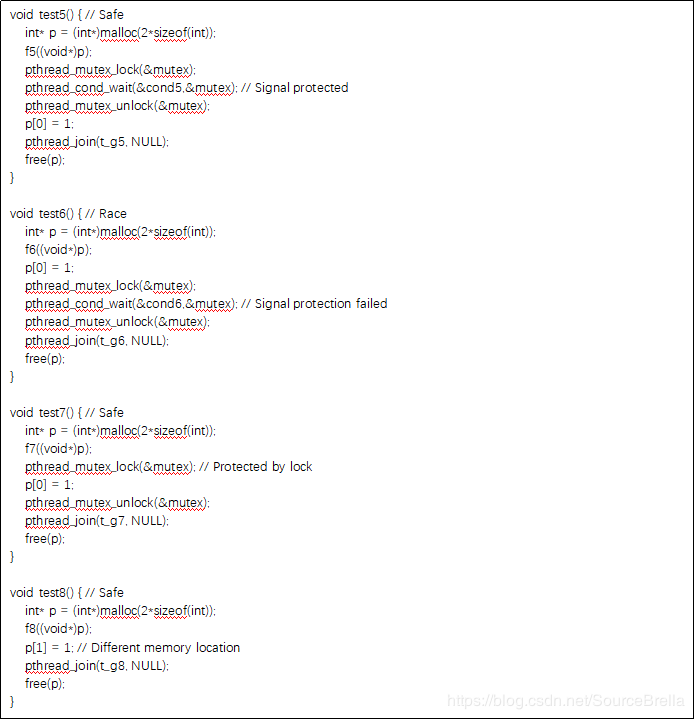 这里共有8个测试用例,包括测试对线程同步的建模(锁:test2, test7,信号:test5, test6, fork-join:test1)另外还有对执行路径了建模(test3,test4)以及共享变量判定(test8)。
对于多线程问题pinpoint精确建模了多线程程序的执行语义,包括线程之间的同步关系。pinpoint可以精确建模函数的调用关系以及精确建模内存结构的能力使得我们有机会可以完整建模多线程的执行语义包括哪些函数可以并发执行,哪些变量是共享变量等。由于线程机制往往要跨越多级函数,涉及共享变量,以及复杂的时序关系,现有工具往往不会深度建模线程语义,也就无法发现深层次多线程问题
这里共有8个测试用例,包括测试对线程同步的建模(锁:test2, test7,信号:test5, test6, fork-join:test1)另外还有对执行路径了建模(test3,test4)以及共享变量判定(test8)。
对于多线程问题pinpoint精确建模了多线程程序的执行语义,包括线程之间的同步关系。pinpoint可以精确建模函数的调用关系以及精确建模内存结构的能力使得我们有机会可以完整建模多线程的执行语义包括哪些函数可以并发执行,哪些变量是共享变量等。由于线程机制往往要跨越多级函数,涉及共享变量,以及复杂的时序关系,现有工具往往不会深度建模线程语义,也就无法发现深层次多线程问题
- Pinpoint精确深度跟踪敏感数据,挖掘深度埋藏的安全隐患
- 后门代码可能被深度埋藏,必须深入精确分析理解程序执行流程才可能发现
- 敏感数据来源和使用点可能距离很远,需要深度跟踪才能发现埋藏很深的问题 示例代码如下: (链接:https://www.sourcebrella.com/online-showcase/?id=5b485a453a21cd0783460294),此示例代码基于相对路径遍历(Relative Path Traversal)问题检测


 这里我们定义了两个类DataStore用来存储数据,Confuser用来处理数据。我们定义DataStore类存储两个数据,一个char* dat存储了一个路径信息,如果路径信息是来自外部输入,那么这里就有可能出现路径遍历安全隐患,makesafe标志如果被置为非零值,那么getDat()函数将无论如何都会返回安全的/dev/null。
Confuser类自定义了3个transfer函数用来传递DataStore中(被污染)的数据,tranfer1-3函数依次调用。如果参数makesafe置为非零值,那么transfer函数将一定会返回安全的数据/dev/null。
在main函数中,我们定义了4个测试。分别对应由于(1)由于dataStore的makesafe置为非零保护危险数据成为安全数据,(2)没有保护危险数据,(3)安全数据,(4)在数据传递过程中进行保护而保证安全的数据。Pinpoint由于有能力完整分析程序中的各个函数以及之间的调用关系,可以完美处理所有示例。
这个例子中的安全问题藏的比较深,而且无法直接手动建模,因为confuser::transfer是用户自定义函数。这样如果没有对于程序执行的深入理解,我们将无法正确的分析confuser::transfer函数的语义,也就没有办法精确查找这样的安全问题。或者无法报出来,或者无法区分那三个实际上安全的情况。
这里我们定义了两个类DataStore用来存储数据,Confuser用来处理数据。我们定义DataStore类存储两个数据,一个char* dat存储了一个路径信息,如果路径信息是来自外部输入,那么这里就有可能出现路径遍历安全隐患,makesafe标志如果被置为非零值,那么getDat()函数将无论如何都会返回安全的/dev/null。
Confuser类自定义了3个transfer函数用来传递DataStore中(被污染)的数据,tranfer1-3函数依次调用。如果参数makesafe置为非零值,那么transfer函数将一定会返回安全的数据/dev/null。
在main函数中,我们定义了4个测试。分别对应由于(1)由于dataStore的makesafe置为非零保护危险数据成为安全数据,(2)没有保护危险数据,(3)安全数据,(4)在数据传递过程中进行保护而保证安全的数据。Pinpoint由于有能力完整分析程序中的各个函数以及之间的调用关系,可以完美处理所有示例。
这个例子中的安全问题藏的比较深,而且无法直接手动建模,因为confuser::transfer是用户自定义函数。这样如果没有对于程序执行的深入理解,我们将无法正确的分析confuser::transfer函数的语义,也就没有办法精确查找这样的安全问题。或者无法报出来,或者无法区分那三个实际上安全的情况。
为国产静态检测工具源伞科技Pinpoint打Call!
来源:oschina
链接:https://my.oschina.net/u/4439431/blog/3159413