此篇代码接着上一篇,这里查看https://blog.csdn.net/qq_42871249/article/details/104456690
模型的保存与载入
先将模型保存的函数调出来,存贮为checkpoint
from keras.callbacks import ModelCheckpoint
checkpoint = ModelCheckpoint(filepath = r'F:\learning_kecheng\deenlearning\NEW\all_zjwj\iris_best.hdf5',
monitor = 'val_acc',
save_best_only = True,
verbose = 1)
建立模型
先建立个简单的模型
model = Sequential()
model.add(Dense(5,input_dim = 4,activation = 'relu'))
model.add(Dense(3,activation = 'softmax'))#softmax保证输出结果为[0,1]
model.compile(loss = 'categorical_crossentropy',
optimizer = 'rmsprop',
metrics = ['accuracy'])
model.fit(irisZX,y,epochs = 50,
validation_data = (irisZX,y),
callbacks = [checkpoint])
储存模型
第一个是存模型,包括模型结构。第二个是只存权重,缺少模型结构。
model.save(r'F:\learning_kecheng\deenlearning\NEW\all_zjwj\iris_best.hdf5')
#只保存权重,缺少模型结构
model.save_weights(r'F:\learning_kecheng\deenlearning\NEW\all_zjwj\iris_best_weights.hdf5')
载入模型
载入模型,后面是载入模型的权重
from keras.models import load_model
model = load_model(r'F:\learning_kecheng\deenlearning\NEW\all_zjwj\iris_best.hdf5')
#载入权重,需要已设定相对应的模型框架
model.load_weights(r'F:\learning_kecheng\deenlearning\NEW\all_zjwj\iris_best_weights.hdf5')
模型的修改
原模型
先看一下模型
model.summary()
将模型的第二层权重赋值给a1
a1 = model.layers[1].get_weights()
type(a1)
a1
权重如下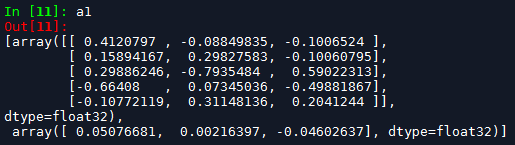
添加模型
在原有模型基础上增加网络层,添加一层
model.add(Dense(3,activation = 'softmax'))
model.summary()
结果如下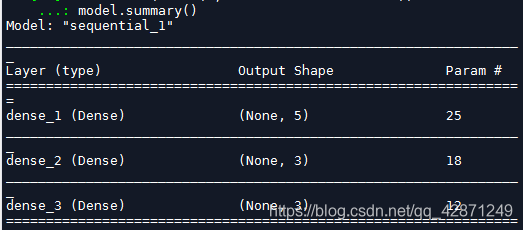
拟合匹配
model.compile(loss = 'categorical_crossentropy',
optimizer = 'rmsprop',
metrics = ['accuracy'])
model.layers[1].get_weights()
model.fit(irisZX,y,epochs = 50)
在sklearn框架内使用Keras模型
拆分训练集和测试集
from sklearn.model_selection import train_test_split
#拆分训练集和测试集
X_train,X_test,y_train,y_test = train_test_split(irisZX,y,
test_size = 0.3,random_state = 111)
#默认shuffle = True
定义可被调用的模型函数
def M_model():
model = Sequential()
model.add(Dense(5,input_dim = 4,activation = 'relu'))
model.add(Dense(3,activation = 'softmax'))
model.compile(loss = 'categorical_crossentropy',
optimizer = 'rmsprop',
metrics = ['accuracy'])
return model
from keras.wrappers.scikit_learn import KerasClassifier
#将所有定义的模型整合入分类器API中
estimator = KerasClassifier(build_fn = M_model,
epochs = 50,verbose = 0)
estimator
#fit函数仍然会返回history对象
hist = estimator.fit(X_train,y_train)
hist.history
拟合结果及预测
estimator.score(X_test,y_test)
estimator.predict(X_test)
拟合结果
预测结果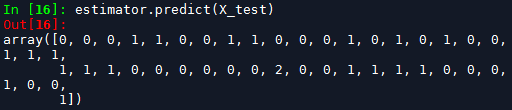
进行交叉验证
from sklearn.model_selection import KFold
kfold = KFold(n_splits = 3,shuffle = True)
from sklearn.model_selection import cross_val_score
results = cross_val_score(estimator,irisZX,y,cv = kfold)
print('模型准确率:%.2f%% (%.2f%%)'%(results.mean()*100,results.std()*100))
来源:CSDN
作者:晓菜成长记
链接:https://blog.csdn.net/qq_42871249/article/details/104465431