论文阅读之FPGA硬件加速
Optimizing the Convolution Operation to Accelerate Deep Neural Networks on FPGA
时间:2018
期刊:IEEE TRANSACTIONS ON VERY LARGE SCALE INTEGRATION (VLSI) SYSTEMS
Section I
本文的主要贡献有:
(1)深入分析卷积运算中的循环计算,通过减少循环层数来加速卷积计算
(2)通过浮点到定点的转换来加速CNN的计算,主要减少存取数据和访问存储器的时间
(3)设计了一个数据路由来处理不同类型的卷积运算,如步长、0填充等,尤其对于irregular CNNs,设计了data router并进行了硬件实现
(4)本文的加速策略在NiN,VGG-16,ResNet等网络架构上进行了验证
Section II
CNN中的循环
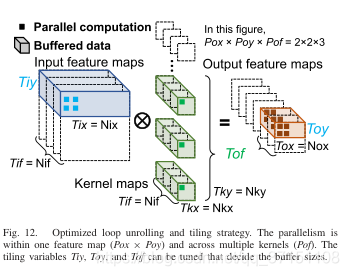
Loop Unrolling 循环展开
剖析CNN中的四层循环
Loop Unrolling循环展开
Loop 1:每一个卷积核内的乘加运算MAC 一个filter中不同位置的数据做MAC
Loop 2:一个filter在所有输入特征图同一像素点的不同通道层(feature map的个数)上的循环 做inner product后相加
Loop 3:一个filter在一张feature map不同位置上的循环(权值共享)
Loop 4:在输出特征图同一位置所有通道上的不同filter的相乘再求和的循环
Loop Tiling循环分块
将所有的输入数据分成n个block,通过合理设计分块的大小可以有效减少DRAM的访问次数
因为访问DRAM时主要的耗时以及功耗所在
Loop Interchange循环交换/互换
两种交换类型
Intertile:on-chip to PEs
Intratile:external memory to on-chip memory
Section III
计算延时
CNN中的计算延时主要取决于MAC,乘法次数的计算: 理想情况下循环次数=总乘法次数除以乘法器的数目 但实际应用中乘法器的利用率达不到百分之百
理想情况下循环次数=总乘法次数除以乘法器的数目 但实际应用中乘法器的利用率达不到百分之百
部分和的存储
部分和存储的是中间结果,比如在同层filter滑动过程中会产生的一系列部分和,Loop 3、Loop 4都有出现。
因此需要将部分和存储下来用于后续循环 以及在PE之间的流动。因此对于部分和的优化在于尽量在本地完成求和 避免数据的移动,能存在片上寄存机就存片上寄存器,如果片上存储存不下一次Loop1 或Loop2的部分和,只能存到片外;另一方面循环的次序对部分和也有影响,Loop1 Loop2进行的越早部分和越少
数据复用
数据复用共两种类型,时间上的和空间上的
spatial reuse:在一个时钟周期内同一位置的像素级权重被多个乘法器使用
temporal reuse:同一位置的像素及权重在多个时钟周期内使用
访问片上缓存
随着数据复用可有效减少片上缓存的访问次数,原来每次乘法都需要读取一个像素及权重,数据复用后,访问次数是原来的1/reuse
Access of On-Chip Buffer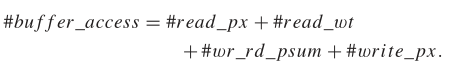
访问片外缓存

本文中最终的权重及中间结果都存在DRAM上,而不是片上缓存BRAM,这使得时延和能耗大大增加。
这就需要有足够大的片上缓存以及合理的安排循环顺序,同一个像素的权重只读取一次,避免从DRAM中多次读取同一个像素及权重。
如果先算Loop3可以有效复用权重数据;如果先算Loop4可以有效复用pixel数据
但将Loop1/2的延后会导致大量部分和的计算
因此二者需要一个trade off
Section IV
Section IV总结了目前的一些循环展开(loop unrolling)的策略
主要有以下四种类型
A:将Loop1、2、4进行展开提高并行度,但由于kernel尺度较小,并行化不太够,以及考虑到实际CNN中每一层的kernel规格都不一样,导致工作负载的不均衡性以及PE的利用率不足,因此就需要针对不同层kernel的规格来配置PE,这样又会增加控制的福阿杜
B:将Loop2、4进行展开,并不能提供足够的并行度导致吞吐量不佳,尤其是对于浅层网络如AlexNet,NiN的影响更大
C:将Loop1、3进行展开,filter中的每一行都完全展开可以复用pixel数据,Loop3展开可以复用weight数据
D:将Loop3、4进行展开因此可以有效复用pixel和weight数据,这种策略可以有效提升并行度
Loop tiling的策略在有限硬件资源上部署大型CNN时用到过,取决于片上缓存的大。同时循环分块的大小以及片外存储二者之间的trade off并未深入研究
Loop Interchange:为由深入研究,但会影响部分和的数目以及存储器的访问次数。
Section V Accelerating Scheme
本文使用的加速策略:
最小化时延
通过设置合理的P / T来提升PE的资源利用率
最小化部分和存储
本尽可能早计算Loop1/2,但本文考虑到数据复用的问题先unroll了Loop3/4
减少片上存储访问
先展开Loop3/4 尽量复用pixel和weight并且存出来local register中
减少外存访问
 通过Fig11可以看出,浅层网络像素数据量大权重数据占比少;网络的深层随着特征的提取,像素数据量变少,权重数据量增多。基于这样的数据分布特点,pixel buffer设计时主要考虑前几层,weight buffer设计时主要考虑后基层。中间层的weight/pixel数据量相当,则是buffer设计的bottleneck。
通过Fig11可以看出,浅层网络像素数据量大权重数据占比少;网络的深层随着特征的提取,像素数据量变少,权重数据量增多。基于这样的数据分布特点,pixel buffer设计时主要考虑前几层,weight buffer设计时主要考虑后基层。中间层的weight/pixel数据量相当,则是buffer设计的bottleneck。
因此本文基于经验设计了合理的buffer size满足以上要求的同时保证了最少的DRAM访问次数。
本文最终的加速器架构
Unroll:Loop1 Loop2
Roll:Loop 3 Loop4
+Loop Tiling
+Loop Interchange
Section VI 硬件实现
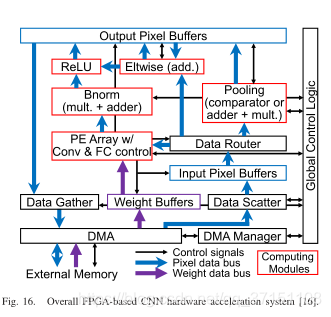
BUF2PE
之前设计register存储像素数据 将相邻位置的像素点存储在相邻的寄存器中,这样当stride=1的读取较为方便但不适合于stride=2等其他情况,因此本文设计了一个BUF2PE的data router来控制buffer数据流向PE
卷积计算单元PE
每一个MAC包含一个乘法器和一个加法器,Loop1/2中没有adder tree.MAC之间共享相邻的weight信息。随后设计偏置的硬件实现
池化层
池化层常用来降低特征图的维度。由于池化只需要pixel数据,因此每次卷积计算完我们直接进行池化操作。池化后的结果再写会到输出的pixel buffer中随后存入外存。
全连接层
全连接层中没有Loop1 Loop3
因此只对Loop4进行展开然后复用MAC。由于FC涉及到大量的权重参数但是运算很少,因此设计两个weight buffer来提升吞吐量
Section VII实验结果分析
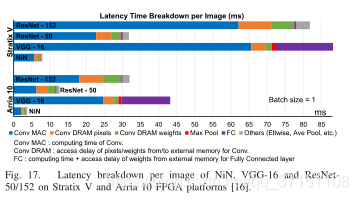
由上图可以看出,MAC占总时延的50% DRAM时间包括卷积权重和输入输出像素,占第二大延时;
FC延时包括计算内积、从DRAM传递FC权重的延时;
其他包括均支持花、流水线等的延时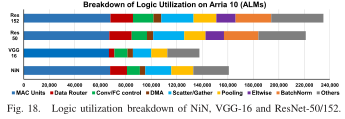
资源利用率分析:
其中MAC中的乘法器主要用来做卷积计算,LE做加法。四种网络(NiN,VGG16,Res50,Res152占用的ALM几乎是一样的,由于VGG16高度一致只需要一个BUF2PE,因此需要更少的BRAM以及LE
其他则是包含系统互联、全局控制逻辑、偏置的加法、配置寄存器
加速结果:
Stratix V:348 GOPS
Arria 10:715 GOPS
Summary
总的来说就是要提升DSP的利用率,网路架构规范(VGG系列等)更好,因为不同层的映射都需要设计,同层的架构一致的话可以资源复用。
另一方面,流水线架构可以提升吞吐量但对时延的改线并不明显;
还有一个常见操作就是浮点到定点的转换,这就涉及到位数和精度的trade off。
来源:CSDN
作者:黄小米吖
链接:https://blog.csdn.net/qq_37151108/article/details/104312102