PCIe基础知识与例程分析
一、 基础知识
1.1 关于接口
PCIe2x接口,对比其他系列,该接口包含2对发送与接收接口,
数据部分包含双向八个接口:
PETp0与PETn0:发送器差动线对,通道0
PETp1与PETn1:发送器差动线对,通道1
PERp0与PERn0:接收器差动线对,通道0
PERp1与PERn1:接收器差动线对,通道1
故链路宽度为2,有几对链路差分对链路宽度即为多大。
1.2 TLP包
1.2.1 AXI-Stream总线上的数据
在赛灵思7系列FPGA中,使用AXIStream总线进行通信,PCIe的TLP包使用AXI总线传输,在AXI总线上数据大端对齐,即高位数据在地址的高位,在传输时AXIS总线上的数据形式:

图1.1 3DW_TLP包

图1.2 4DW_TLP包
What’s more,TLP是Transaction Layer Packet事务层包的检测,关于其详细内容可查看PICe的物理结构,主要是事务层(Transaction Layer)、数据链路层(Data Link Layer)和物理层(Physical Layer)。
事务(处理)层:高层事务源事务源与传送设备的设备核心,结束于接收设备的设备核心,处理层是组装出站处理层数据包的起点,也是接收层拆解入站TLP的终点。在发送数据时,处理层根据设备核心的请求构建TLP头、数据有效载荷和摘要。在发送TLP给数据链路层之前,先使用流控制信任和排列规则,也就是查看接收方有没有足够的接收信用(空间),排列规则就是对任务进行类似优先级处理,确保数据发送的有效执行。
数据链路层:在接收来自事务层的TLP时候,会给其分配一个序列号,并且计算该TLP的链路CRC(包含序列号),然后将TLP传送到物理层。
物理层:进行字节拆分、加扰、编码和串行处理,并在数据包上添加STP和END控制(K)字符,之后从链路的发送端发出数据包。
接收器对数据的处理即为以上的反向操作,但是数据链路层计算CRC检查接受的数据出错时,接收器的数据链路层会发出一个Nack DLLP,通知发送器数据发送错误,此时保存在发送器的数据链路层重放缓冲区的TLP副本就会再次处理并进行发送。
1.2.2 TLP头的格式

上图中标准的TLP包中包含TLP头、TLP数据(DATA)和TLP Digest(摘要)。R表示reserved,保留。
TLP头中,根据头可以确定的事物参数有:事务类型、预期的接受者的地址和ID等、传送的有效数据负载大小(单位:DW)、顺序属性、缓存一致性属性、流量类别。
TLP数据(DATA):可选字段,0~1024DW,0~4kb。
TLP Digest(摘要):可选,头中的TD位决定,大小总是一个DW(32bit),用于ECRC和数据中毒。
Fmt+Type:组合表示传输的TLP packet的类型。
TC:表示流量类别,从流量类别0~流量类别7,即000~111,用于在进行传输时进行VC传输等级仲裁。
TH:为1时表示当前TLP中含有TPH(没搞懂什么作用)
TD:是否有TLP摘要,指出该数据包是否含有ECRC字段,又称为摘要Digest,该字段位宽为32bit,含有端到端CRC(ECRC),ECRC是处理层在创建出站TLP时生成的,并且是根据整个TLP,从头的第一个字节一直到数据有效负载的最后一个字节(但不包括EP位和type位的bit0,计算ECRC时默认这两位为1)。
EP:数据负载是否有效,poisoned
AT:地址转换,有PCIe总线的地址转换相关(也没太搞懂)
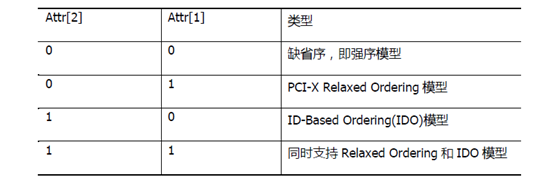
Attr:属性,位于字节2的[5:4],位[5]设置是否采用灵活的顺序,当设置为1时,对于此TLP使用灵活的顺序(Realxed-order),

在使用强序模型时,在数据的整个传送路径中,PCIe设备在处理相同类型的TLP时,如PCIe设备发送两个存储器写TLP时,后面的写TLP必须等待前一个存储器写TLP完成后才能被处理,几遍当前报文在传输过程中阻塞,后一个报文也必须等待。但是对于不同类型的TLP间可以乱序通过同一条PCIe链路。
在使用Realaxed Ordering模型时,后一个写TLP可以越过前一个存储器写TLP提前执行,从而能提高PCIe总线利用率。
Attr的位[1],表示No Snoop Attribute,该位为0时表示当前TLP所传送的数据在通过FSB时需要和Cache保持一致。
Request ID和Tag:在PCIe总线中Request ID和Tag字段合称为Transaction ID,non-posted类型的报文使用Transaction字段的主要目的是使接收端通过分析报文的Transaction ID,确认文成报文的目的地。
Request ID:[15:0],该字段包含生成这个TLP报文的PCIe设备的总线号(Bus Number,[7:0],8bit),设备号(Device Number,[4:0],5bit),功能号(Function Number,[2:0],3bit),对于non-posted类型的请求,目标设备需要使用报文作为回应,在这个完成报文中需要使用源设备Requster ID字段。
在PCIe总线中,所有Non-posted数据请求度需要完成报文进行应答,才能接受一次完整的数据传递。一个源设备发送完non-posted数据请求后,如果美玉接收到目标设备返回的完成报文,TLP报文的发送端需要保存这个non-posted数据请求,此时该设备使用的Trasnction ID(Tag字段)不能再次被使用,直到一次数据传送结束。
PCIe设备发出的每一个non-posted数据请求TLP,在同一个时刻段内Transaction ID必须是唯一的,即在同一时间段内,在当前PCIe总线中不能存在多个存储器请求TLP,其Transaction ID完全相同。
源设备发送non-posted类型的数据请求后,在没有获得全部完成报文之前,不能释放这个Transaction ID所占用的资源,在同一个PCIe设备发送的TLP中,其Request ID字段是相同的,因此PCIe设备的设计者能管理的资源只有Tag字段。PCIe设备的管理者需要合理管理Tag资源以保证数据传输的正确性。
PCIe 设备在发送Non-Posted 数据请求时,需要暂存这些Non-Posted 数据请求。其中Tag 字段的长度决定了发送端能够暂存多少个同类型的TLP,如果Tag 字段长度为5,发送端能够暂存32 个报文;如果PCIe 设备使能了Extended Tag 位,Tag 字段可以由8 位组成,此时发送端能够暂存256 个报文。
1.2.3 TLP的路由
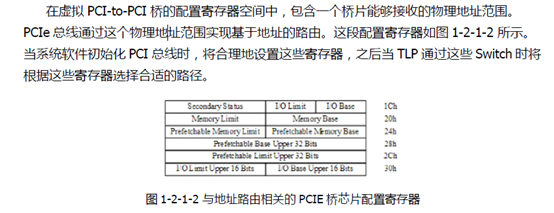
TLP的路由指的是TLP通过Switch或者PCIe桥片时采用哪一条路景,最终到达EP或者RC(Root Complex,跟联合体)的方法,一共有三种:基于地址的路由、基于ID的路由和隐式路由方式。
基于地址路由:存储器和IO读写请求。
基于ID路由:配置读写报文、Cpl和CplD报文,该方式使用PCIe总线好进行路由路径 选择,在switch或者多端口RC的P2P(PCI to PCI)桥配置空间中,使用PCI总线号进行路由路径的选择。
隐式路由:Message报文的传递,指的是从下游端口到上游端口进行数据传递所使用的的路由方式,或者用于RC向EP发出广播报文。注意和物理层通信的控制字K字符区分。
1.3 32bit与64bit操作
寻址空间一般指的是CPU对于内存寻址的能力,也就是最多用到多少个内存的问题,数据在RAM中的存放是有规律的,CPU在运算时根据地址寻找数据的过程就是寻址操作,但是如果地址太多就超出了CPU的寻址能力。
CPU的寻址能力以字节为单位,如32位寻址的CPU可以寻址2的32次方大小的地址也就是4Gb,1kb=1024byte,1mb=1024kb,1gb=1024mb。
二、PIO例程
2.1 demo简介
PIO,即Programmed I/O,是一种设备的数据传输机制,使用特定的IO执行实现从设备到CPU的数据读取。
本节介绍基于7 seriesFPGAs Intergrated Block for PCIe Epress V3.3 ip core的设计,基础内容可以参看上文。
7 series FPGAs Integrated Block for PCI Express core在PIO_demo中被使用,整个demo中分为两个部分,第一部分7 seriesFPGAs Intergrated Block for PCIe Epress V3.3 ip core的设置与例化部分,第二部分为应用部分。

在整个demo中,PCIe ip core用于从电气接口接收和发送数据,然后将接收到的数据通过AXI_Stream总线发送到应用程序部分进行拆包处理,应用程序部分对AXI_Stream总线上的数据的TLP头进行解析,根据解析出来的指令进行相应的操作。对于non_posted类型的数据,经过应用程序处理后通过AXI_Stream总线发送到PCIe ip core,然后将数据通过差动发送器发出到上位机。
2.1 ip core的设置与例化
新建工程,在ip 列表中选择7 seriesFPGAs Intergrated Block for PCIe Epress V3.3 ip core,对于几个参数需要说明:
Mode:选为basic,基本操作。
Lane Width:需要参照接口上含有几对收发差分对。
Maxium Link Speed和AXI Interface Frequency,通过参照IP的技术手册,Page:17,
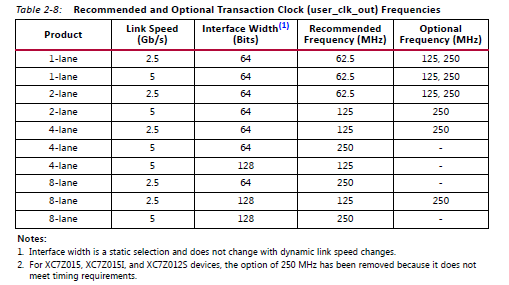
对于7030-2系列,接口的链路宽度为2,连接速度为5.0GT/s时,AXI总线宽度建议选择64bit,AXI总线接口时钟125Mhz。对于其他型号,参考上图。
关于Vender ID(供应商标识):根据IP技术手册介绍:该ID的作用是标识设备或应用程序的供应商,由PC特殊兴趣小组进行分配,以确保每一个标识都是唯一的,默认值为10EE,为Xilinx的供应商ID。
关于Device ID(设备ID):应用程序的唯一标识,默认值取决于所选配置的<link speed><link width>,链路速度与链路宽度,前两位为固定的70,对于7030-2系列设置为7022。
Reference:
Vender ID:Identifies the manufacturer of the device or application. Valid identifiers are assigned by the PCI Special Interest Group to guarantee that each identifier is unique. The default value, 10EEh, is the Vendor ID for Xilinx. Enter a vendor identification number here. FFFFh is reserved.
Device ID:A unique identifier for the application; the default value, which depends on the configuration selected, is 70<link speed><link width>h. This field can be any value;change this value for the application.
2.2 ip core的应用部分
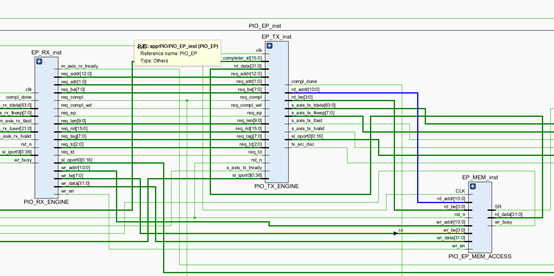
上位机传输的TLP包先到PCIe ip core,之后进行解析,解析的部分为PIO_RX_ENGINE,解析时完全按照AX_Stream协议解析。发送模块为PIO_TX_ENGINE,存储模块为EP_MEM_ACCESS,控制模块为PIO_TO_CTRL。
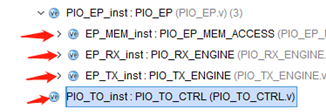
2.2.1 EP_MEM_ACCESS
2.1.1 内容分析
用bram源语一共调用了4块ram,相当于一块存储器,在进行操作时将其视为内存,可以对其进行字节读写与修改。
4块RAM分别为:
ep_io_mem:IO
存储器事务请求可能使用3DW TLP头格式来携带32bit地址,或用4DW TLP头格式来携带64bit地址,IO事务请求限定使用3DW TLP头格式来携带32bit地址。
系统存储器映射能力的大小是设备能够生成的地址范围,PCIe能够寻址32bit或64bit存储器地址空间,虽然多数系统只使用16bit(64kb),但系统IO映射的大小限定在32bit(4GB)。
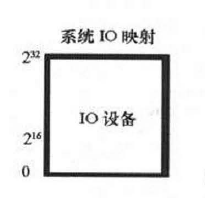
ep_mem32:
对于32bit存储器请求,头中只包含32bit地址,这些TLP的目标设备将驻留在低4GB存储器。(注:地址的低两位bit1:0总为0,表示起始地址总线总是DW校准的)
ep_mem64:
对于64bit存储器请求,头中包含有64bit的地址,这些TLP的目标设备将驻留在高于4GB的存储器范围内。(注:地址的低两位bit1:0总为0,表示起始地址总线总是DW校准的)

ep_mem_erom:
扩展rom,其中包含代码映像,代码映像中又包含设备驱动程序的副本,包含了一个允许在启动期间使用设备的设备驱动程序。
2.2 框架分析
对于内存的操作有内存读取和数据写入。
内存读取
接收到的读取地址为11bit,其中高两位的作用是选择读取操作的RAM类型,根据读取地址信号的高两位进行正确选择读取出的数据。
将读取的地址线[8:0]同时连接到四个ram的读地址线,然后通过了型判断使能对应的RAM读取使能信号。
将读取得到的数据取出来,根据字节使能对数据进行处理,将处理好的数据送到输出数据端口。
数据写入
——与数据读取类似,只不过多了一个wr_en信号。
根据指令的类型确定是操作IO、MEM32、MEM64还是EROM,然后使能写入RAM的读使能的信号将该地址的数据读出。
状态机部分:首先是在空闲状态,在wr_en==1之后进入WAIT状态,该状态的作用是延时一个时钟,之后进入READ状态寄存预读取的数据,之后进入WRITE状态,根据字节使能确定要操作的字节,同时将write_en置一,将数据在下一个时钟周期写入到对应的RAM中。
2.2.2 PIO_RX_ENGINE
接收部分,由两部分构成,一分为操作空间的解析,另一部分为操作指令的解析。
2.1 操作空间
PCIe IP Core解码收到的内存或IO请求的地址,首先需要注意的是在IP core例化构建时并未使能64bit地址,所以64bit内存读取并未使用。
此外,在技术文档有以下说明:(page of 64)
In Endpoint configuration, the core decodes incoming Memory and I/O TLP request addresses to determine which Base Address Register (BAR) in the core Type0 configuration space is being targeted, and indicates the decoded base address on m_axis_rx_tuser[9:2](rx_bar_hit[7:0]). For each received Memory or I/O TLP, a minimum of one bit and a maximum of two (adjacent) bits are set to 1b. If the received TLP targets a 32-bit Memory or I/O BAR, only one bit is asserted. If the received TLP targets a 64-bit Memory BAR, two adjacent bits are asserted. If the core receives a TLP that is not decoded by one of the BARs (that is, a misdirected TLP), then the core drops it without notification and it automatically generates an Unsupported Request message. Even if the core is configured for a 64-bit BAR, the system might not always allocate a 64-bit address,in which case only onerxbar_hit[7:0] signal is asserted. Overlapping BAR apertures are not allowed.
即在进行端点配置时,ip core解码收到的内存或者IO请求的地址,根据地址决定type0配置空间中的基地址寄存器(BAR)被选中,解码的基地址m_axis_rx_tuser[9:2]决定使用哪一个基地址寄存器。对于每一个接收到的内存/IO TLP,m_axis_rx_tuser[9:2]最少有一个、最多有一个bit置为1,具体是一个还是两个取决于操作类型,如果是32bit的内存操作或者是内存IO寻址空间,则需要设置一个bit为1,这意味需要与具体使用的BAR对应。如果是64bit的内存操作,则需要将对应的两个bit置一。
在PIO例程中32bit内存操作时,将m_axis_rx_tuser[2]置一,对EROM进行操作时,将m_axis_rx_tuser[8]置一。

|
assign io_bar_hit_n = 1'b1; //不进行IO操作 assign mem32_bar_hit_n = ~(m_axis_rx_tuser[2]); //p36 assign mem64_bar_hit_n = 1'b1; // 在基地址操作空间0,在ip core中设置未使用64bit操作 assign erom_bar_hit_n = ~(m_axis_rx_tuser[8]); //Expansion ROM扩展ROM地址
always @* begin case ({io_bar_hit_n, mem32_bar_hit_n, mem64_bar_hit_n, erom_bar_hit_n})
4'b0111 : begin //不成立的。因为操作空间只有bar0, region_select <= #TCQ 2'b00; // Select IO region end // 4'b0111
4'b1011 : begin region_select <= #TCQ 2'b01; // Select Mem32 region end // 4'b1011
4'b1101 : begin //不成立的,因为ipcore中bar0未使能64bit操作 region_select <= #TCQ 2'b10; // Select Mem64 region end // 4'b1101
4'b1110 : begin //Expansion ROM region_select <= #TCQ 2'b11; // Select EROM region end // 4'b1110
default : begin region_select <= #TCQ 2'b00; // Error selection will select IO region end // default |
2.2操作指令解析
为了及时接收到来的TLP packet,定义两个寄存器,一个寄存器表示数据包的开始(sop,start of packet),是一个脉冲信号,当数据
2.2.1 解析
对于操作指令的解析由一个case语句分析TLP头中的Fmt+Type位完成,从而确定指令类型:
(1)、localparam PIO_RX_MEM_RD32_FMT_TYPE = 7'b00_00000;//储器读请求;TLP头大小为3个双字,不带数据。
(2)、localparam PIO_RX_MEM_WR32_FMT_TYPE = 7'b10_00000;//存储器写请求;TLP头大小为3个双字,带数据。
(3)、localparam PIO_RX_MEM_RD64_FMT_TYPE = 7'b01_00000;//储器读请求;TLP头大小为4个双字,不带数据。
(4)、localparam PIO_RX_MEM_WR64_FMT_TYPE = 7'b11_00000;//存储器写请求;TLP头大小为4个双字,带数据。
(5)、 localparam PIO_RX_IO_RD32_FMT_TYPE = 7'b00_00010;//IO读请求;TLP头大小为3个双字,不带数据
(6)、localparam PIO_RX_IO_WR32_FMT_TYPE = 7'b10_00010;//IO写请求;TLP头大小为3个双字,带数据
2.2.2 操作
(一)、指令的深入操作:
解析出操作指令后将跳转到对应的指令执行状态,接下来将逐一讲解各个指令的执行:
(1)、为了表示一个TLP数据包的开始,首先需要一个sop(start of packet),该信号在发送方valid信号有效时且未进行数据传输时表示开始接收数据,在他从0变为1时已经接收到了数据,接收到数据之后需要将ready拉低,
(2)、在开始接收数据之后,什么时候数据进入?就是在接收方的ready信号有效时,使用一个信号in_packet_q表示正在进行数据传输。该信号滞后于传输数据一个周期,因为接收方的ready信号为1时才将其在下一个时钟周期置一,但是他是和传输的数据有效时间长度是一样的,因为他在发送方的tlast信号为1的下一个时钟上升沿拉高,在数据结束的下一个时钟周期结束。
即假设数据传输的周期个数为:n,那么in_packet_q的为高周期个数为:n。
(二)、空闲状态:
将ready拉高等待数据传输的到来,当数据到来时(if(sop)),根据Fmt+Type对指令执行区分,关闭接收ready,并跳转到对应的状态处理函数。
case (m_axis_rx_tdata[30:24]) //根据数据包类型进行数据包分析
1、 PIO_RX_MEM_RD32_FMT_TYPE
接收到一个32位的存储器读请求,将TLP类型保存(有用),保存要读取的数据长度,PIO传输的长度为1DW,即32bit,然后判断要请求的数据是不是一个DW,是的话就将属性也寄存起来,然后跳转到处理函数。
2、 PIO_RX_MEM_WR32_FMT_TYPE
存储器写请求;TLP头大小为3个双字,带数据。该指令不需要回传一个数据包,只需要保存数据包的类型与长度,然后根据长度判断是不是一个DW,是的话就保存字节使能位,然后跳转到处理函数。
3、 PIO_RX_MEM_RD64_FMT_TYPE
存储器读请求;TLP头大小为4个双字,不带数据。第一个数据为低32位地址,第二个数据为高32位地址。
4、 PIO_RX_MEM_WR64_FMT_TYPE
存储器写请求;TLP头大小为4个双字,带数据,
5、 PIO_RX_IO_RD32_FMT_TYPE
IO读请求;TLP头大小为3个双字,不带数据,寄存属性,跳转到处理函数。
6、 PIO_RX_IO_WR32_FMT_TYPE
IO写请求;TLP头大小为3个双字,带数据。
处理函数
注意,这部分函数是在上一个函数的下一个时钟周期执行的,上一个时钟周期已经将接收方的ready信号拉低了,本次再次拉低有点多余或许有别的考虑…..在发送方的valid信号有效时进行指令处理操作,为什么tvalid不为零?没太搞懂,
Update:一次完整的数据传输完成之后tvalid才失效。Maybe
(1)、PIO_RX_MEM_RD32_DW1DW2
在发送方的Tvalid有效时,将接收方的ready信号拉低,将请求的地址提取出来,前两位是要读取的内存区域,读取地址的低两位是0,因为地址是DW对齐的。
32bit内存读取请求需要有返回的数据,是non_posted类型的执行,所以设置请求读完毕信号标志和请求完成等待数据标志。
之后跳转到等待状态等待数据返回完毕(是使用了一个compl_done信号)。
(2)、PIO_RX_MEM_WR32_DW1DW2
接收到的是内存写入数据信号指令,32bit的,将数据寄存器来,同时使能数据写入内存,提取操作地址,等待数据接收完成,在写入完成时候返回到空闲IDLE状态(使用了一个wr_busy信号)。
(3)、PIO_RX_MEM_RD64_FMT_TYPE
存储器读请求;TLP头大小为4个双字,不带数据。但是一次传输就64bit,那么还需要第二次传输,提取出地址数据,并设置指令读取完成和等待数据信号,在状态机PIO_RX_MEM_RD64_DW1DW2中。
(4)、PIO_RX_MEM_WR64_FMT_TYPE
存储器写请求;TLP头大小为4个双字,带数据。与上类似,在第二传输中获取写入地址,并等待数据写入完成,同样使用的是wr_busy信号。
(5)、PIO_RX_IO_RD32_FMT_TYPE
IO读请求;TLP头大小为3个双字,不带数据,跳转到PIO_RX_MEM_RD32_DW1DW2内存读取状态。
(6)、PIO_RX_IO_WR32_FMT_TYPE
IO写请求;TLP头大小为3个双字,带数据。寄存属性,然后跳转到PIO_RX_IO_WR_DW1DW2,从数据中提取出操作地址,之后等待IO写入完成。此外,IO写请求时non-posted类型,还需要返回完成指令,但是不带数据,所以需要将req_compl=1,req_compl_wd=0。
2.2.3 PIO_TX_ENGINE
对于读取和IO类别的信号需要返回数据,将数据在TX发送引擎组包后,通过AXI-Stream总线发送到PCIe ip core,ip core再将TLP通过处理后发到上位机。
3.1 信号分析
几个重要信号,首先是output类型的tx_src_dsc,全名是source discontinue,Discontinuing Transmisson of Transaction by Source,发送源中断,在使用手册page of 52中说明,AXI-Stream接口允许使用tx_src_dsc发送源中观,可以在帧开始第一个周期后的任意时刻,包括置位talst信号时声明源中断,,进而终止TLP的传输,但是在该demo中,tx_src_dsc设置为0,因为传输一次完成(32bit data,个人理解),此外,s_axis_tx_valid和s_axis_tx_tready必须与tx_src_dsc一起断言(assert),以终止TP传输。
reg [11:0] byte_count;字节计数器,传输32bit数据,一个DW即可完成,此外,在BE字段中不可有间断的1,所以有根据rd_be计算传输多少字节。
根据完成包的类型,如果当前完成报文为存储器读完成TLP,TLP格式为:
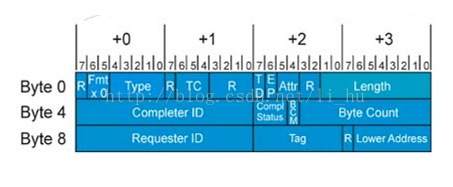
Tmt、Type、TC、TD、EP、Attr、Length、completer_id与接收引擎中解包出的数据一致。
Status字段保存当前完成报文的完成状态,表示当前TLP是否正确的将数据发送给数据请求端(3’b 000,正常结束),还是在数据传递过程中出现错误(3’b 001,不支持的数据请求),还是要求发送请求方重试(3’b010),还是数据夭折(3’b100)。
Byte count:记录源设备还需要从目标设备中获取多少字节的数据,本demo中置一即可,一次就over了。
Lower address:如果当前完成报文为存储器读完成TLP,该字段存放TLP中第一个数据所对应的的地址。
其他见上文。
3.2 状态机分析
复位之后将AXI信号复位,忙与忙完成寄存器清零。Else,判断是否需要发送完成包,需要的话就将忙标志置一,状态机:
(1)、PIO_TX_RST_STATE
空闲状态,如果忙标志为1,AXI总线初始化,接收方准备好之后进入下一状态。
(2)、PIO_TX_CPLD_QW1_FIRST
对数据进行组TLP包,然后进入下一状态。
(3)、PIO_TX_CPLD_QW1_TEMP
TLP头已组包好,将valid置一,开始发送,之后进入下一状态。
(4)、PIO_TX_CPLD_QW1
发送完头之后该发送数据了,对数据组包,传输一次完成,将tlast置一。同时根据是否有数据设置tkeep字节使能。下一时钟周期数据发送到ip core,回到空闲状态。
2.2.4 PIO_TO_CTRL
热插拔管理模块,主要是四个信号
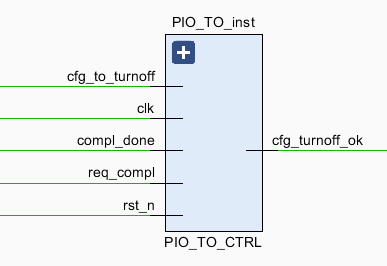
Cfg_to_turnoff:由PCIe ip core发出,通知已经收到PME_TURN_OFF信号的输出,CMM开始轮询传入的cfg_turnoff_ok输入,当cfg_turnoff_ok有效时,CMM向上游设备发送PME_TURN_OFF信号。
Cfg_turnoff_ok:通过声明该信号通知用户应用程序端点可断电。
Compel_done:返回包操作完成。
Req_compl:TLP头解析完成。
根据是否有TLP头解析完成信号判断传输悬浮状态。没有的话根据cfg_to_turnoff进行设置。(该部分位于说明书31page)
三、 关于状态机编码:
使用二进制编码
优点:
需要的触发器个数少。
缺点:
(1)、状态译码需要额外的组合逻辑
(2)、对状态译码时需要增加额外的组合逻辑,从而在定时路径上增加了额外延迟。
(3)、不适用于工程设计变更
(4)、有时状态触发器和其他逻辑合在一起,是的特定状态的推导变得困难。
使用杜热码
优点:
(1)、状态编码的组合逻辑较少
(2)、状态信息用单个触发器表示,具有良好的定时裕量,对状态译码的定时器路径中不需要额外的组合逻辑。
(3)、适用于工程设计变更:
——状态信息得以保持,即综合后的所有触发器都将会被保留。
——状态变量易于读取,方便使用,修改某一状态的方程容易。
——
缺点:
需要的触发器个数多。
来源:https://www.cnblogs.com/luxinshuo/p/12290859.html