在Nextflow中,进程是执行用户脚本的基本处理原语。
进程定义以关键字开头process,其后是进程名称,最后是 由括号括起来的进程主体。进程主体必须包含一个表示命令的字符串,或更一般地,该字符串代表由该命令执行的脚本。基本过程如下例所示:
process sayHello {
"""
echo 'Hello world!' > file
"""
}
一个流程可能分别包含五个定义块:指令,输入,输出,when子句以及最后一个流程脚本。语法定义如下:
process < name > {
[ directives ]
input:
< process inputs >
output:
< process outputs >
when:
< condition >
[script|shell|exec]:
< user script to be executed >
}
1 脚本
该脚本块是一个字符串声明,它定义了由过程执行到执行任务的命令。
一个进程仅包含一个脚本块,并且当该进程包含输入和输出声明时,它必须是最后一个语句。
输入的字符串在主机系统中作为Bash脚本 执行。它可以是通常在终端外壳程序或通用Bash脚本中使用的任何命令,脚本或它们的组合。
可以在脚本语句中使用的命令的唯一限制是目标执行系统中这些程序的可用性。
脚本块可以是简单字符串或多行字符串。后者简化了由跨越多行的多个命令组成的非平凡脚本的编写。例如:
process doMoreThings {
"""
blastp -db $db -query query.fa -outfmt 6 > blast_result
cat blast_result | head -n 10 | cut -f 2 > top_hits
blastdbcmd -db $db -entry_batch top_hits > sequences
"""
}
如脚本教程部分中所述,可以通过使用单引号或双引号定义字符串,并通过三个单引号或三个双引号字符定义多行字符串。
它们之间有细微但重要的区别。像在Bash中一样,以字符分隔的字符串"支持变量替换,而以字符分隔的字符串'则不支持。
在上面的代码片段中,$db变量被替换为管道脚本中某个地方定义的实际值。
当您需要在脚本中访问系统环境变量时,有两个选择。首选就像使用单引号字符串定义脚本块一样容易。例如:
process printPath {
'''
echo The path is: $PATH
'''
}
该解决方案的缺点是,您将无法在脚本块中访问在管道脚本上下文中定义的变量。
要解决此问题,请使用双引号字符串定义脚本,并通过在系统环境变量前添加反斜杠字符来对其进行转义\,如以下示例所示:
process doOtherThings {
"""
blastp -db \$DB -query query.fa -outfmt 6 > blast_result
cat blast_result | head -n $MAX | cut -f 2 > top_hits
blastdbcmd -db \$DB -entry_batch top_hits > sequences
"""
}
在此示例$MAX中,必须在管道脚本之前的某个位置定义变量。 在执行脚本之前,Nextflow用实际值替换它。相反,该$DB变量必须存在于脚本执行环境中,并且Bash解释器将其替换为实际值。
1.1 点菜脚本(Scripts à la carte)
默认情况下,Nextflow将流程脚本解释为Bash脚本,但您不仅限于此。
您可以使用自己喜欢的脚本语言(例如Perl,Python,Ruby,R等),甚至可以将它们混合在同一管道中。
管道可以由执行非常不同的任务的进程组成。使用Nextflow,您可以选择更适合指定进程执行的任务的脚本语言。例如,对于某些进程,R可能比Perl有用,在其他进程中,您可能需要使用Python,因为它提供了对库或API等的更好访问。
要使用Bash以外的脚本,只需使用相应的shebang声明启动流程脚本 。例如:
process perlStuff {
"""
#!/usr/bin/perl
print 'Hi there!' . '\n';
"""
}
process pyStuff {
"""
#!/usr/bin/python
x = 'Hello'
y = 'world!'
print "%s - %s" % (x,y)
"""
}
1.2 条件脚本
复杂的过程脚本可能需要评估对输入参数的条件,或使用传统的流量控制语句(即if,switch等),以执行特定的脚本命令,根据当前输入的配置。
流程脚本可以通过简单地在脚本块前面加上关键字来包含条件语句script:。通过这样做,解释器将评估以下所有语句作为代码块,该代码块必须返回要执行的脚本字符串。比解释起来容易使用,例如:
seq_to_align = ...
mode = 'tcoffee'
process align {
input:
file seq_to_aln from sequences
script:
if( mode == 'tcoffee' )
"""
t_coffee -in $seq_to_aln > out_file
"""
else if( mode == 'mafft' )
"""
mafft --anysymbol --parttree --quiet $seq_to_aln > out_file
"""
else if( mode == 'clustalo' )
"""
clustalo -i $seq_to_aln -o out_file
"""
else
error "Invalid alignment mode: ${mode}"
}
在上面的示例中,该过程将根据mode参数的值执行脚本片段。默认情况下它将执行tcoffee命令,将mode变量更改为mafft or clustalo值,其他分支将被执行。
1.3 模板(Template)
可以使用模板文件将流程脚本外部化,该模板文件可以在不同的流程之间重复使用,并可以通过整体管道执行独立地进行测试。
模板只是Nextflow可以通过使用如下template功能执行的shell脚本文件:
process template_example {
input:
val STR from 'this', 'that'
script:
template 'my_script.sh'
}
Nextflow my_script.sh在目录templates中寻找模板文件,该目录必须存在于Nextflow脚本文件所在的文件夹中(可以使用绝对模板路径提供任何其他位置)。
模板脚本可以包含基础系统可以执行的任何代码。例如:
#!/bin/bash
echo "process started at `date`"
echo $STR
:
echo "process completed"
注意:请注意$,当脚本作为Nextflow模板运行时,美元字符($)被解释为Nextflow变量占位符。
1.4 Shell
该shell块是一个字符串语句,用于定义由进程执行以执行其任务的shell命令。它是Script定义的替代方案,但有一个重要区别,它使用感叹号!字符作为Nextflow变量的变量占位符,代替了通常的美元字符。
这样,可以在同一段代码中同时使用Nextflow和Bash变量,而不必逃避后者,并使流程脚本更具可读性和易于维护。例如:
process myTask {
input:
val str from 'Hello', 'Hola', 'Bonjour'
shell:
'''
echo User $USER says !{str}
'''
}
在上面的琐碎示例中,$USER变量由Bash解释器管理,而!{str}作为由Nextflow管理的流程输入变量进行处理。
2 本地运行
Nextflow进程可以执行除系统脚本以外的本机代码,如前几段所示。
这意味着,您无需指定要作为字符串脚本执行的process命令,而是可以通过提供一种或多种语言语句来定义它,就像在其余管道脚本中一样。只需使用exec:关键字启动脚本定义块,例如:
x = Channel.from( 'a', 'b', 'c')
process simpleSum {
input:
val x
exec:
println "Hello Mr. $x"
}
打印:
Hello Mr. b
Hello Mr. a
Hello Mr. c
3 输入项
Nextflow进程彼此隔离,但可以在自己之间通过通道发送值进行通信。
该输入块定义哪些信道的过程中期望着从接收输入数据。您一次只能定义一个输入块,并且它必须包含一个或多个输入声明。
输入块遵循以下语法:
input:
<input qualifier> <input name> [from <source channel>] [attributes]
输入定义以输入限定符和输入名称开头,然后是关键字from和接收输入的实际通道。最后,可以指定一些输入可选属性。
输入限定符声明要接收的数据类型。Nextflow使用此信息来应用与每个限定符相关的语义规则,并根据目标执行平台(网格,云等)正确处理它。
可用的限定符是下表中列出的限定符:
| 限定符 | 语义 |
|---|---|
| val | 使您可以按过程脚本中的名称访问收到的输入值。 |
| env | 使您可以使用接收到的值来设置名为指定输入名称的环境变量。 |
| file | 使您可以将接收到的值作为文件来处理,并在执行上下文中对其进行适当的暂存。 |
| path | 使您可以将接收到的值作为路径来处理,从而在执行上下文中正确地暂存文件。 |
| stdin | 使您可以将接收到的值转发到进程stdin特殊文件。 |
| tuple | 使您可以处理具有上述限定符之一的一组输入值。 |
| each | 使您可以对输入集合中的每个条目执行该过程。 |
3.1 输入数字
这个val限定符允许接收任何类型的数据作为输入。可以通过使用指定的输入名称在流程脚本中访问它,如以下示例所示:
num = Channel.from( 1, 2, 3 )
process basicExample {
input:
val x from num
"echo process job $x"
}
在上面的示例中,该过程执行了三次,每次从通道接收到一个值num 并用于处理脚本。因此,其输出类似于以下所示:
process job 3
process job 1
process job 2
如果与val接收数据的通道具有相同的名称,则from可以省略该部分。因此,上面的示例可以写成如下所示:
num = Channel.from( 1, 2, 3 )
process basicExample {
input:
val num
"echo process job $num"
}
3.2 文件输入
在file限定符中允许文件值的过程中执行上下文处理。这意味着Nextflow会将其暂存在流程执行目录中,并且可以使用输入声明中指定的名称在脚本中对其进行访问。例如:
proteins = Channel.fromPath( '/some/path/*.fa' )
process blastThemAll {
input:
file query_file from proteins
"blastp -query ${query_file} -db nr"
}
在上面的示例中,所有以后缀结尾的文件.fa都是通过通道发送的proteins。然后,这些文件将由该进程接收,该进程将对每个文件执行BLAST查询。
当文件输入名称与通道名称相同时,from可以省略输入声明的一部分。因此,上面的示例可以写成如下所示:
proteins = Channel.fromPath( '/some/path/*.fa' )
process blastThemAll {
input:
file proteins
"blastp -query $proteins -db nr"
}
值得注意的是,在上面的示例中,文件系统中的文件名没有被触及,即使您不知道文件名也可以访问该文件,因为您可以使用指定了名称的变量在流程脚本中对其进行引用在输入文件的参数声明中。
在某些情况下,您的任务需要使用名称固定的文件,而不必与实际提供的文件一起更改。在这种情况下,可以通过name在输入文件参数声明中指定属性来指定其名称,如以下示例所示:
input:
file query_file name 'query.fa' from proteins
或者使用较短的语法:
input:
file 'query.fa' from proteins
使用此方法,可以如下所示重写前面的示例:
proteins = Channel.fromPath( '/some/path/*.fa' )
process blastThemAll {
input:
file 'query.fa' from proteins
"blastp -query query.fa -db nr"
}
在此示例中发生的是,进程接收到的每个文件都query.fa在不同的执行上下文(即,执行作业的文件夹)中暂存了该名称,然后启动了独立的进程执行。
3.3 多个输入文件
进程可以声明一个发出值集合(而不是简单值)的通道作为输入文件。
在这种情况下,由输入文件参数定义的脚本变量将保存文件列表。您可以如前所示使用它,可以引用列表中的所有文件,也可以使用通常的方括号表示法访问特定条目。
当在输入参数中定义了目标文件名并且该进程接收到文件集合时,该文件名将附加一个数字后缀,以表示其在列表中的顺序位置。例如:
fasta = Channel.fromPath( "/some/path/*.fa" ).buffer(size:3)
process blastThemAll {
input:
file 'seq' from fasta
"echo seq*"
}
将输出:
seq1 seq2 seq3
seq1 seq2 seq3
...
目标输入文件名可以包含*和?通配符,可用于控制暂存文件的名称。下表显示了如何根据接收到的输入集合的基数替换通配符。
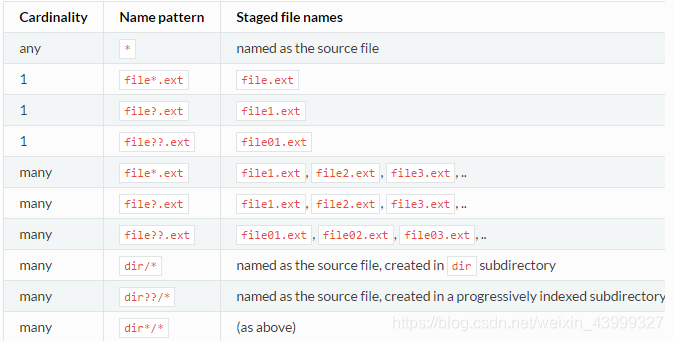
以下片段显示了如何在输入文件声明中使用通配符:
fasta = Channel.fromPath( "/some/path/*.fa" ).buffer(size:3)
process blastThemAll {
input:
file 'seq?.fa' from fasta
"cat seq1.fa seq2.fa seq3.fa"
}
3.4 动态输入文件名
使用name file子句或短字符串表示法指定输入文件名时,可以将其他输入值用作文件名字符串中的变量。例如:
process simpleCount {
input:
val x from species
file "${x}.fa" from genomes
"""
cat ${x}.fa | grep '>'
"""
}
在上面的示例中,输入文件名是通过使用x输入值
这允许在脚本工作目录中使用与当前执行上下文相一致的名称来分阶段输入文件。
3.5 输入“路径”
path输入限定符被Nextflow版本19.10.0引入,这是一个简易替换为file限定符,因此它是后向兼容的语法和用于输入语义file如上所述。
file和path之间的重要区别是,第一个期望输入的值是文件对象。当输入是其他类型时,它会自动转换为字符串并将其保存到临时文件中。在某些用例中这可能很有用,但在大多数情况下却很棘手。
所述path限定词代替解释字符串值作为输入文件的路径位置,并自动转换为一个文件对象。
process foo {
input:
path x from '/some/data/file.txt'
"""
your_command --in $x
"""
}
该选项stageAs使您可以控制如何在任务工作目录中命名该文件,并提供一个特定名称或名称模式,如“ 多个输入文件” 部分所述:
process foo {
input:
path x, stageAs: 'data.txt' from '/some/data/file.txt'
"""
your_command --in data.txt
"""
}
3.6 输入“ stdin”
stdin输入限定允许您从一信道接收到所述值的转发 标准输入 由所述处理中执行的命令的。例如:
str = Channel.from('hello', 'hola', 'bonjour', 'ciao').map { it+'\n' }
process printAll {
input:
stdin str
"""
cat -
"""
}
它将输出:
hola
bonjour
ciao
hello
3.7 输入‘env’
env限定符允许定义基于从信道接收到的值的过程中的执行上下文的环境变量。例如:
str = Channel.from('hello', 'hola', 'bonjour', 'ciao')
process printEnv {
input:
env HELLO from str
'''
echo $HELLO world!
'''
}
hello world!
ciao world!
bonjour world!
hola world!
3.8 输入“ tuple”
在tuple预选赛中,您可以将多个参数一个参数的定义。当流程在输入中接收需要单独处理的值的元组时,这将很有用。元组中的每个元素都与具有tuple定义的相应元素相关联。例如:
values = Channel.of( [1, 'alpha'], [2, 'beta'], [3, 'delta'] )
process tupleExample {
input:
tuple val(x), file('latin.txt') from values
"""
echo Processing $x
cat - latin.txt > copy
"""
}
在上面的示例中,tuple参数用于定义值x和文件latin.txt,文件将从同一通道接收值。
在tuple声明的项目可以通过使用下面的限定词来定义:val,env,file和stdin。
通过应用以下替换规则,可以使用较短的符号: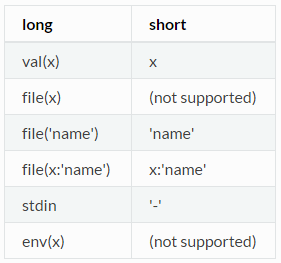
因此,前面的示例可以重写如下:
values = Channel.of( [1, 'alpha'], [2, 'beta'], [3, 'delta'] )
process tupleExample {
input:
tuple x, 'latin.txt' from values
"""
echo Processing $x
cat - latin.txt > copy
"""
}
3.9 输入中继器
这个each限定符允许您在每次收到新数据时对集合中的每个项重复执行进程。例如:
sequences = Channel.fromPath('*.fa')
methods = ['regular', 'expresso', 'psicoffee']
process alignSequences {
input:
file seq from sequences
each mode from methods
"""
t_coffee -in $seq -mode $mode > result
"""
}
在上面的示例中,每次过程接收到序列文件作为输入时,该文件都会执行三个任务,这些任务运行带有不同mode参数值的T-coffee对齐。当您需要为一组给定的参数重复相同的任务时,这很有用。
由于0.25+版以上的输入中继器也可以应用于文件。例如:
sequences = Channel.fromPath('*.fa')
methods = ['regular', 'expresso']
libraries = [ file('PQ001.lib'), file('PQ002.lib'), file('PQ003.lib') ]
process alignSequences {
input:
file seq from sequences
each mode from methods
each file(lib) from libraries
"""
t_coffee -in $seq -mode $mode -lib $lib > result
"""
}
在后面的示例中,对于sequences通道发出的任何序列输入文件,将执行6个比对,其中3个regular针对每个库文件使用该方法,其他3个expresso始终针对同一库文件使用该方法。
3.10 了解多个输入通道的工作方式
进程的关键特征是能够处理来自多个通道的输入。
当将两个或多个通道声明为过程输入时,过程将停止,直到存在完整的输入配置即。它从所有声明为输入的通道接收输入值。
验证此条件后,它将消耗来自各个通道的输入值,并生成任务执行,然后重复相同的逻辑直到一个或多个通道不再有内容。
这意味着通道值是一个接一个地连续消耗的,即使其他通道中还有其他值,第一个空通道也会导致进程执行停止。
例如:
process foo {
echo true
input:
val x from Channel.from(1,2)
val y from Channel.from('a','b','c')
script:
"""
echo $x and $y
"""
}
该过程foo执行两次,因为第一个输入通道仅提供两个值,因此c元素被丢弃。它打印:
1 and a
2 and b
这种通道是通过Channel.value工厂方法创建的,或者在过程输入在from子句中指定简单值时隐式创建的。
根据定义,值通道绑定到单个值,并且可以无限制地读取该值而不消耗其内容。
这些属性使得将值通道与一个或多个(队列)通道混合时,不会影响仅取决于其他通道的过程终止,并且其内容会重复应用。
为了更好地理解此行为,请将前面的示例与以下示例进行比较:
process bar {
echo true
input:
val x from Channel.value(1)
val y from Channel.from('a','b','c')
script:
"""
echo $x and $y
"""
}
上面的代码段执行该bar过程三次,因为第一个输入是一个值通道,因此可以根据需要读取其内容多次。进程终止由第二通道的内容确定。它打印:
1 and a
1 and b
1 and c
来源:CSDN
作者:二进制杯莫停
链接:https://blog.csdn.net/weixin_43999327/article/details/104197841