Python基础语法体系
一:基本数据类型及操作
(一)基本数据类型
1.整数类型
- 整数类型一共有4种进制表示:十进制、二进制、八进制和十六进制
默认情况,整数采用十进制,其他进制需要增加引导符号(大小写字母均可使用)。
- 整数类型理论上取值范围是[-∞,∞],实际上的取值范围受限于运行Python程序的计算机内存大小。除极大数的运算外,一般认为整数类型没有取值范围限制。

2.浮点数类型
- Python语言要求所有浮点数必须带有小数部分,小数部分可以是0,这种设计是为了区分浮点数和整数类型。
- 浮点数有两种表示方法:十进制表示法和科学技术表示法
- 科学计数法使用字母e或E作为幂的符号,以10位基数,含义如下:
例如:2.5e-3的值为0.0025; 8.5E5的值是850000.0 - 浮点数类型和小数类型由计算机的不同硬件单元执行,处理方法不同,需要注意的是,尽管浮点数0.0和整数0大小相等,但他们在计算机内部表示不同。
- Python浮点数的数值范围和小数精度受不同计算机系统的限制,sys.float_info详细列出了Python解释器所运行系统的浮点数各项参数,例如
- 上述输出给出浮点数类型所能表示的最大值(max)、最小值(min),科学计数法表示下最大值的幂(max_ 10 exp)、 最小值的幂(min 10_ exp), 基数(radix) 为2时最大值的幂(max exp)、 最小值的幂(min_ _exp), 科学计数法表示中系数a的最大精度(mant _dig), 计算机所能分辨的两个相邻浮点数的最小差值( epsilon),能准确计算的浮点数最大个数(dig)。
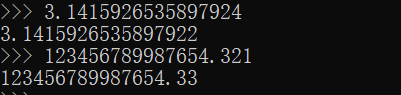
- 浮点数类型直接表示或科学计数法表示中的系数a最长可输出16个数字,浮点数运算结果中最长可输出17个数字,然而,根据sys.float info 结果,计算机只能够提供15个数字(dig) 的准确性,最后一位 由计算机根据二进制计算结果确定,存在误差,例如:
简单地说,浮点数类型的取值范围在[2-1023, 21023], 即[-2.225x10308, 1.797*10308]之间,运算精度为2.220x10-16,即浮点数运算误差仅为0.000 000 000 000 0002。对于高精度科学计算外的绝大部分运算来说,浮点数类型足够“可靠”,一般认为浮点数类型没有范围限制,运算结果准确。


3.复数类型
- 复数可以看做是二元有序实数对(a,b),表示为a+bj,其中a是实数部分,b是虚数部分。Python语言中,复数的虚部通过后缀“J”或“j”来表示,例如:3+4j
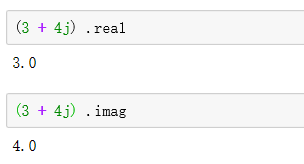
- 复数类型中实部和虚部的数值都是浮点数类型。对于复数z,可以用z.real和z.imag分别获取它的实数部分和虚数部分,例如:
4.字符串类型
- 字符串类型用来存储和处理文本信息;字符串是用单引号、双引号或三引号括起来的一个、多个或多行字符;其中,单引号和双引号都可以表示单行字符串,两者作用相同。使用单引号时,双引号可以作为字符串的一部分;使用双引号时,单引号可以作为字符串的部分。三引号可以表示单行或者多行字符串
- 字符串是字符的序列,可以按照单个字符或字符片段进行索引。字符串包括两种序号体系:正向递增序号和反向递减序号;
Python字符串提供区间访问方式,采用[N:M:T]格式,表示从N到M(不包含M)的子字符串,正向递增序列和反向递减序列可混合使用;T表示步长。举例:

string = "我将无我,不负人民" #共有9个字符
print(string[0:4]) #打印前四个字符
print(string[2:4]) #打印第三四个字符
print(string[0:-1]) #打印除去最后一个字符的字符串
print(string[:-1]) #打印除去最后一个字符的字符串
print(string[-1]) #打印最后一个字符
print(string[:]) #打印全部字符
print(string[::2]) #切片打印,步长为2
输出
我将无我
无我
我将无我,不负人
我将无我,不负人
民
我将无我,不负人民
我无,负民
- 转义字符&特殊的格式化控制字符
字符串以Unicode编码存储,因此,字符串的英文字符和中文字符都算作一个字符。反斜杠字符(\)是一个特殊字符,在字符含义中表示转义,即该字符与后面相邻的一个字符共同组成了新的含义。例如:'表示单引号,"表示双引号
| 转义字符 | 说明 |
|---|---|
| \ ’ | 表示单引号 |
| \ " | 表示双引号 |
| 格式化控制字符 | 说明 |
|---|---|
| \a | 蜂鸣,响铃 |
| \b | 回退,向后退一格 |
| \f | 换页 |
| \n | 换行,光标移到下行行首 |
| \r | 回车,光标移到本行行首 |
| \t | 水平制表 |
| \v | 垂直指标 |
| \0 | NULL,什么都不做 |

(二)数据类型的操作
1.内置的数值运算操作符
- Python提供了9个基本的数值运算操作符,不需要引用第三方库。
| 操作符 | 描述 |
|---|---|
| x + y | x与y之和 |
| x - y | x与y之差 |
| x * y | x与y之积 |
| x / y | x与y之商 |
| x // y | x与y之整数商,即不大于x与y之商的最大整数 |
| x % y | xy与y之商的余数,也称为模运算 |
| - x | x的负值 |
| + x | x本身 |
| x ** y | x的y次幂,即xy |
- 操作符运算结果可能改变数字类型,基本规则如下:
- (1) 整数之间运算,如果数学意义上的结果是小数,结果是浮点数。
- (2) 整数之间运算,如果数学意义上的结果是整数,结果是整数。
- (3) 整数和浮点数混合运算,输出结果是浮点数。
- (4) 整数或浮点数与复数运算,输出结果是复数。
- 所有二元数学操作符(+,-,x,/,//,%,** )都有与之对应的增强赋值操作符(+=、 -=、*=、/=、//=、%=. **=)。如果用op表示这些二元数学操作符,则下面两个赋值操作等价,注意,op和二元操作符之间没有空格:
x op = y 等价于 x = x op y
增强赋值操作符获得的结果写入变量x中,简化了代码表达,例如:
x += 3 相当于 x = x +3
2.内置的数值运算函数

abs()可以计算复数的绝对值,例如: abs(-3+4j)的值为5.0
3.内置的数字类型转换函数
- 数值运算操作符可以隐式地转换输出结果的数字类型,例如,两个整数采用运算符“/”的除法将可能输出浮点数结果。此外,通过内置的数字类型转换函数可以显式地在数字类型之间进行转换;
| 函数 | 描述 |
|---|---|
| int(x) | 将x转换为整数,x可以是浮点数或字符串 |
| float(x) | 将x转换为浮点数,x可以是整数或字符串 |
| complex(re[,im]) | 生成一个复数,实部为re,虚部为im,re可以是整数、浮点数或字符串,im可以是整数或浮点数但不能是字符串 |
- 浮点数类型转换为整数类型时,小数部分会被舍弃(不使用四舍五入),复数不能直接转换为其他数字类型,可以通过real和.imag将复数的实部或虚部分别转换,例如:
float((3+4j).imag)
4.0
4.基本字符串操作符
| 操作符 | 描述 |
|---|---|
| x+y | 连接两个字符串x和y |
| xn 或 nx | 复制n次字符串x |
| x in s | 如果是x s的子串,返回Ture,否则返回False |
| str[ i ] | 索引,返回第i个字符 |
| str[ N:M ] | 切片,返回索引第N到第M的子串,其中不包括M |
5.关系操作符

6.内置的字符串处理函数

7.常用字符串处理函数
-
input函数
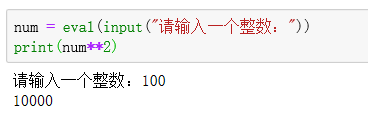
从控制台获得用户的输入,不管用户输入什么内容,input()函数都以字符串类型返回结果;
获得用户输入前可包含一些提示性文字,使用方法如下:<变量> = input(<提示性文字>)
举例
-
eval(函数)
eval(<字符串>) 函数能够以Python表达式的方式解析并执行字符串;简单来说,eval(<字符串>)函数将输入的字符串转变成Python语句,并执行该语句;
eval()函数可将用户输入的部分输入由字符串转变成Python内部可进行数学运算的数值。
例如:
使用eval()函数处理字符串时需要合理使用。例如,如果直接输入字符串"hello",eval()函数将去掉两个引号,将其解释为一个变量,由于之前没有定义过hello变量,解释器会报错。当输入字符串“‘hello’”时,eval()函数会去掉外部双引号后,内部还有一个引号,则’hello’被解释为字符串。


8.字符串类型的格式化
字符串通过format()方法进行格式化处理
- format()方法的基本使用
<模板字符串>. format (<逗号分隔的参数>)- 模板字符串由一系列槽组成,用来控制修改字符串中嵌入值出现的位置,其基本思想是将format)方法中逗号分隔的参数按照序号关系替换到模板字符串的槽中。槽用大括号({}) 表示,如果大括号中没有序号,则按照出现顺序替换,例如
"{ }:计算机{ }的CPU占用率为{ }%。".format("2020.01.30","Python",10)

-
format()方法的基本使用
<模板字符串>. format (<逗号分隔的参数>)- 如果大括号中指定了使用参数的序号,按照序号对应参数替换,参数从0开始编号。调用format()方法后会返回一个新的字符串。例如:
- 如果大括号中指定了使用参数的序号,按照序号对应参数替换,参数从0开始编号。调用format()方法后会返回一个新的字符串。例如:
-
format()方法的格式控制
format()方法中模板字符串的槽除了包括参数序列,还可以包括格式控制信息。此时,槽的内部样式如下: {<参数序号>:<格式控制标记>}槽中格式控制标记


二:程序的控制结构
1.程序流程图
- 程序流程图是用一类列图形,流程线和文字说明描述程序的基本操作和控制流程,它是程序分析和过程描述的最基本方式。 流程图的基本元素包括7种:
其中,起止框表示一个程序的开始和结束;判断框判断一个条件是否成立,并根据判断结果选择不同的执行路径;处理框表示一组处理过程; 输入/输出框表示数据输入或结果输出;注释框增加程序的解释;流向线以带箭头直线或曲线形式指示程序的执行路径;连接点将多个流程图连接到一起,常用于将一个较大流程图分隔为若干部分。下图所示为一个流程图示例,为了便于描述,采用连接点A将流程图分成两个部分。


2.程序基本结构
程序三种基本结构:顺序结构,分支结构和循环结构。
-
顺序结构:是程序按照线性顺序依次执行的一种运行方式;-分 支结构
-
分支结构:是程序根据条件判断结果而选择不同向前执行路径的一种运行方式;
分支结构又分为单分支结构;二分支结构;多分支结构。- 单分支结构:if 语句
语法格式如下:
if <条件>:
<语句>
语句块是if条件满足后执行的一个或多个语句序列,语句块中语句通过与if所在行形成缩进表达包含关系。if 语句首先评估条件的结果值,如果结果为True,则执行语句块中的语句序列,然后控制转向程序的下一条语句。如果结果为False,语句块中的语句会被跳过。- 二分支结构:if—else
if <条件>:
<语句块1>
else:
<语句块2>
语句块1是在if条件满足后执行的一个或多个语句序列,语句块2是if条件不满足后执行的语句序列。二分支语句用于区分条件的两种可能,即True或者False,分别形成执行路径;
二分支结构还有一种更简洁的表达方式,适合通过判断返回特定值,语法格式如下:
<表达式1> if <条件> else <表达式2>- 多分支结构:if—elif—else
if <条件1>:
<语句块1>
elif <条件2>:
<语句块2>
···
else:
<语句块N>
多分支结构是二分支结构的扩展,这种形式通常用于设置同一个判断条件的多条执行路径。Python依次评估寻找第一个结果为 True的条件,执行该条件下的语句块,结束后跳过整个if-elif-else 结构,执行后面的语句。如果没有任何条件成立,else’下面的语句块将被执行。else 子句是可选的。 - 单分支结构:if 语句
-
循环结构:是根据条件判断结果向后反复执行的一种运行方式。
- 遍历循环(即有限循环):for语句
之所以称为“遍历循环”,是因为for语句的循环执行次数是根据遍历结构中元素个数确定的。遍历循环可以理解为从遍历结构中逐一提取元素, 放在循环变量中,对于所提取的每个元素执行一次语句块。
for <循环变量> in <遍历结构>:
<语句块2>
遍历结构可以是字符串、文件、组合数据类型或range( )函数等,例如
循环N次
for i in range(N):
<语句块>
遍历文件 fi 的每一行
for line in fi:
<语句块>
遍历字符s
for c in s:
<语句块>
遍历列表ls
for item in ls:
<语句块>- 无限循环(即条件循环):while语句
无限循环一直保持循环操作直到循环条件不满足才结束,不需要提前确定循环次数
while <条件>:
<语句块>- 循环保留字:break和continue
break用来跳出最内层for或while循环,脱离该循环后程序从循环代码后继续执行;
continue用来结束当前当次循环,即跳出循环体中下面尚未执行的语句,但不跳出当前循环。
- 遍历循环(即有限循环):for语句



3.程序的异常处理
-
异常处理:try—except
举例
当输入数字时,程序正常执行,如果输入的不是数字呢?
Python异常信息中中最重要的部分是异常类型,它表明了异常的原因,也是程序处理异常的依据。Python使用try—except语句实现异常处理,其基本语法格式如下:
try:
<语句块1>
except <异常类型>:
<语句块2>为上述实例程序增加异常处理
-
异常的高级用法
try—except语句可以支持多个except语句,语法格式如下:try:
<语句块1>
except <异常类型1>:
<语句块2>
···
except <异常类型N>:
<语句块N+1>
except:
<语句块N+2>举例
-
Python能识别多种异常类型,但不能编写程序时过度依赖try-except这种异常处理机制。try-except 异常一般只用来检测极少发生的情况,例如,用户输入的合规性或文件打开是否成功等。对于上面实例中索引字符串超过范围的情况应该尽量在程序中采用if语句直接判断,而避免通过异常处理来应对这种可能发生的错误”。
对于面向商业应用的软件产品,稳定性和可靠性是最重要的衡量指标之–。即使这类软件产品也不会滥用try-except类型语句。因为采用try-except语句会影响代码的可读性,增加代码维护难度,因此,- 般只在关键地方采用try- except类型语句处理可能发生的异常。建议读者结合函数设计统筹应用异常处理。更多经验还需要实践来积累。



三:函数和代码复用
(一)函数的基本使用
1.函数的定义
-
函数是一段具有特定功能的、可重用的语句组,用函数名来表示并通过函数名进行功能调用。函数也可以看作是一段具有名字的子程序,可以在需要的地方调用执行,不需要在每个执行的地方重复编写这些语句。每次使用函数可以提供不同的参数作为输入,以实现对不同数据的处理;函数执行后,还可以反馈相应的处理结果。
函数能够完成特定功能,对函数的使用不需要了解函数内部实现原理,只要了解函数的输入输出方式即可。严格地说,函数是一种功能抽象。
有些函数是用户自己编写的,称为自定义函数: Python 安装包也自带了一些函数和方法,包括Python内置的函数(如absO. eval( ). Python标准库中的函数(如math库中的sqrt( )等。
使用函数主要有两个目的:降低编程难度和代码重用。函数是一种功能抽象,利用它可以将-一个复杂的大问题分解成一系列简单的小问题,然后将小问题继续划分成更小的问题,当问题细化到足够简单时,就可以分而治之,为每个小问题编写程序,并通过函数封装,当各个小问题都解决了,大问题也就迎刃而解。这是一种自顶向下的程序设计思想。函数可以在一个程序中的多个位置使用,也可以用于多个程序,当需要修改代码时,只需要在函数中修改一次,所有调用位置的功能都更新了,这种代码重用降低了代码行数和代码维护难度。
-
python使用def保留字定义一个函数,语法格式如下:
def <函数名>(<参数列表>):
<函数体>
<返回值列表>函数名可以是任何有效的Python标识符;
参数列表是调用该函数时传递给它的值,可以有零个、一个或多个,当传递多个参数时各参数由逗号分隔,当没有参数时也要保留圆括号。函数定义中参数列表里面的参数是形式参数,简称为“形参”。
函数体是函数每次被调用时执行的代码,由一行或多行语句组成。
当需要返回值时,使用保留字return 和返回值列表,否则函数可以没有return 语句,在函数体结束位置将控制权返回给调用者。
-
函数调用和执行的一般形式:
<函数名>(<参数列表>)
-
函数定义及调用举例:
编写生日歌,最简单可以重复使用print()语句
print("Happy birthday to you!") print("Happy birthday to you!") print("Happy birthday, dear Climb!") print("Happy birthday to you!")其中,第1、2、4行代码相同,假如需要将birthday改为new year,则每处都要修改。为了避免这种情况,可以用函数进行封装。上述代码中除第3行有微小不同外其余代码完全一致, 这会带来重复代码,为了能够复用语句,将代码修改为:
def happy(): print("Happy birthday to you!") def happyN(name): happy() happy() print("Happy birthday, dear {}!".format(name)) happy() happyN("Linda") print() #换行作用 happyN("Liming")输出
Happy birthday to you!
Happy birthday to you!
Happy birthday, dear Linda!
Happy birthday to you!
Happy birthday to you!
Happy birthday to you!
Happy birthday, dear Liming!
Happy birthday to you! -
函数的调用
程序调用一个函数需要执行以下4个步骤。
(1)调用程序在调用处暂停执行。(2)在调用时将实参复制给函数的形参。
(3)执行函数体语句。
(4)函数调用结束给出返回值,程序回到调用前的暂停处继续执行。
-
生日歌程序分析
第1到第7行是函数定义,函数只有在被调用时才执行,因此,前7行代码不直接执行。程序最先执行的语句是第8行的happyN(“Linda”)。当Python执行到这行时,由于调用了happyN()函数,当前执行暂停,程序用实参"Linda"替换happyN(name)中的形参name,形参被赋值为实参的值,使用实参代替形参执行函数体内容。当函数执行完毕后,重新回到第8行,继续执行余下语句。
2.函数的返回值
-
return语句用来退出函数并将程序返回到函数被调用的位置继续执行。return语句可以同时将0个、1个、或多个函数运算后的结果返回给函数被调用处的变量。
例如:def func(m,n): return m*n s = func("hello~",2) print(s) -
函数也可以没有return,此时函数并不返回值,例如生日歌程序当中happy().
3.全局变量与局部变量
-
全局变量:指在函数之外定义的变量,一般没有缩进,在程序执行全过程有效。
局部变量:指在函数内部使用的变量,仅在函数内部有效,当函数退出时变量将不存在。 -
注意事项:
(1)简单数据类型变量无论是否与全局变量重名,仅在函数内部创建和使用,函数退出后变量被释放,如有全局同名变量,其值不变。(2)简单数据类型变量在用global保留字声明后,作为全局变量使用,函数退出后该变量保留且值被函数改变。
(3)对于组合数据类型的全局变量,如果在函数内部没有被真实创建的同名变量,则函数内部可以直接使用并修改全局变量的值。
(4)如果函数内部真实创建了组合数据类型变量,无论是否有同名全局变量,函数仅对局部变量进行操作,函数退出后局部变量被释放,全局变量值不变。
4.代码复用与模块化设计
-
主要思想:
函数是程序的一 一种抽象,它通过封装实现代码复用。可以利用函数对程序进行模块化设计。 -
程序由一系列代码组成,如果代码是顺序但无组织的,不仅不利于阅读和理解,也很难进行升级和维护。因此,需要对代码进行抽象,形成易于理解的结构。当代编程语言从代码层面采用函数和对象两种抽象方式,分别对应面向过程和面向对象编程思想。
函数是程序的一-种基本抽象方式,它将一系列代码组织起来通过命名供其他程序使用。函数封装的直接好处是代码复用,任何其他代码只要输入参数即可调用函数,从而避免相同功能代码在被调用处重复编写。代码复用产生了另-一个好处,当更新函数功能时,所有被调用处的功能都被更新。
面向过程是一种以过程描述为主要方法的编程方式,该方法要求程序员列出解决问题所需要的步骤,然后用函数将这些步骤-一步一 步实现, 使用时依次建立并调用函数或编写语句即可。面向过程编程是一种基本且自然的程序设计方法,函数通过将步骤或子功能封装实现代码复用并简化程序设计难度。
对象是程序的一种高级抽象方式,它将程序代码组织为更高级别的类。对象包括表征对象特征的属性和代表对象操作的方法。例如,汽车是一个对象,其颜色、轮胎数量、车型是属性,代表汽车的静态值:前进、后退、转弯等是方法,代表汽车的动作和行为。在程序设计中,如果 < a > 代表对象,获取其属性 < b >采用 < a > . < b >,调用其方法< c >采用< a >.< c >0。对象的方法具有程序功能性,因此采用函数形式封装。简单地,对象是程序拟解决计算问题的一个高级别抽象,它包括一组静态值(属性)和一组函数(方法)。从代码行数角度来看,对象和函数都使用了一个容易理解的抽象逻辑,但对象可以凝聚更多代码。因此,面向对象编程更适合代码规模较大,交互逻辑复杂的程序。
面向过程和面向对象只是编程方式不同、抽象级别不同,所有面向对象编程能实现的功能采用面向过程同样能完成,两者在解决问题上不存在优劣之分,很多专业程序员仅采用面向过程方式编程。具体采用哪种方法取决于具体开发环境和要求,- .般在编写较大规模程序时采用面向对象方法,如Windows操作系统,或需要10人或更多人协同开发的程序,或带有窗口交互类的程序。Python 语言同时支持面向过程和面向对象两种编程方式,本书仅介绍但不讲解面向对象编程。
当程序的长度在百行以上,如果不划分模块,程序的可读性非常糟糕。解决这一问题的最好方法是将一个程序分隔成短小的程序段,每-.段程序完成-一个小的功能。无论面向过程还是面向对象编程,对程序合理划分功能模块并基于模块设计程序是一一种常用方法,被称为“模块化设计”。
模块化设计指通过函数或对象的封装功能将程序划分成主程序、子程序和子程序间关系的表达。模块化设计是使用函数和对象设计程序的思考方法,以功能块为基本单位,一-般有以下两个基本要求:
-
(1)紧耦合:尽可能合理划分功能块,功能块内部耦合紧密。
-
(2)松耦合:模块间关系尽可能简单,功能块之间耦合度低。
耦合性指程序结构中各模块之间相互关联的程度,它取决于各模块间接口的复杂程度和调用方式。耦合性是影响软件复杂程度和设计质量的一个重要因素。紧耦合指模块或系统间关系紧密,存在较多或复杂的相互调用。紧耦合的缺点在于更新一个模块可能导致其他模块变化,复用较困难。松耦合- -般基于消息或协议实现,系统间交互简单。
使用函数只是模块化设计的必要非充分条件,根据计算需求合理划分函数十分重要。一般来说,完成特定功能或被经常复用的一组语句应该采用函数来封装,并尽可能减少函数间参数和返回值的数量。
有时候尽管函数和模块化设计使整个程序看上去篇幅更长,但所增加的封装代码十分有益,它们为程序带来了模块化的层次结构,使程序具有更好的可读性。
-
5.函数的递归:
-
定义:
函数作为一.种代码封装,可以被其他程序调用,当然,也可以被函数内部代码调用。这种函数定义中调用函数自身的方式称为递归。就像- - 个人站在装满镜子的房间中,看到的影像就是递归的结果。递归在数学和计算机应用上非常强大,能够非常简洁地解决重要问题。 -
数学上有个经典的递归例子叫阶乘,阶乘通常定义如下:
n! = n(n - 1)(n-2)···(1)
为了实现这个程序,可以通过:一个简单的循环累积去计算阶乘。观察5!的计算,如果去掉了5,那么就剩下计算4!,推广来看,n!=n(n-1)!。 实际上,这个关系给出了另一种表达阶乘的方式:
这个定义说明0的阶乘按定义是1,其他数字的阶乘定义为这个数字乘以比这个数字小1数的阶乘。递归不是循环,因为每次递归都会计算比它更小数的阶乘,直到0!。0!是已知的值,被称为递归的基例。当递归到底了,就需要一个能 直接算出值的表达式。阶乘的例子揭示了递归的两个关键特征。
- (1)存在一个或多个基例,基例不需要再次递归,它是确定的表达式。
- (2)所有递归链要以一个或多个基例结尾。
-
递归使用方法:
以阶乘计算为例def func(n): if n==0: return 1 else: return n * fact(n-1) num = eval(input("请输入一个正整数:")) print(func(num))输出
请输入一个正整数:10
3628800fact()函数在其定义内部引用了自身,形成了递归过程(如第5行)。无限制的递归将耗尽计算资源,因此,需要设计基例使得递归逐层返回。fact()函数通过if语句给出了n为0时的基例,当n==0,fact()函 数不再递归,返回数值1,如果n!=0,则通过递归返回n与n-1阶乘的乘积。

6.Python内置函数
Python解释器提供了68个内置函数,这些函数不需要引用库直接使用;
7.函数库调用方式
- 第一种引用函数库方法
import <库名>
程序课调用库中所有函数,使用库中函数格式如下:
<库名>.<函数名>(<函数参数>)
- 第二种引用函数库方法
from <库名> import <函数名1,函数名2,函数名3···>
from <库名> import * “此处*为通配符,表示所有函数”
调用该库的函数时不再需要使用库名,直接使用如下格式
<函数名>(函数参数)
- 两种函数库调用方式各有优点:第一种方式能够显示标明函数来源,在引用较多库时代码可读性好;第二种方式利用保留字直接引用库中函数,可以使代码更简洁,在使用一个库情况下效果会更好。
四:组合数据类型

(一)集合类型及操作
1.集合类型定义:
-
集合类型与数学中的集合概念一致;
集合元素之间无序,每个元素唯一,不存在相同元素;
集合元素不可更改,不能是可变数据类; -
新建集合
集合用大括号 {} 表示,元素间用逗号分隔;
建立集合类型用 {} 或 set();
建立空集合类型,必须使用set();
举例:A = {"Climb",5201314,("python",123)} B = set("Climb,520,Climb") C = {"Climb",520,"Climb",520} print(A) print(B) print(C)输出
{5201314, ‘Climb’, (‘python’, 123)}
{‘l’, ‘C’, ‘i’, ‘2’, ‘0’, ‘m’, ‘5’, ‘b’, ‘,’}
{520, ‘Climb’}
2.集合类型操作符:
| 操作符及应用 | 说明 |
|---|---|
| A | B(并) | 返回一个新集合,包括在集合A和B中的所有元素 |
| A - B(差) | 返回一个新集合,包括在集合A但不在B中的元素 |
| A & B(交) | 返回一个新集合,包括同时在集合A和B中的元素 |
| A ^ B(补) | 返回一个新集合,包括集合A和B中的非相同元素 |
| A <= B 或 A < B | 返回True/False,判断A和B的子集关系 |
| A >= B 或 A > B | 返回True/False,判断A和B的包含关系 |
4个增强操作符
| 操作符及应用 | 说明 |
|---|---|
| A |= B | 更新集合A,包括在集合A和B中的所有元素 |
| S -= B | 更新集合A,包括在集合A但不在B中的元素 |
| S &= T | 更新集合A,包括同时在集合A和B中的元素 |
| S ^= B | 更新集合A,包括集合A和B中的非相同元素 |
- 集合类型应运场景: 包含关系比较;数据去重。
(二)序列类型及操作
1.序列类型定义:
- 序列是一维元素向量,元素类型可以不同;
类似数学元素序列: s0, s1, … , sn-1;
元素间由序号引导,通过下标访问序列的特定元素 - 序列类型包括:字符串类型,元组类型,列表类型
- 序列类型采用相同的索引体系:正向递增序号和反向递增序号
2.序列类型的通用操作符和函数

- 元组类型及操作:
(1)元组是一种序列类型,一旦创建就不能被修改;
(2)使用小括号 () 或 tuple() 创建,元素间用逗号 , 分隔;
(3)可以使用或不使用小括号;
(4)元组继承了序列类型的全部通用操作。 - 列表类型及操作:
(1)列表是一种序列类型,创建后可以随意被修改;
(2)使用方括号 [] 或list() 创建,元素间用逗号 , 分隔;
(3)列表中各元素类型可以不同,无长度限制.
(4)列表类型特有操作函数及方法:

3.序列类型应用场景:
元组用于元素不改变的应用场景,更多用于固定搭配场景;
列表更加灵活,它是最常用的序列类型;
最主要作用:表示一组有序数据,进而操作它们。
元素遍历:for item in ls; 和 for item in tp;
数据保护:如果不希望数据被程序所改变,转换成元组类型
(三)字典类型及操作
1.字典类型定义:
映射是一种键(索引)和值(数据)的对应;
内部颜色:蓝色
外部颜色:红色
字典类型是“映射”的体现
- 键值对:键是数据索引的扩展
字典是键值对的集合,键值对之间无序
采用大括号{}和dict()创建,键值对用冒号: 表示{<键1>:<值1>, <键2>:<值2>,··· , <键n>:<值n>}
2.字典类型用法:
-
<字典变量> = {<键1>:<值1>, … , <键n>:<值n>}
<值> = <字典变量>[<键>]
<字典变量>[<键>] = <值>
[ ] 用来向字典变量中索引或增加元素 -
举例:
d = {"中国":"北京", "美国":"华盛顿", "法国":"巴黎"} print(d) d["中国"]输出:
{‘中国’: ‘北京’, ‘美国’: ‘华盛顿’, ‘法国’: ‘巴黎’}
‘北京’
3.字典类型的函数及方法

来源:CSDN
作者:Climb_Ma
链接:https://blog.csdn.net/Climb_Ma/article/details/104101431