
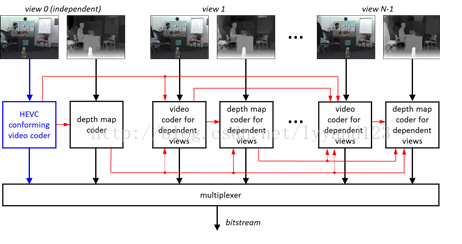
图(1) 3D编码框架图
3D-HEVC采用多视角加深度图(MVD)的格式来表示编码的3D视频。其中包括独立视角的编码(unmodified)上图中的蓝色部分,和修改的HEVC编码器用于减少冗余度。
1. 视差补偿预测(DCP)
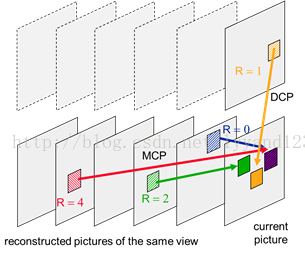
图(2) DCP as an alternative to motion-compensated prediction
MCP是参考同一视角下的以编码图像的帧间编码,而DCP是参考不同的视角下视角间的编码如上图中所示,其中的R代表搜索的参考序列及顺序。
2.层间运动参数预测
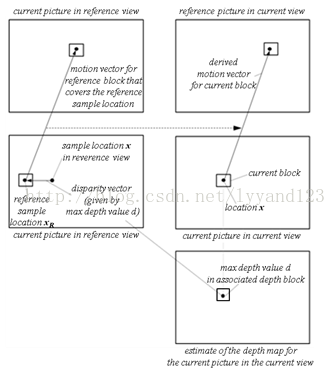
图(3)层间运动参数预测
由于MVD的不同视角是从不同的方向得到3D画面的,因此不同的视角间的非常相似,相关性很大。所以不同视角的同一画面的运动参数及其相似,即可以从编码的块中得到当前块的运动参数。如上图所示。
3. 层间残差预测
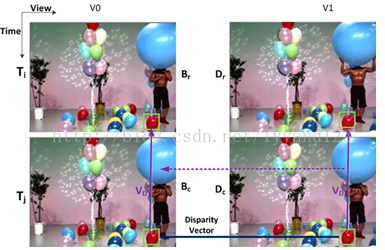
图(4) 层间残差预测
如上图所示,Dc为当前视角下的当前块,Bc为参考视角下的同时刻的的参考块。Dr为同一视角下的帧间预测,Vd表示运动向量(MCP)。由于Bc与Dc是不同视角下的同一时刻下的预测,所以两个块有相同的运动信息。因此,Bc在参考视角中的时间预测Br可以通过Bc加上Vd运动信息得到;Bc的残差加上Vd运动信息,再乘以加权值就可以得到当前的的残差。
4. 深度模型模式(DMM)
由于深度图代表的是物体离镜头的远近,在一些边缘上就存在高频信息。采用原始的HEVC编码edge,就会使边界更加平滑,最生成的虚拟视点就会出现边角的相互重叠或者是背影映射到前景上……从而失去真实的3D效果。修改的深度图帧内编码去掉了in-loop filters包括(the de-blocking filter、the adaptive loop filter、the sample-adaptive loop filter);使用the transmitted motion vector differences are coded using full-sample instead of quarter-sample precision.
为了更好的帧内sharp edge编码增加了4种编码方式,采用非矩形区域划分如下图所示。
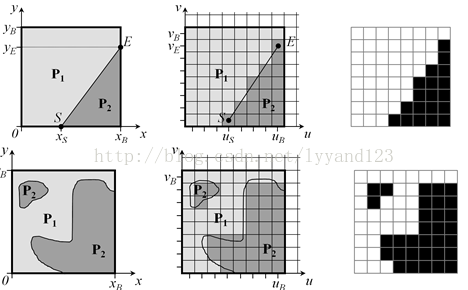
图(5) Wedgelet partitionand Contour partition ,respectively
· Mode1:直接的锲型标记
· Mode2:帧内预测的锲型预测
· Mode3:锲型分割的层间预测
· Mode4:轮廓分割的层间预测
在JCT-3DJ1003文档中的Wedgelet 划分如下:
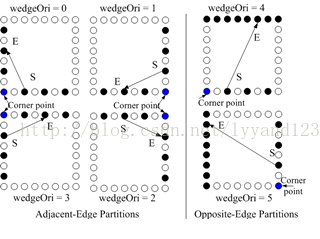
图(6) Wedgeletpartition
在使用Wedgelet 划分是,如果对实时没有要求就可以采用直接搜索的方法,通过计算失真度来确定最佳的划分方式。但这种计算量比较大,对于实时编码达不到要求,因此,必须找到最佳的划分方式。我们知道深度图中大部分的区域是比较平滑,大约为一固定值,如果此时不加以分辨的话任然采用wedgelet划分就会浪费掉大量的时间,所以跳过这些planner 区域就能大大的减少计算时间.(from fast depth modeling mode selection for 3D HEVC intra coding)
期间还有人做了基本色+索引值(BCIM)算法
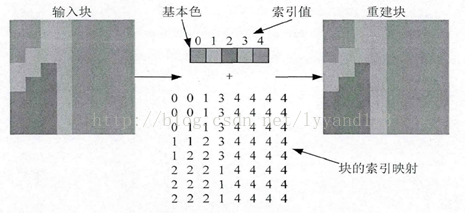
图(7) BCIM示意图
5.虚拟视点生成技术
基于深度图像的视点合成技术(Depth-Image-Based Rendering ,DIBR)的核心是 3Dwarping 技术,3D warping 实际是一个 3D 空间中的坐标位置与 2D 成像平面的投影过程,如下图所示:
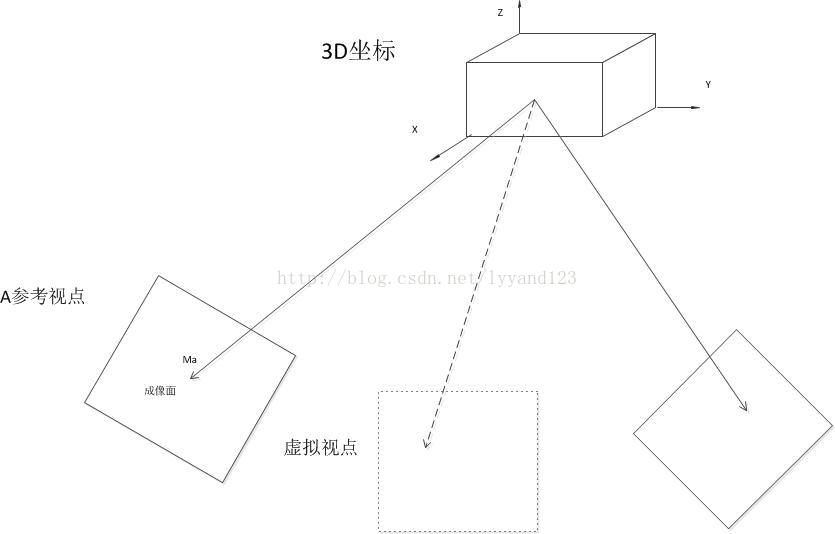
图(8) 虚拟视点的生成
在实际的视点合成中,由于场景中的遮挡、深度信息不准确以及投影坐标的像素问题会造成投影视点图像的空洞、边界模糊、背景映射到前景上所形成的的伪影给观看者带来了3D效果不逼真的效果。下图是3Dwarping生成中存在的问题:

图(9)3D warping 生成问题
A中为背景覆盖
B出现空洞
C出现伪影
来源:CSDN
作者:yancey在演戏
链接:https://blog.csdn.net/yanceyxin/article/details/104055279