1.1 群集(collection)的定义
群集是一种结构化的数据类型。它存储数据,并且提供数据的添加、删除、更新操作,以及对群集的不同属性值的设置与返回操作。
群集可以分为两类:线性的和非线性的。
线性群集是一张元素列表,表中的元素顺次相连。线性群集中的元素通常由位置来决定次序。在现实世界中,购物清单就是很好的线性群集实例。而在计算机世界中则把数组设计成线性群集。
非线性群集所包含的元素在群集内没有位置次序之分。组织结构图就像用架子垒好的台球一样是一个非线性群集的实例。而在计算机世界中树、堆、图和集都是非线性群集。
无论是线性的还是非线性的群集都拥有一套定义好的属性和操作的集合。其中,属性用来描述群集,而操作就是群集能执行的内容。
1.2 群集(collection)的描述
有两种主要的群集类中有几个子类别。线性的群集可能是直接存取群集,也可能是顺序存取群集。而非线性的群集既可以是层次群集,也可以是组群集。
1.2.1 直接存取群集
直接存取群集最常见的实例就是数组。这里把数组定义为具有相同数据类型的元素的群集,而且所有数组元素可以通过整数型索引直接进行存取访问。
数组可以是静态的,这样当声明数组的时候便于针对程序的长度来固定指定元素的数量。数组也可以是动态的,通过ReDim或者ReDim Preserve语句就可以增加数组元素的数量。
在C#中,数组不只是内置的数据类型,它还是一种类。
可以用数组来存储一个线性的群集。向数组添加新元素是很容易的,只要简单地把新元素放置在数组尾部第一个空位上就可以了。但是,在数组中插入一个元素就是不那么容易的了。因为要给插入的元素空出位置,所以需要按顺序向后移动数组元素。.Net框架为简化线性群集的编程提供了一种专门的数组类ArrayList。
字符串是直接存取群集的另外一种类型。字符串是字符的群集。和存取数组元素的方式一样,也可以基于字符的索引对其进行存取。在C#中,字符串也是作为类的对象来实现的。这个类包含一个在字符串上执行标准操作的庞大的方法集合,其中操作有串连接、返回字串、插入字符、移除字符等。
C#字符串是不可变的。这意味着一旦对字符串进行了初始化,就不能在改变它了。当要修改字符串时,不是改变原始的字符串,而是创建一个字符串的副本。在某些情况下这种行为可能会导致性能下降,所以.Net框架提供了StringBuilder类来让用户能处理可变的字符串。
结构是最后一种直接存取的群集类型。结构是一种复合数据类型。它包含的数据可能拥有许多不同的数据类型。
虽然.Net环境中许多元素都是作为类来实现的(比如数组和字符串),但是语言的几个主要元素还是作为结构来实现的,比如数字数据类型。例如,整数类型就是作为Int32结构来实现的。采用Int32的方法之一就是把用字符串表示的数转换成为整数的Parse方法。示例如下:


static void Main(string[] args)
{
int num;
string snum;
snum = Console.ReadLine();
num = Int32.Parse(snum);
Console.WriteLine(num);
}
1.2.2 顺序存取群集
顺序存取群集是把群集元素按顺序存储的表。这里也把此类群集称为线性表。线性表在创建时没有大小限制,这就意味着它们可以动态的扩展和收缩。不能对线性表中数据项进行直接存取访问,而要像如下图所示的那样通过数据项的位置对其进行存取。线性表的第一个元素在表头的位置,而最后一个元素在表尾的位置。
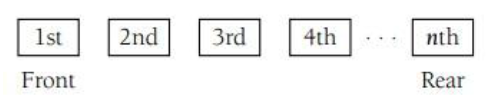
由于不能直接存取线性表的元素,为了访问某个元素就需要遍历线性表直到到达要找元素的位置为止。线性表的实现通常允许两种遍历表的方法:一种是单向从前往后遍历,而另一种则是双向遍历,即从前向后和从后向前遍历。
线性表的一个简单实例就是购物清单。顺次写下要购买的全部商品就会形成一张购物清单。在购物时一旦找到某种商品就把它从清单中划掉。
线性表既可以是有序的,也可以是无序的。有序线性表具有顺次对应的有序值。如下列人名所表示的情况:Beata、Bernica、David、Frank、Mike。而无序线性表则是由无序元素组成的。
线性表的某些类型限制访问数据元素。这类线性表有堆栈和队列。堆栈是一种只允许在表头(或顶端)存取数据的表。在表的顶端放置数据项,而且也只能从表的顶端移出数据项。正是基于这种原因,堆栈也被称为后进先出结构 。这里把向堆栈添加数据项的操作称为入栈,而把从堆栈移出数据项的操作称为出栈。如图所示:
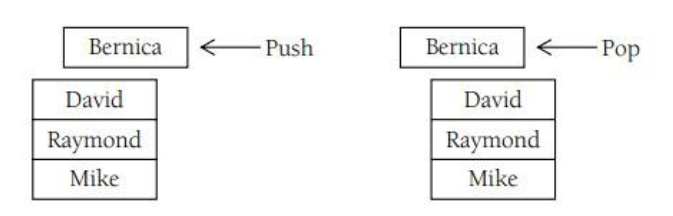
堆栈是非常常见的一种数据结构,特别是在计算机系统编程中尤为普遍。在堆栈的众多应用中,它常用于算术表达式的计算和平衡符号。
队列是一种只允许在表尾进行数据项添加和移出操作的表。它也被称为是先进先出结构。这里把向队列添加数据项称为EnQueue,而把从队列移出数据项称为DeQueue。如图所示:
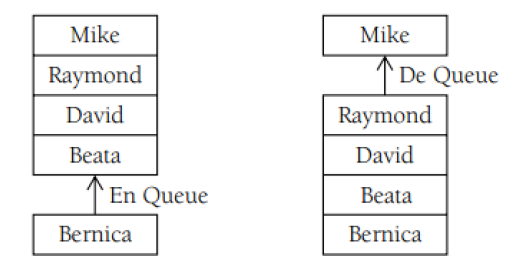
最后要讨论的一类线性群集被称为通用的索引群集,这类群集的第一种就是散列表。它存储了一组与关键字相关联的数据值。在散列表中有一个被称为散列函数的特殊函数。此函数会取走一个值,并把此数据值(称为关键字)转换成用来取回数据的整数索引。然后此索引会用来存取访问与关键字相关联的数据记录。C#中HashTable类用来存储散列表的数据。
另外一种通用的索引群集就是字典。字典也被称为联合,它是由一系列键值对构成的。Dictionary
1.2.3 层次群集
非线性群集分为两大主要类型:层次群集和组群集。层次群集是一组划分了层次的数据项集合。位于某一层的数据项可能会有位于下一较低层上的后继数据项。
树是一种常见的层次群集。树群集看上去像是一棵倒立的树,其中一个数据项作为根,而其它数据项则作为叶子挂在根的下面。树的元素被称为节点,而且在特定节点下面的元素被称为是此节点的孩子。如图展示了一棵实例树:
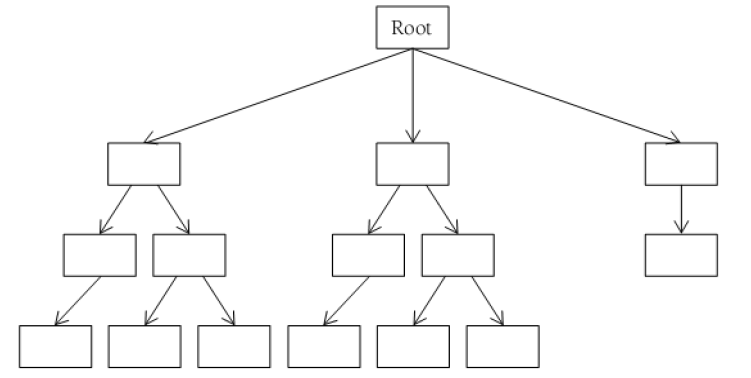
树在几种不同的领域都有应用。大多数现代操作系统的文件系统都是采用树群集设计而成的。其中一个目录作为根,而其它子目录则作为根的孩子们。
二叉树是树集群的一种特殊类型,树中每个节点最多只有两个孩子。二叉树可以变成二叉查找树,这样做可以极大地提高查找大量数据的效率。实现的方法是依据从根到要存储数据的节点的路径为最短路径的方式来放置节点。
还有一种树类型就是堆。堆这样组织就是为了便于把最小数据值始终放置在根节点上。在删除时会移动根节点。此外,堆的插入和删除操作总是会导致堆的重组,因为只有这样才能把最小值放在根节点上。我们经常会用堆来排序,称为是堆排序。通过反复删除根节点以及重组堆的方式就可以对存储在堆内的数据元素进行排序。
1.2.4 组群集
数据项为无序的非线性群集被称为组。集合、图和网络是组群集的三种主要类型。
集合是一种无序数据值的群集,并且集合中每一个数据值都是唯一的,当然了就像整数一样,班级中学生的列表就是一个集合的实例。在集合上执行的操作包括联合和交叉。如图显示了操作集合的实例:

图是由节点集合以及与节点相连的边集合组成的。图用来对必须访问图中每个节点的情况进行建模,而且有些时候还要按照特定顺序进行访问。这样做的目的是为了找到“遍历”图的最有效的方法
网络是图的一种特殊类型网络的每一条边都被赋予了特权。权同使用某边从一个节点移动到另一个节点所花费的代价相关。
1.3 CollectionBase类
.Net框架库不包括用于存储数据的通用Collection类,但是可以使用一种抽象的类CollectionBase类来构造属于自己的Collection类。CollectionBase类为程序员提供了实现定制Collection类的能力。CollectionBase类隐含实现了两个为构造Collection类所必须的接口,即ICollection和IEnumerable,而留给程序员要做的工作就只是对这些作为Collection类特殊内容的方法的实现。
1.3.1 用ArrayList实现Collection类
1.3.2 定义Collection类
在C#中定义一个Collection类最简单的方法就是把在System.Collections库中已找到的抽象类CollectionBase类作为基础类。此类提供了一套可以实现构造构造自身群集的抽象方法集合。CollectionBase类还提供了一种基础的数据结构InnerList(一个ArrayList)。此结构可以用作自身类的基础。
1.3.3 实现Collection类
namespace test
{
class Program
{
static void Main(string[] args)
{
Collection names = new Collection();
names.Add("David");
names.Add("Bernica");
names.Add("Raymond");
names.Add("Clayton");
foreach (object name in names)
{
Console.WriteLine(name);
}
Console.WriteLine("Number of names: " + names.Count());
names.Remove("Raymond");
Console.WriteLine("Number of names: " + names.Count());
names.Clear();
Console.WriteLine("Number of names: " + names.Count());
Console.ReadKey();
}
}
public class Collection : CollectionBase
{
public void Add(Object item) //ArrayList把数据作为对象(即Object数据类型)来存储
{ //这就是把数据项声明为Object的原因
InnerList.Add(item);
}
public void Remove(Object item)
{
InnerList.Remove(item);
}
public new void Clear()
{
InnerList.Clear();
}
public new int Count() //由于是在基础类CollectionBase中实现Count
{ //所以必须用新的关键词来隐藏CollectionBase中找到的Count的定义
return InnerList.Count;
}
}
}
1.4 泛型编程
面向对象编程的问题之一就是所谓“代码膨胀”的特征。为了说明方法参数所有可能的数据类型而需要重载某种方法或重载一套方法集合的时候,就会发生某种类型的代码膨胀。代码膨胀的解决方案之一就是使某个值呈现多种数据类型的能力,同时仅提供此值的一种定义。这种方法被称为是泛型编程。
泛型编程提供数据类型“占位符”。它在编译时由特定的数据类型填充。这个占位符用一对尖括号<>和放在括号之间的标识符来表示。如实例:
泛型编程第一个规范实例就是Swap函数,如:
namespace test
{
class Program
{
static void Main(string[] args)
{
int n1 = 100;
int n2 = 200;
Swap<int>(ref n1, ref n2); //注意调用时参数的填写
Console.WriteLine("n1: " + n1);
Console.WriteLine("n2: " + n2);
Console.ReadKey();
}
static void Swap<T>(ref T val1, ref T val2)
{
T temp;
temp = val1;
val1 = val2;
val2 = temp;
}
}
}
参考链接:
https://www.cnblogs.com/dotnet261010/p/9034594.html
1.5 时间测试
参考链接:
https://www.cnblogs.com/helloxyz/archive/2011/04/08/2009882.html
来源:https://www.cnblogs.com/huangxuQaQ/p/11206892.html