【推荐】2019 Java 开发者跳槽指南.pdf(吐血整理) >>> 
https://v.youku.com/v_show/id_XNDQ4NDYyOTE5Mg==.html
上一期我们进行了 hint 的简单介绍和演示。我们的基本功能就介绍到这里,下面介绍一些进阶功能。

全局序列
我们先来介绍一下全局序列,我们DBLE目前支持四种全局序列。说是四种,如果按照他的内核区分是两种,只不过这两种方式放在不同的载体里面成为了四种。
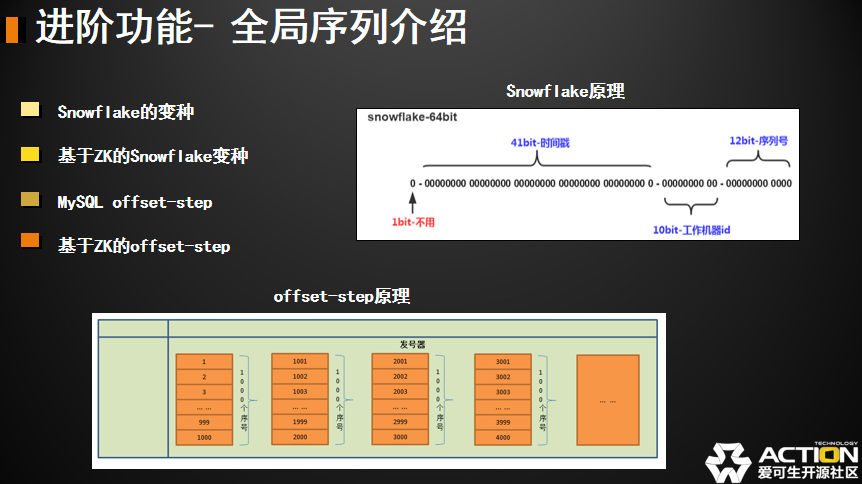
我们先看这两种大概是一个什么概念。
snowflake 右上角这种是 snowflake 的算法是 twitter 最早提出的,通过 long 型数字分段实现的。DBLE 上面对它稍微有一些细节上的调整,但是不影响他的基本概念,他是通过时间戳做一个全局序列。首先他是一个 41 位的时间戳,大家可以先算一下 2 的 41 次方大概是多少?我们这边有个结论。这个数字大小应该足够 69 年的毫秒级别使用。对于我们一般的系统来说,能够存活 79 年应该不太可能。69 年其实已经够用了,计算机诞生也就刚过 70 年,然后我在每个毫秒中又有一个 12 位的序列号,12 位序列号就是 2 的 12 次方,就是 4096,也就是一毫米支持 4096 个并发。我们转换成 QPS 的话,就是乘以 1000,乘以 1000 以后应该是一个四百万的一个吞吐量。这个我们觉得大部分应该达不到这么高的业务要求,所以就基本够用。
中间还有一个名叫工作机器 ID。这个是为集群设计的,当我的 DBLE 不是单节点部署的,而是集群部署的,或者是负载均衡方式部署的。我需要保证我插入数据库的最终的拆分序列是唯一的,其实我是通过给不同机器或者不同实例标识 ID 来做的,这样的话只要我们单个机器的时间不回退,我的时间戳,我的机器 ID 就能保证我的全局序列是唯一的。但如果你的并发某个峰值真的超过了每毫秒 4096 了,会有重复吗?其实他也不会重复,他会等待。他会直接把峰值满足不了的并发,它会等到这个毫秒过去以后再去下一个毫秒重新去生成新的序列,这种情况下延迟会受到一些影响。
offset-step 好,这是 snowflake 的原理,下面是 offset-step 的原理。它是一个什么概念呢?他是有一个发号器,可以按照步长发号。比如说我这里按照 1000 一个步长发号。当我的 DBLE 需要用到全局序列的话,去这个发号器申请一个步长单位的发号。申请 1000 个号,这 1000 个都归我使用。比如说 DBLE 是个集群,另外一个 DBLE 也来申请这个号的话,通过发号器的并发控制,申请发号的结果一定保证不在同一个区间,这样保证我的序列是唯一的。这个方式其实相对于上一个方式来说,优缺点都很明显。优点是它可以把粒度细到某一张表。比如说我表和表之间的全局序列之间没有关系,我们可以重用数字。snowflake 因为跟时间相关的,所以不能重用。所有的自增序列表用的同一套值。发号器方式可以重用。确定是需要额外一个载体,谁来做这个发号器,用于控制并发和发放号以及持久化。所以我们才会有 MySQL 和 zk 两种模式,其实就是发号器的载体。
好,我们今天先介绍到这里。
图文稿为了方便阅读,在不影响学习的情况下优化了一些口语化词汇,文稿与视频会尽量保持一致。
来源:oschina
链接:https://my.oschina.net/actiontechoss/blog/3148120