【推荐】2019 Java 开发者跳槽指南.pdf(吐血整理) >>> 
Numpy 的核心内容是它的多维数组对象——ndarray(N-Dimensions Array),整个包几乎都是围绕这个对象展开。Numpy 本身并没有提供多么高级的数据结构和分析功能,但它是很多高级工具(如 pandas)构建的基础,在结构和操作上具有统一性,因此理解 Numpy 的数组及面向数组的计算有助于更加高效地使用诸如 pandas 之类的工具。 <br /> #数据结构
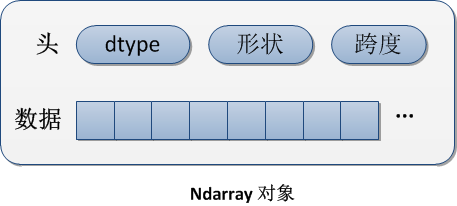
Numpy 的 ndarray 提供了一种将同质数据块解释为多维数组对象的方式。同质,表示数组的元素必须都是相同的数据类型(如 int,float 等);解释,表示 ndarray 的数据块其实是线性存储的,并通过额外的元信息解释为多维数组结构:
下面是一个 3×4 的矩阵:(使用类似 3×4×2... 这种格式表示多维数组的结构时,从左向右的数字对应表示由表及里的维度,或称为轴,按索引给轴编号后可称为“轴 0”、“轴 1”等)
lang:python
>>> foo
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>> foo.dtype
dtype('int32')
>>> foo.shape
(3, 4)
>>> foo.strides
(16, 4)
这个矩阵的形状(shape)是(3,4)或 3×4,即它有 3 个长度为 4 的一维数组;它的 dtype 是 int32 表示它的单位元素是占 4 字节的整型;跨度(strides)元组指的是在某一维度下为了获取到下一个元素需要“跨过”的字节数。可见跨度是可以由 形状+dtype 来确定的。显然这种同质的静态数据结构在进行数值运算时效率要比 Python 内建的可以混杂动态类型的列表要快得多。
dtype 支持的数字类型有: <br />
<table style="font-size:14px"> <tr><td>######################</td><td>***********************************</td></tr> <tr> <td><b>bool_</td> <td>占一个字节的布尔类型(True/False)</td> </tr> <tr> <td><b>int_</td> <td>默认的整数类型</td> </tr> <tr> <td>intc</td> <td>与 C int 相同,通常为 int32 或 int64</td> </tr> <tr> <td>intp</td> <td>用于索引的整数(同 C ssize_t,int32 或 int64)</td> </tr> <tr> <td>int8、16、32、64</td> <td>不同位数的整数</td> </tr> <tr> <td>uint8、16、32、64</td> <td>不同位数的无符号整数</td> </tr> <tr> <td><b>float_</td> <td>float64</td> </tr> <tr> <td>float16、32、64</td> <td>不同位数的浮点数</td> </tr> <tr> <td><b>complex_</td> <td>complex128</td> </tr> <tr> <td>complex64、128</td> <td>不同位数的复数</td> </tr> </table> <br /> 上表中加粗的 **`bool_ , int_ , float_ , complex_`** 都与 Python 的内建类型 `bool , int , float , complex` 相同,实际上使用 Python 的类型名称(int,float 等)也是合法的。`intc , intp` 的大小不定是取决于操作系统。 <br /> #创建 ndarray --- 创建数组最简单的方法是使用 `array()` 函数:(numpy 的公约简称为 np —— `import numpy as np`)
lang:python
array(object, dtype=None, copy=True, order=None, subok=False, ndmin=0)
它接受一切序列类型对象,并将其转化为一个 ndarray 数组,维度视序列的嵌套深度而定:
lang:python
>>> np.array([1,2,3,4])
array([1, 2, 3, 4])
>>> np.array([[1,2],[3,4]])
array([[1, 2],
[3, 4]])
数组的 dtype 会由系统自动推定,除非你显式传递一个参数进去。(系统一般会默认使用 int32 或 float64)
除 array() 函数外,还有一些可以用于创建数组的便捷函数:
<br />
<table style="font-size:14px"> <tr><td>#####################</td><td>*************************************************</td></tr> <tr> <td>asarray</td> <td>将输入转换为 ndarray,若输入本身是 ndarray 就不复制</td> </tr> <tr> <td>arange</td> <td>类似于内建 range 函数,不过返回的是一个一维 ndarray</td> </tr> <tr> <td>ones、ones_like</td> <td>根据指定形状和 dtype 创建一个全 1 数组</td> </tr> <tr> <td>zeros、zeros_like</td> <td>根据指定形状和 dtype 创建一个全 0 数组</td> </tr> <tr> <td>empty、empty_like</td> <td>创建新数组,但只分配内存空间不赋值</td> </tr> <tr> <td>eye、identity</td> <td>创建一个正方的N×N单位矩阵(对角线为1,其余为0)</td> </tr> </table> <br /> `ones(shape, dtype=None, order='C')` 和 `ones_like(arr_instance, dtype=None, order='K', subok=True)` 使用示例,`zeros_like` 取一个 ndarray 为参数,并按它的 dtype 和形状创建全 0 数组:
lang:python
>>> foo = np.ones((3,4),dtype=np.int32)
>>> foo
array([[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]])
>>> bar = np.zeros_like(foo)
>>> bar
array([[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0]])
参数中的 order='C' ,order='F' 指的是元素在内存中的排序,C 代表 C 顺序,指行优先;F 代表 Fortran 顺序,指列优先。
在 pandas 中尽量不要使用 np.empty(),这个函数创建的数组里面是有值的,除非你确定创建的这个数组能被完全赋值,否则后面运算起来很麻烦,这些“空值”的布尔类型是 True,而且 dropna() 方法删不掉。想创建空的 Series ,可以使用 Series(np.nan,index=???) 这样。
<br />
#ndarray 对象的属性
###.reshape(shape)
此方法用于改变数组的形状。虽然我觉得既然 ndarray 对象的数据块都是线性存储的,按说调用 .reshape() 方法的话只需要改一下数据头中的 shape 属性就可以了啊,但实际上不是这样子的!a.reshape(shape, order='C') 方法会返回一个新数组,而不是直接改变调用者的形状。
lang:python
>>> foo = np.arange(9)
>>> bar = foo.reshape((3,3))
>>> bar
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
>>> foo
array([0, 1, 2, 3, 4, 5, 6, 7, 8])
<br /> ###.astype(dtype) 这是一个用于转换数组 dtype 的方法,从前面的 ndarray 数据结构可以猜到,这种转换必然需要创建一个新数组。如果转换过程因为某种原因而失败了,就会引发一个 TypeError 异常。另外,如 `np.int32()` 这样把 dtype 当做函数来用也是可行的,但更推荐 `.astype()` 方法:
lang:python
>>> bar.astype(float)
array([[ 0., 1., 2.],
[ 3., 4., 5.],
[ 6., 7., 8.]])
本例中使用 Python 内建的 float 当做 dtype 传了进去,也是可行的哦,当对数据大小不敏感时就可以这么做。
<br />
###.transpose(*axes)
转置方法返回的是原数组的视图(不复制)。因为我对多维数组也搞不太懂,就只举个二维数组的例子吧(不给 axes 参数):
lang:python
>>> foo = np.arange(8).reshape(2,4)
>>> foo
array([[0, 1, 2, 3],
[4, 5, 6, 7]])
>>> foo.transpose()
array([[0, 4],
[1, 5],
[2, 6],
[3, 7]])
>>> foo.T
array([[0, 4],
[1, 5],
[2, 6],
[3, 7]])
数组的 .T 属性是轴对换的快捷方式。一般在计算矩阵点积时比较方便:np.dot(arr,att.T)。嗯,简单的乘法(星号)是广播运算,点积需要使用 dot() 函数。
<br />
###.sort()
ndarray 的 .sort(axis=-1, kind='quicksort', order=None) 方法可用于给数组在指定轴向上排序。比如一个 (4,3,2)的数组,它的对应轴向分别为(2,1,0),方法默认的 axis=-1 代表最外层维度,如 “表” 里的 “行”。
lang:python
>>> a = np.array([[1,4], [3,1]])
>>> a
array([[1, 4],
[3, 1]])
>>> np.sort(a,0)
array([[1, 1],
[3, 4]])
>>> np.sort(a,1)
array([[1, 4],
[1, 3]])
这里使用了外部函数 np.sort() 是为了在演示过程中不会影响到原数组。np.sort() 函数总是返回一份拷贝,而 .sort() 方法则会更改原数组。
<br />
###统计方法
ndarray 对象还有一些统计方法,可以对整个数组或某个轴向上的数据进行统计计算(轴向数字越大代表的维度越高,从 0 开始计数)。这些方法同时也可以当做顶级函数使用。例如:
lang:python
>>> arr = np.arange(12).reshape(3,4)
>>> arr
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>> arr.sum()
66
>>> np.sum(arr)
66
>>> arr.mean(0)
array([ 4., 5., 6., 7.])
>>> arr.mean(1)
array([ 1.5, 5.5, 9.5])
>>> arr.mean(2)
Traceback (most recent call last):
File "<pyshell#35>", line 1, in <module>
arr.mean(2)
items *= arr.shape[ax]
IndexError: tuple index out of range
基本的数组统计方法有: <br />
<table style="font-size:14px"> <tr><td>#####################</td><td>*************************************************</td></tr> <tr> <td>sum</td> <td>求和</td> </tr> <tr> <td>mean</td> <td>均值</td> </tr> <tr> <td>std,var</td> <td>标准差和方差</td> </tr> <tr> <td>min,max</td> <td>最小值和最大值</td> </tr> <tr> <td>argmin,argmax</td> <td>最小值和最大值的索引</td> </tr> <tr> <td>cumsum</td> <td>累积和</td> </tr> <tr> <td>cumprod</td> <td>累积积</td> </tr> </table> <br /> ###用于布尔型数组的方法 有两个方法 `.any()` 和 `.all()` 可以用于判断某个数组中是否存在或全部为 `True`。这两个方法也同样支持 axis 轴向参数:
lang:python
>>> arr = np.arange(12).reshape(3,4)
>>> arr
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>> arr.all(1)
array([False, True, True], dtype=bool)
>>> arr.any()
True
<br /> #数组之间的运算 --- 形状相同的数组之间的运算都会应用到元素级:
lang:python
>>> foo = np.arange(6).reshape((2,3))
>>> bar = np.arange(5,-1,-1).reshape((2,3))
>>> bar
array([[5, 4, 3],
[2, 1, 0]])
>>> foo
array([[0, 1, 2],
[3, 4, 5]])
>>> foo + bar
array([[5, 5, 5],
[5, 5, 5]])
>>> foo * bar
array([[0, 4, 6],
[6, 4, 0]])
真正的问题在于不同大小的数组间运算时会发生什么。广播(broadcasting)指的是不同形状的数组之间的算数运算的执行方式,这也是 Numpy 的核心内容之一。
广播遵循的原则为:如果两个数组的后缘维度(trailing dimension,即从末尾开始算起的维度)的轴长度相符或其中一方的长度为 1,则认为它们是广播兼容的。广播会在缺失和(或)长度为 1 的维度上进行。
嗯,反正我是没看明白 ╮(╯▽╰)╭ 。自己的理解是,系统会在可能的条件下把形状不同的数组补完成相同的形状,例:
lang:python
>>> foo = np.arange(5)
>>> foo
array([0, 1, 2, 3, 4])
>>> foo * 5
array([ 0, 5, 10, 15, 20])
这里系统就会自动把 5 补完成 array([5, 5, 5, 5, 5])。
<br />
#索引和切片
ndarray 的索引和切片语法与 Python 的列表相似。都是通过如 [0],[0:5:2] 这样的方括号 + 冒号来完成。比较不同之处在于为了方便对多维数组切片,ndarray 对象还支持使用逗号间隔的多维切片方法:[0,3], [0,3:9:2]。
<br />
###普通索引
lang:python
>>> foo = np.arange(12)
>>> foo
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
>>> foo[:5]
array([0, 1, 2, 3, 4])
>>> foo[:5]=0
>>> foo
array([ 0, 0, 0, 0, 0, 5, 6, 7, 8, 9, 10, 11])
>>> bar = foo[:5]
>>> bar[0] = 1024
>>> foo
array([1024, 0, 0, 0, 0, 5, 6, 7, 8, 9, 10, 11])
注意这里,为了节省内存,对 ndarray 的切片操作获得的都是对原数组的引用,因此对该引用的更改操作都会反映到原数组上。如果你想复制出一段副本,就应当使用 .copy() 方法:
lang:python
>>> bar = foo[:5].copy()
>>> bar[:] = 1
>>> foo
array([1024, 0, 0, 0, 0, 5, 6, 7, 8, 9, 10, 11])
也许你会对这里的 foo[:] 感兴趣,这代表切全部的片,不可以使用 foo = 1 这样的赋值语句,这等于给 foo 重新指向一个新的内存地址,而非对切片元素进行操作。
前面提到的使用逗号在多维度下的切片方法:
lang:python
>>> foo = np.arange(12).reshape(3,4)
>>> foo
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>> foo[0,1]
1
>>> foo[0,::2]
array([0, 2])
这种切片方法可以看做是一种语法糖,因为最标准的对多维数组的切片方法应该是下面这样子的,包括 Python 原本对嵌套列表的切片方法也是这样子的:
lang:python
>>> foo
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>> foo[0][1]
1
>>> foo[0][::2]
array([0, 2])
即 foo[0,1] 与 foo[0][1] 效果相同,这种实现可以节省时间,但不如原始方法更直观一点。只要记住对多维数组的单层切片总是切的最外层维度这点,操作起来就不容易乱。
<br />
###布尔型索引
布尔型索引指的是使用一个布尔型数组而非 [::] 作为切片手段,操作会将被切片对象中对应于布尔型数组中 True 元素位置的元素返回,并总是返回一个新的副本。
lang:python
>>> foo = np.arange(12).reshape(3,4)
>>> bar = foo.copy()
>>> bar%2==0
array([[ True, False, True, False],
[ True, False, True, False],
[ True, False, True, False]], dtype=bool)
>>> foo[bar%2==0]
array([ 0, 2, 4, 6, 8, 10])
本例中一个值得注意之处在于 bar%2==0 这个表达式,在 Python 的标准语法中对一个列表和一个整型应用取余操作是非法的,你必须使用循环(如 for)遍历列表的单个元素才行。但 numpy 很贴心地通过广播解决了这个问题,吊不吊!
<br />
###花式索引
花式索引(fancy indexing)是一个 Numpy 术语,它指的是利用整数数组进行索引,这里的整数数组起到了index的作用。
lang:python
>>> foo = np.empty((8,4),int)
>>> for i in range(8):
foo[i] = i
>>> foo
array([[0, 0, 0, 0],
[1, 1, 1, 1],
[2, 2, 2, 2],
[3, 3, 3, 3],
[4, 4, 4, 4],
[5, 5, 5, 5],
[6, 6, 6, 6],
[7, 7, 7, 7]])
>>> foo[[7,2,5]]
array([[7, 7, 7, 7],
[2, 2, 2, 2],
[5, 5, 5, 5]])
>>> foo[[7,2,5],[0,2,2]]
array([7, 2, 5])
上例中 foo[[7,2,5],[0,2,2]] 处两个列表索引之间的逗号,所起的作用与上面普通索引处的作用相同,均为在更低一级维度上索引之用。
<br />
#通用函数
通用函数(即 ufunc)是一种对 ndarray 执行元素级运算的函数。通用函数依据参数的数量不同,可分为一元(unary)函数和二元(binary)函数。(参数一般都是 ndarray 对象)
###一元函数
<table style="font-size:14px"> <tr> <td>abs,fabs</td> <td>整数、浮点、复数的绝对值,对于非复数,可用更快的 fabs</td> </tr> <tr> <td>sqrt</td> <td>平方根,等于 arr**0.5</td> </tr> <tr> <td>square</td> <td>平方,等于 arr**2</td> </tr> <tr> <td>exp</td> <td>以 e 为底的指数函数</td> </tr> <tr> <td>log,log10,log2,log1p</td> <td>以 e 为底的对数函数</td> </tr> <tr> <td>sign</td> <td>计算各元素的正负号,1(正),0(零),-1(负)</td> </tr> <tr> <td>ceil</td> <td>计算大于等于该值的最小整数</td> </tr> <tr> <td>floor</td> <td>计算小于等于该值的最大整数</td> </tr> <tr> <td>rint</td> <td>round int,四舍五入到整数</td> </tr> <tr> <td>modf</td> <td>将数组的整数和小数部分以两个独立数组的形式返回</td> </tr> <tr> <td>isnan</td> <td>返回一个 “哪些值是 NaN” 的布尔型数组</td> </tr> <tr> <td>isfinite,isinf</td> <td>返回是否是有穷(无穷)的布尔型数组</td> </tr> <tr> <td>cos,cosh,sin,sinh,tan,tanh</td> <td>普通和双曲型三角函数</td> </tr> <tr> <td>arccos,arccosh...等同上</td> <td>反三角函数</td> </tr> <tr> <td>logical_not</td> <td>计算个元素 not x 的真值,等于 -arr</td> </tr> <tr> <td>unique</td> <td>计算元素唯一值并返回排序后的结果</td> </tr> </table> <br /> ###二元函数
<table style="font-size:14px"> <tr> <td>add</td> <td>加法,+</td> </tr> <tr> <td>subtract</td> <td>减法,-</td> </tr> <tr> <td>multiply</td> <td>乘法,*</td> </tr> <tr> <td>divide,floor_divide</td> <td>除法和地板除,/ 和 //</td> </tr> <tr> <td>power</td> <td>乘方,**</td> </tr> <tr> <td>maximum,fmax</td> <td>元素级最大值,fmax 将忽略 NaN</td> </tr> <tr> <td>minimum,fmin</td> <td>同上</td> </tr> <tr> <td>mod</td> <td>取模,%</td> </tr> <tr> <td>copysign</td> <td>将第二数组元素的符号复制给第一数组</td> </tr> <tr> <td>greater(_equal),less(_equal),(not_)equal</td> <td>字面意义,返回布尔数组</td> </tr> <tr> <td>logical_and,logical_or,logical_xor</td> <td>字面意义,返回布尔数组</td> </tr> </table> <br /> ###三元函数 这里的三元函数只有一个,而且不是接受 3 个数组参数的意思。它其实是一个条件运算函数,即 `foo if cond else bar` 这个表达式的 numpy 版——`where(condition, [x, y])`
lang:python
>>> arr = np.arange(12).reshape(3,4)
>>> arr
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>> np.where(arr%2==0,1,0)
array([[1, 0, 1, 0],
[1, 0, 1, 0],
[1, 0, 1, 0]])
来源:oschina
链接:https://my.oschina.net/u/660175/blog/276574