MoreLikeThis 是 Lucene 的一个捐赠模块,为其Query相关的功能提供了相当不错扩充。MoreLikeThis提供了一组可用于相似搜索的接口,已方便让我们实现自己的相似搜索。
- 什么是相似搜索:
相似搜索按我个人的理解,即:查找与某一条搜索结果相关的其他结果。它为用户提供一种不同于标准搜索(查询语句—>结果)的方式,通过一个比较符合自己意图的搜索结果去搜索新的结果(结果—>结果)。
- MoreLikeThis 设计思路分析:
首先,MoreLikeThis 为了实现与Lucene 良好的互动,且扩充Lucene;它提供一个方法,该方法返回一个Query对象,即Lucene的查询对象,只要Lucene通过这个对象检索,就能获得相似结果;所以 MoreLikeThis 和 Lucene 完全能够无缝结合;Solr 中就提供了一个不错的例子。MoreLikeThis 所提供的方法如下:
/**
* Return a query that will return docs like the passed lucene document ID.
*
* @param docNum the documentID of the lucene doc to generate the 'More Like This" query for.
* @return a query that will return docs like the passed lucene document ID.
*/
public Query like(int docNum) throws IOException {
if (fieldNames == null) {
// gather list of valid fields from lucene
Collection<String> fields = ir.getFieldNames( IndexReader.FieldOption.INDEXED);
fieldNames = fields.toArray(new String[fields.size()]);
}
return createQuery(retrieveTerms(docNum));
} 其中的参数 docNum 为那个搜索结果的id,即你要通过的这个搜索结果,来查找其他与之相似搜索结果;而fieldNames可以理解为我们选择的一些域,我们将取出该结果在这些域中的值,以此来分析相似度。程序很明显,这些域是可选的。
其次,我们来看看它的一个工作流程,是如何得到这个相似查询的(返回的那个Query),我自己画了个流程图一方便简单说明:
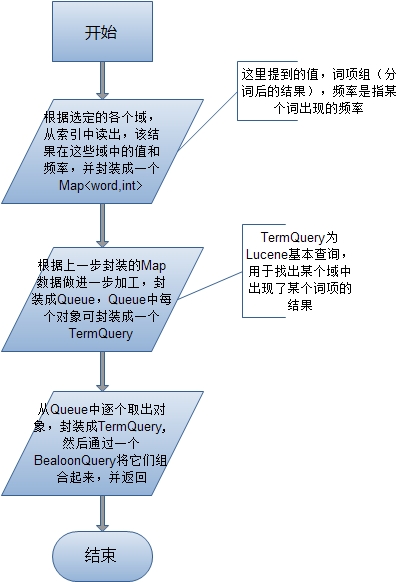
大致流程,图中已经明晰,接下来,我们看看MoreLikeThis的源代码是怎么实现,还有一些细节。
- MoreLikeThis 源代码分析:
代码的中主要通过4个方法实现上面所示的流程,它们分别是:
1. PriorityQueue<Object[]> retrieveTerms(int docNum):用于提取 docNum 对应检索结果在指定域fieldNames中的值。
2. void addTermFrequencies(Map<String,Int> termFreqMap, TermFreqVector vector):它在1方法中被调用,用于封装流程图所提到的Map<String,int> 数据结构,即:每个词项以及它出现的频率。
3. PriorityQueue<Object[]> createQueue(Map<String,Int> words):它同样再方法1中被调用,用于将Map中的数据取出,进行一些相似计算后,生成PriorityQueue,方便下一步的封装。
4. Query createQuery(PriorityQueue<Object[]> q): 用于生成最终的Query,如流程图的最后一步所言。
接下来,我们依次看看源代码的具体实现:
/**
* Find words for a more-like-this query former.
*
* @param docNum the id of the lucene document from which to find terms
*/
public PriorityQueue<Object[]> retrieveTerms(int docNum) throws IOException {
Map<String,Int> termFreqMap = new HashMap<String,Int>();
for (int i = 0; i < fieldNames.length; i++) {
String fieldName = fieldNames[i];
TermFreqVector vector = ir.getTermFreqVector(docNum, fieldName);
// field does not store term vector info
if (vector == null) {
Document d=ir.document(docNum);
String text[]=d.getValues(fieldName);
if(text!=null)
{
for (int j = 0; j < text.length; j++) {
addTermFrequencies(new StringReader(text[j]), termFreqMap, fieldName);
}
}
}
else {
addTermFrequencies(termFreqMap, vector);
}
}
return createQueue(termFreqMap);
}
其中第10行,通过 getTermFreqVector(docNum, fieldName) 返回 TermFreqVector 对象保存了一些字符串和整形数组(它们分别表示fieldName 域中 某一个词项的值,以及该词项出项的频率)
/**
* Adds terms and frequencies found in vector into the Map termFreqMap
* @param termFreqMap a Map of terms and their frequencies
* @param vector List of terms and their frequencies for a doc/field
*/
private void addTermFrequencies(Map<String,Int> termFreqMap, TermFreqVector vector)
{
String[] terms = vector.getTerms();
int freqs[]=vector.getTermFrequencies();
for (int j = 0; j < terms.length; j++) {
String term = terms[j];
if(isNoiseWord(term)){
continue;
}
// increment frequency
Int cnt = termFreqMap.get(term);
if (cnt == null) {
cnt=new Int();
termFreqMap.put(term, cnt);
cnt.x=freqs[j];
}
else {
cnt.x+=freqs[j];
}
}
}
其中第8行,和第9行,通过上一步获得的TermFreqVector对象,获得词项数组和频率数组(terms, freqs),它们是一一对应的。然后10~25行 将这些数据做了一些检查后封装到Map中,频率freqs[]是累加的。
/**
* Create a PriorityQueue from a word->tf map.
*
* @param words a map of words keyed on the word(String) with Int objects as the values.
*/
private PriorityQueue<Object[]> createQueue(Map<String,Int> words) throws IOException {
// have collected all words in doc and their freqs
int numDocs = ir.numDocs();
FreqQ res = new FreqQ(words.size()); // will order words by score
Iterator<String> it = words.keySet().iterator();
while (it.hasNext()) { // for every word
String word = it.next();
int tf = words.get(word).x; // term freq in the source doc
if (minTermFreq > 0 && tf < minTermFreq) {
continue; // filter out words that don't occur enough times in the source
}
// go through all the fields and find the largest document frequency
String topField = fieldNames[0];
int docFreq = 0;
for (int i = 0; i < fieldNames.length; i++) {
int freq = ir.docFreq(new Term(fieldNames[i], word));
topField = (freq > docFreq) ? fieldNames[i] : topField;
docFreq = (freq > docFreq) ? freq : docFreq;
}
if (minDocFreq > 0 && docFreq < minDocFreq) {
continue; // filter out words that don't occur in enough docs
}
if (docFreq > maxDocFreq) {
continue; // filter out words that occur in too many docs
}
if (docFreq == 0) {
continue; // index update problem?
}
float idf = similarity.idf(docFreq, numDocs);
float score = tf * idf;
// only really need 1st 3 entries, other ones are for troubleshooting
res.insertWithOverflow(new Object[]{word, // the word
topField, // the top field
Float.valueOf(score), // overall score
Float.valueOf(idf), // idf
Integer.valueOf(docFreq), // freq in all docs
Integer.valueOf(tf)
});
}
return res;
}
首先第9行,生成一个优先级队列;从12行起,开始逐个遍历每个词项: word;
接着第21~27行:找出该词项出现频率最高的一个域,以此作为该词项的被检索域。(由上面的过程,我们可以得出,同一个词项的频率值,可能来自多个域中的频率的累加;但在Query中只能有一个检索域,这里选择最高的)
第41行和42行,做了打分运算,得到一个分值,对应后面要封装的基本查询对象TermQuery的一个权重值;在后面组和多个Query对象时,以此彰显哪个更为重要;这里用到了余弦公式的思想来进行运算,因为Lucene的打分规则也是采用空间向量,判断两个向量的余弦来计算相似度;具体可参考这两篇博客:http://blog.csdn.net/forfuture1978/article/details/5353126,
http://www.cnblogs.com/ansen/articles/1906353.html 都写得非常好。
另:在Lucene中可以对3个元素加权重,已提高其对应的排序结果,它们分别是:域(field),文档(ducument),查询(query)。
最后 封装成队列,并返回。
/**
* Create the More like query from a PriorityQueue
*/
private Query createQuery(PriorityQueue<Object[]> q) {
BooleanQuery query = new BooleanQuery();
Object cur;
int qterms = 0;
float bestScore = 0;
while (((cur = q.pop()) != null)) {
Object[] ar = (Object[]) cur;
TermQuery tq = new TermQuery(new Term((String) ar[1], (String) ar[0]));
if (boost) {
if (qterms == 0) {
bestScore = ((Float) ar[2]).floatValue();
}
float myScore = ((Float) ar[2]).floatValue();
tq.setBoost(boostFactor * myScore / bestScore);
}
try {
query.add(tq, BooleanClause.Occur.SHOULD);
}
catch (BooleanQuery.TooManyClauses ignore) {
break;
}
qterms++;
if (maxQueryTerms > 0 && qterms >= maxQueryTerms) {
break;
}
}
return query;
}
第5行,生成一个复合查询对象BooleanQuery,用于将基本查询对象TermQuery依次填入。
从第10行开始,逐个从Queue队列中取出数据,封装TermQuery。
第14到21行,对每个TermQuery都进行不同的加权,如前面提到的一样
最后返回Query。
OK 整MoreLikeThis的实现分析结束,个人感觉MoreLikeThis 在实际搜索被用到的并不多,但它给我们提供种查找相似结果的思路,也许我们可以经过自己的改造和定义,来优化搜索引擎,使搜索结果更加满意。
原创blog,转载请注明http://my.oschina.net/BreathL/blog/41663
来源:oschina
链接:https://my.oschina.net/u/100580/blog/41663