有很多人将服务降级和服务熔断混在一起,认为是一回事!
为什么我会有这样的误解呢?
针对下面的情形,如图所示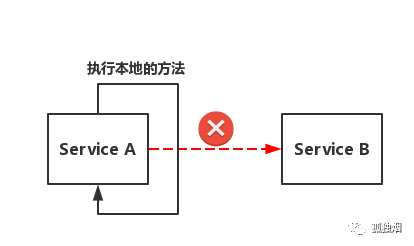
当Service A调用Service B,失败多次达到一定阀值,Service A不会再去调Service B,而会去执行本地的降级方法!
对于这么一套机制:在Spring cloud中结合Hystrix,将其称为熔断降级!
所以我当时就以为是一回事了,毕竟熔断和降级是一起发生的,而且这二者的概念太相近了!
正文
服务雪崩
OK,我们从服务雪崩开始讲起!假设存在如下调用链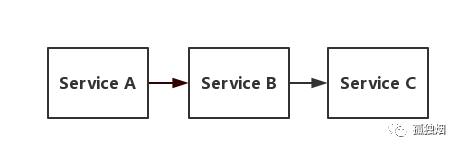
而此时,Service A的流量波动很大,流量经常会突然性增加!那么在这种情况下,就算Service A能扛得住请求,Service B和Service C未必能扛得住这突发的请求。
此时,如果Service C因为抗不住请求,变得不可用。那么Service B的请求也会阻塞,慢慢耗尽Service B的线程资源,Service B就会变得不可用。紧接着,Service A也会不可用,这一过程如下图所示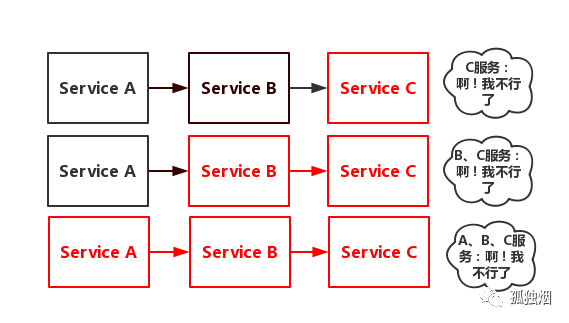
如上图所示,一个服务失败,导致整条链路的服务都失败的情形,我们称之为服务雪崩。
ps:谁发明的这个词,真是面试装13必备!
那么,服务熔断和服务降级就可以视为解决服务雪崩的手段之一。
服务熔断
那么,什么是服务熔断呢?
服务熔断:当下游的服务因为某种原因突然变得不可用或响应过慢,上游服务为了保证自己整体服务的可用性,不再继续调用目标服务,直接返回,快速释放资源。如果目标服务情况好转则恢复调用。
需要说明的是熔断其实是一个框架级的处理,那么这套熔断机制的设计,基本上业内用的是断路器模式,如Martin Fowler提供的状态转换图如下所示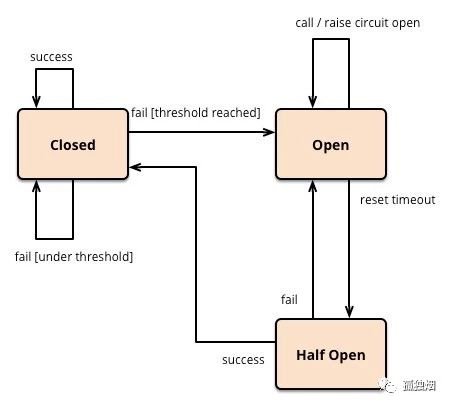
- 最开始处于
closed状态,一旦检测到错误到达一定阈值,便转为open状态; - 这时候会有个 reset timeout,到了这个时间了,会转移到
half open状态; - 尝试放行一部分请求到后端,一旦检测成功便回归到
closed状态,即恢复服务;
业内目前流行的熔断器很多,例如阿里出的Sentinel,以及最多人使用的Hystrix
在Hystrix中,对应配置如下
//滑动窗口的大小,默认为20 circuitBreaker.requestVolumeThreshold //过多长时间,熔断器再次检测是否开启,默认为5000,即5s钟 circuitBreaker.sleepWindowInMilliseconds //错误率,默认50% circuitBreaker.errorThresholdPercentage
每当20个请求中,有50%失败时,熔断器就会打开,此时再调用此服务,将会直接返回失败,不再调远程服务。直到5s钟之后,重新检测该触发条件,判断是否把熔断器关闭,或者继续打开。
这些属于框架层级的实现,我们只要实现对应接口就好!
服务降级
那么,什么是服务降级呢?
这里有两种场景:
- 当下游的服务因为某种原因响应过慢,下游服务主动停掉一些不太重要的业务,释放出服务器资源,增加响应速度!
- 当下游的服务因为某种原因不可用,上游主动调用本地的一些降级逻辑,避免卡顿,迅速返回给用户!
其实乍看之下,很多人还是不懂熔断和降级的区别!
其实应该要这么理解:
- 服务降级有很多种降级方式!如开关降级、限流降级、熔断降级!
- 服务熔断属于降级方式的一种!
可能有的人不服,觉得熔断是熔断、降级是降级,分明是两回事啊!其实不然,因为从实现上来说,熔断和降级必定是一起出现。因为当发生下游服务不可用的情况,这个时候为了对最终用户负责,就需要进入上游的降级逻辑了。因此,将熔断降级视为降级方式的一种,也是可以说的通的!
我撇开框架,以最简单的代码来说明!上游代码如下
try{
//调用下游的helloWorld服务
xxRpc.helloWorld();
}catch(Exception e){
//因为熔断,所以调不通
doSomething();
}
注意看,下游的helloWorld服务因为熔断而调不通。此时上游服务就会进入catch里头的代码块,那么catch里头执行的逻辑,你就可以理解为降级逻辑!
来源:https://www.cnblogs.com/wffzk/p/12013044.html