Hadoop介绍:
1. Hadoop项目组成:

1)hadoop Common :
hadoop的核心。包括文件系统、远程调用RPC的序列化函数。
2)HDSF :
高吞吐量分布式文件系统。是GFS的开源实现。通过hadoop fs命令来读取。
3)MapReduce :
大型分布式合并/计算数据处理模型。Google MapReduce的开源实现。
4)其它:
Cassandra : 由Facebook开发分布式数据仓库。apache已经将Cassandra应用到各种云计算系统中。
Hbase : 结构化分部式数据库。BigTable的开源实现。
Hive : 提供摘要和查询功能的数据仓库。
2. Hadoop系统构成:
每个节点都是一个Java进程。

namenode:主控节点
在一个hadoop系统中只有一个namenode。一旦主控服务器宕机,整个系统将无法运行。
namenode是整个hadoop系统的守护进程。
负责记录文件是如何分割成数据块。
管理数据块分别存储到哪些数据节点上。
对内存进行集中管理。
secondarynamenode:辅助节点
监控HDFS状态的辅助后台程序。如保存namenode的快照。
jobtracker:下发任务(拆分数据)
用户连接应用程序和hadoop。每一个hadoop集群中只一个 JobTracker,一般它运行在Master节点上。
tacktracker:执行任务(接收数据)
负责与DataNode进行结合。
datanode:数据存储
集群中的每个从服务器都运行一个DataNode后台程序,负责将HDFS数据块写到本地的文件系统。
一.配置VirtualBox虚拟机和Ubuntu:
本例系统为Ubuntu10.04LTS。初始用户hm,主机名hm-ubuntu。建议分配内存至少1G,安装略。
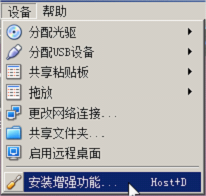
1.为虚拟机安装增强功能:


2.为Ubuntu初始化root用户:

3.修改用户(如果需要):

1)修改用户密码:
sudo passwd 用户名
sudo passwd 用户名 
2)在当前用户下修改用户名:
sudo chfn -f 新名字 原名字
sudo chfn -f 新名字 原名字 
3)注销当前用户,使用root登陆:


usermod -l 新名字 -d /home/新名字 -m 原名字 
4)注销root用户,使用新用户名登陆:

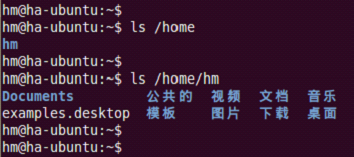
5)根据需要修改hostname和hosts。
6)注意:用户组没有改变,似乎不太要紧。
因为系统是复制ha得来,用户组仍为ha。对后续操作没有不良影响。
4.配置hostname和hosts:
1)HOSTNAME
hm@hm-ubuntu:~$ sudo gedit /etc/hostname 
2)HOSTS
hm@hm-ubuntu:~$ sudo gedit /etc/hosts
hm@hm-ubuntu:~$ sudo gedit /etc/hosts 
3)重启系统。
5.安装OpenSSH:
openssh-client_5.3p1-3ubuntu3_i386.deb 重命名为openssh-client.deb
openssh-server_5.3p1-3ubuntu3_i386.deb 重命名为openssh-server.deb
ssh_5.3p1-3ubuntu3_all.deb 重命名为ssh.deb1)安装openssh-client:
sudo dpkg -i openssh-client.deb 
2)安装openssh-server:
sudo dpkg -i openssh-server.deb 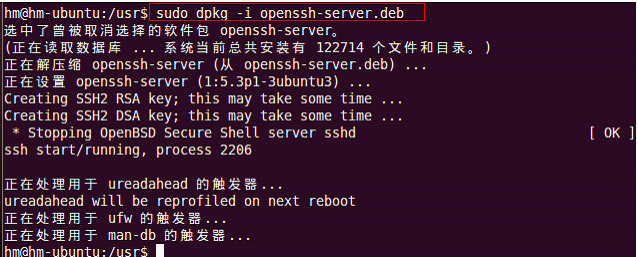
3)安装ssh-all:
sudo dpkg -i ssh.deb 
4)修改OpenSSH配置(跳过):
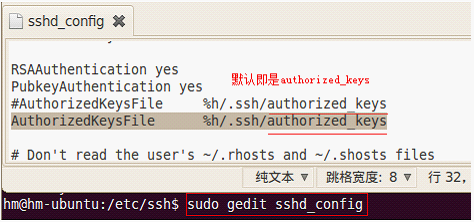
5)创建密钥的空密码文件:
当要求“Enter passphrase (empty for no passphrase) :”以及再次输入时直接回车

6)配置.ssh目录权限(跳过):
sudo chmod 700 -R .ssh7)创建自动验证密码文件:

使用cat命令: authorized_keys 务必和ssh_config中的配置完全一致!
sudo cat id_rsa.pub >> authorized_keys 
使用cp命令: authorized_keys
sudo cp id_rsa.pub authorized_keys 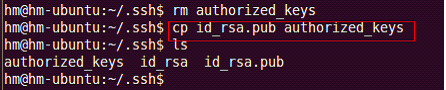
8)设置authorized_keys权限(跳过):
chmod 600 authorized_keys9)测试ssh无密码登陆:


6.安装JDK:
jdk-6u24-linux-i586.bin。务必与hadoop-eclipse-plugin-*.jar插件中使用的jdk版本相同,或者后期根据此版本jdk制作插件。
1)安装bin文件:
(1)进入安装目录:

(2)为当前用户赋予安装此文件的权限,执行安装:

... ...

2)配置jdk到环境变量:

3)重载配置文件,使之立即生效:

4)测试jdk:

7.安装Hadoop:
hadoop-1.1.2-bin.tar.gz。后期hadoop-eclipse-plugin-*.jar插件须符合此版本。
http://mirrors.cnnic.cn/apache/hadoop/common/
1)解压文件:

... ...
2)配置hadoop到环境变量:
export JAVA_HOME=/usr/jdk1.6.0_24
exprot CLASSPATH=.:$JAVA_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$PATH
export PATH=/usr/hadoop-1.1.2/bin:$PATH 
3)重载系统配置文件,使之立即生效:

-end
来源:oschina
链接:https://my.oschina.net/u/256028/blog/132244