微服务
微服务是一种架构风格


单体架构的缺点
开发效率会越来越低, 代码越来越难维护,稳定性不高,扩展性不够

分布式多节点, 各个节点是通过网络发消息通信的
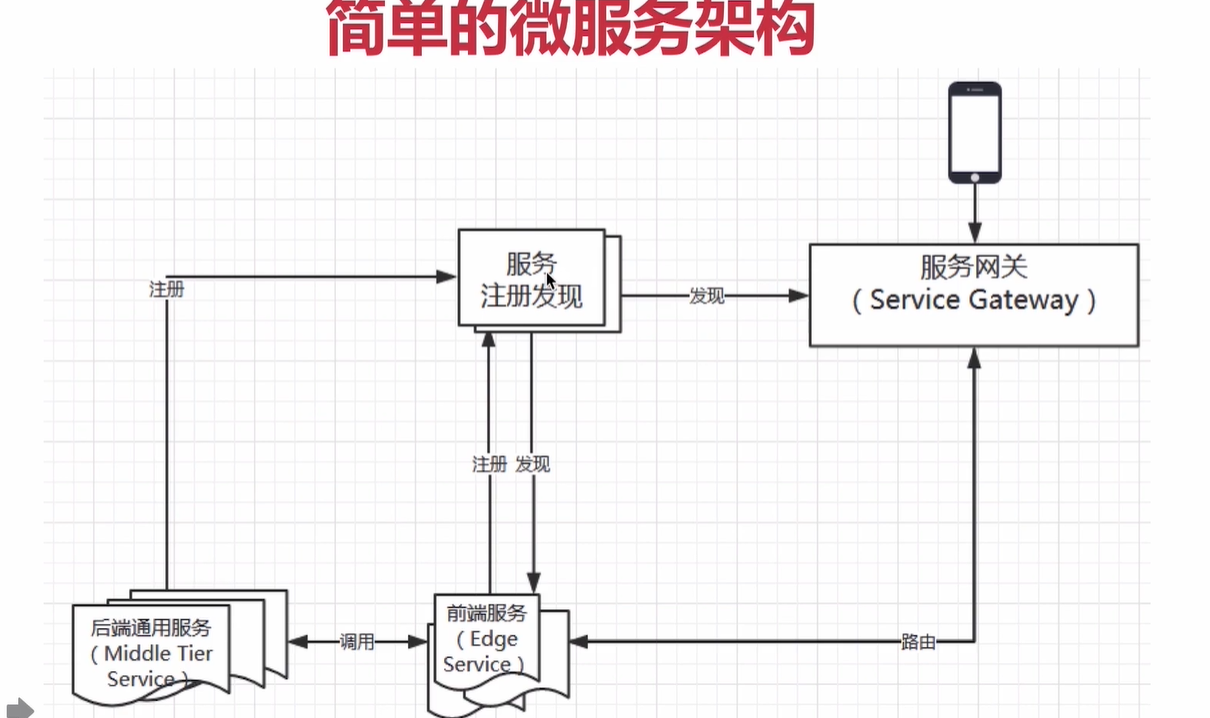
微服务的特点
1, 异构,可以用 不同语言,不同类型的数据库
2,spring cloud 的服务调用方式 可以用 REST or RPC ,因此 其他语言的 客户端可以去实现
比如 Node.js 的 eureka-js-client 可以注册到 eureka 服务中心
spring cloud
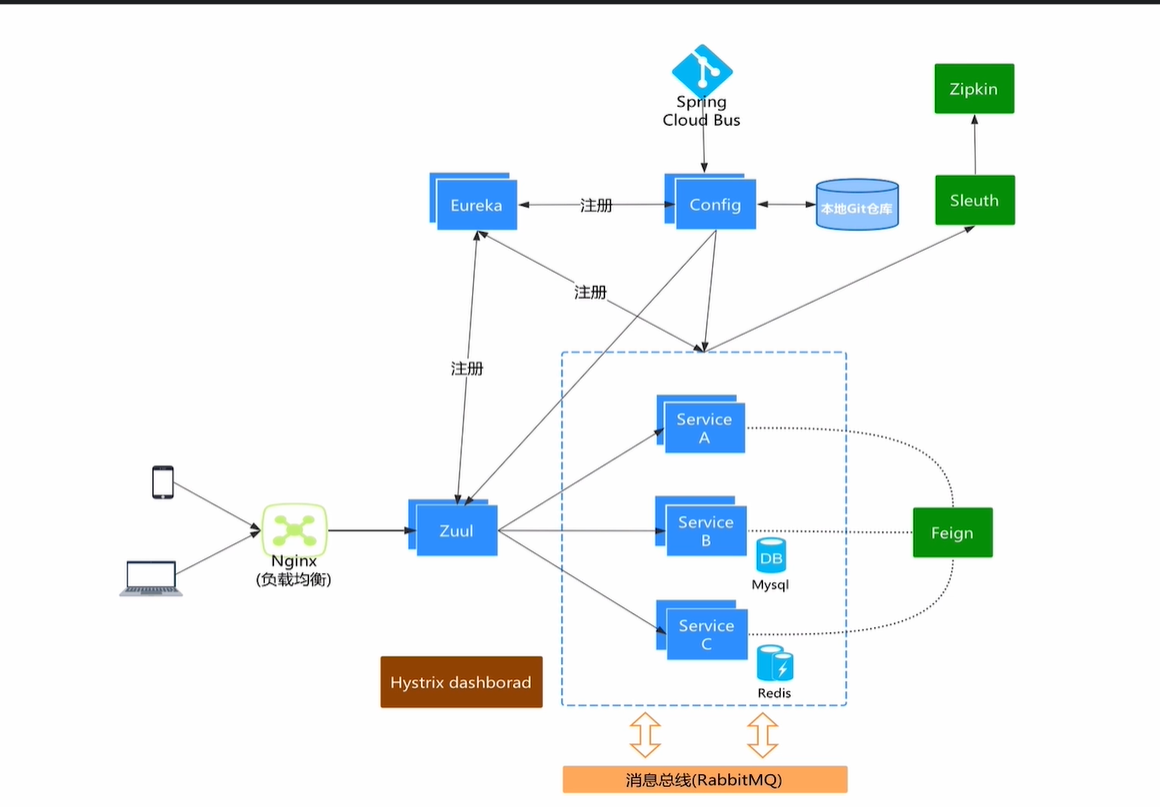
spring clound 的版本对应的其他相关的 版本
https://spring.io/projects/spring-cloud 可以在官网看的
spring cloud 中文文档 https://springcloud.cc/
Eureka Server
com.netflix.discovery.shared.transport.TransportException: Cannot execute request on any known server
这个错误是因为,开始 eureka 即是服务端,也是客户端,所以需要配置服务端地址
eureka:
client:
service-url:
defaultZone: http://localhost:8080/eureka/
eureka 通过心跳方式,不停检查 eureka client , 一定时间内统计服务的上线率,当它低于某个比例的时候,
就会出现警告: 上线率太低了 ,不确定服务到底是上线还是下线 。就当做服务是上线的,(也就是自我保护的模式)
(宁可其有,不可信其无)
可以通过配置 这个 关闭 自我检查
配置高可用
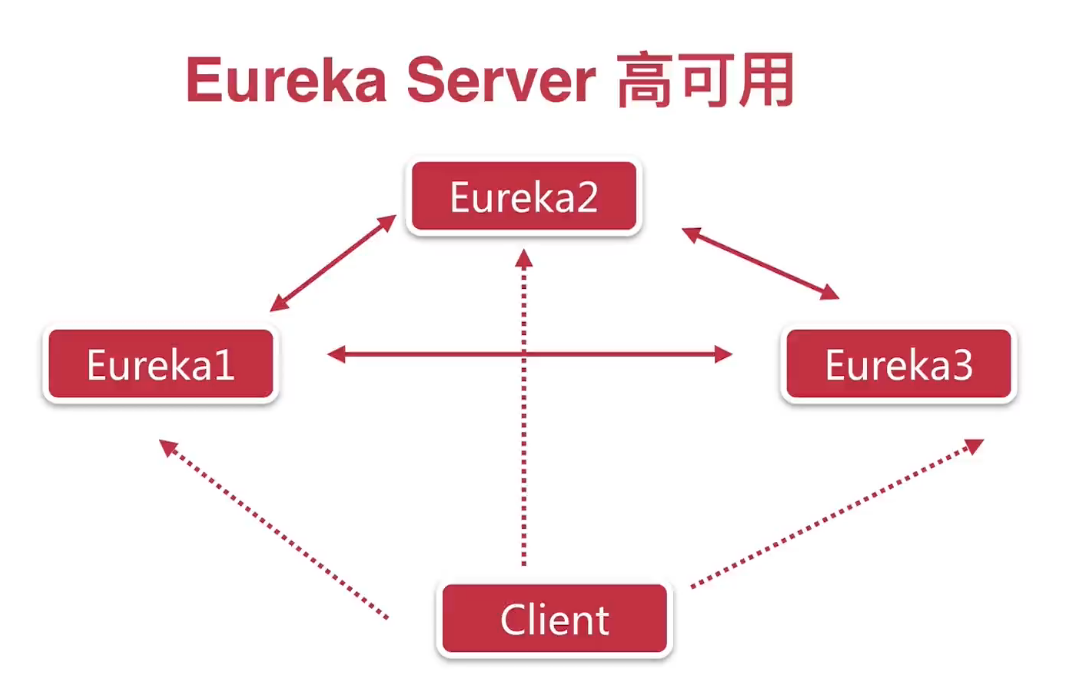
即 eureka server 两两互相配置,互相注册,
eureka client 都配置所有的 eureka server 即可

服务发现的两种方式
1, 客户端发现 比如 eureka : 为什么? 不管是 eureka servier 高可用 还是 eureka client 都是需要 注册到 每个 eureka servier 里面,每个
eureka servier 也可以是 eureka client , 而且每个 eureka client 都缓存有 服务注册信息,eureka servier 挂了,也是可以使用的。
理解为 eureka 都是 client 端
2, 服务端发现 : Nginx , Zookeeper, Kubernetes
比如 zookeeper , 用 dubbo 来说, dubbo 消费者并不需要 注册到 zookeeper里面,而 dubbo 服务 都需要注册到 zookeeper,
可以说是 zookeeper 发现 dubbo服务 , 然后 dubbo 消费者 定时监听 zookeeper ,取到 dubbo服务 数据
微服务拆分
先明白起点和终点
起点: 既有架构的形态
终点: 好的架构不是设计出来的,而是进化而来的。 一直在演讲ing
需要考虑的因素与坚持的原则
考虑 水平复制, 数据分区, 功能解耦
业务形态不适合的微服务
1, 系统中包含很多很多强事务场景
2, 业务相对稳定,迭代周期长
3. 访问压力不大,可用性要求不高
康威定律
1, 沟通的问题,会影响系统的设计

所以提倡 小团队
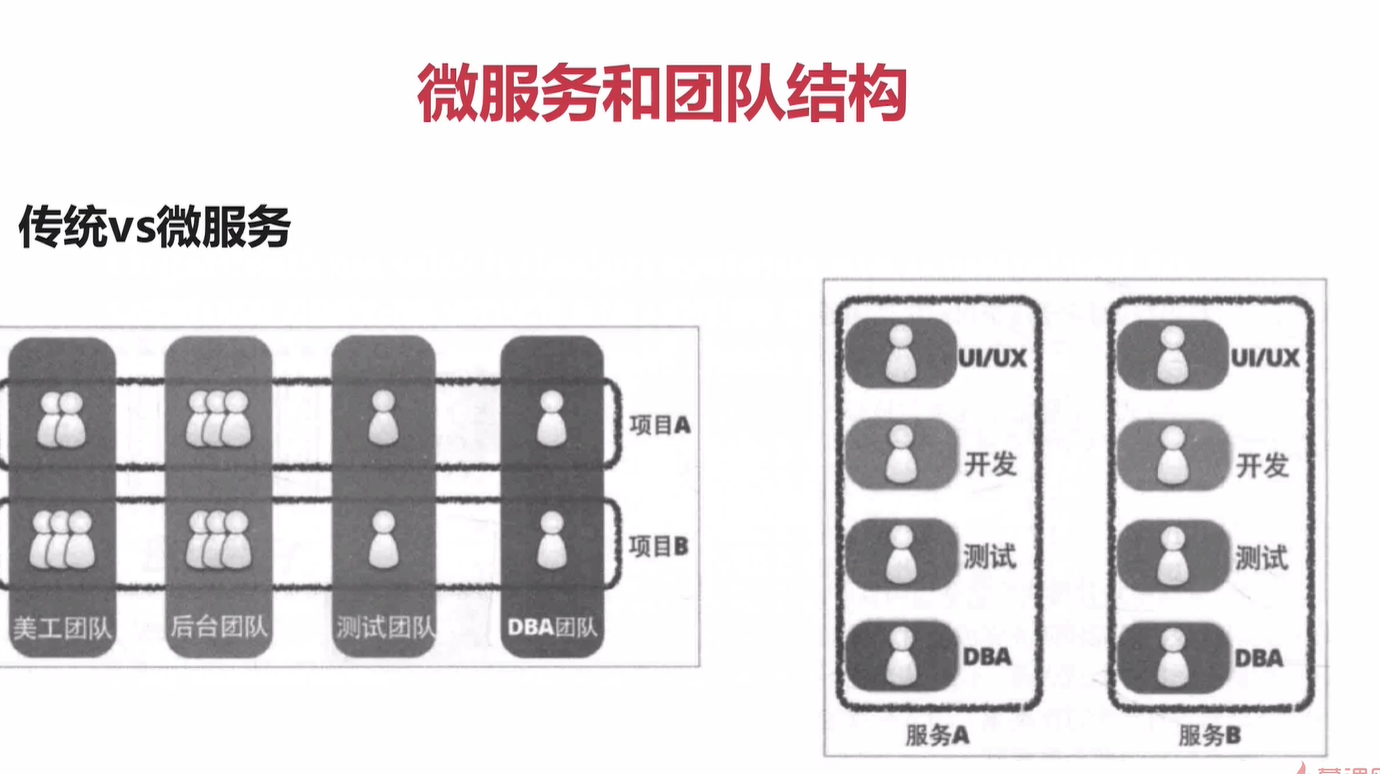
微服务影响 于 团队和产品 ,负责整个服务的生命周期
如何拆功能
1, 单一职责, 松耦合,高内聚
2, 关注点分离: 按职责,按通用性, 按粒度级别
拆分方法论
1, 先考虑业务功能,再考虑数据
2, 无状态服务
如何拆 数据
1. 每个微服务都有单独的数据存储,否则 和其他服务同一个数据库会可能出问题
或者 微服务要避免访问其他的服务的数据库。 服务之间隔离
2. 依赖服务特点选择不同结构的数据库类型
3. 难点在确认边界
针对边界设计API , 依据边界权衡数据冗余(保证数据一致)
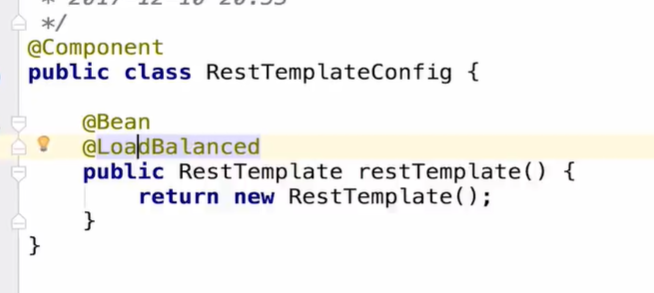
RestTemplate 使用方式
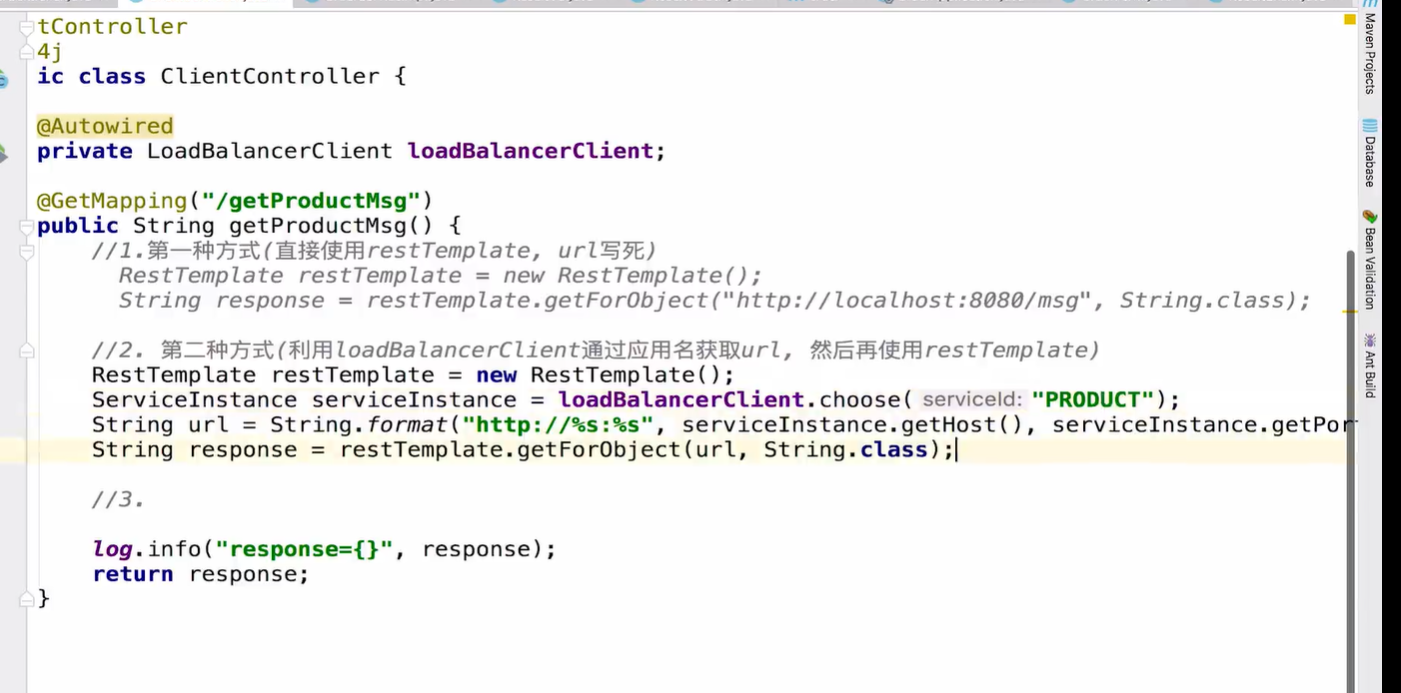
或者 直接使用 @LoadBalanced 配置 RestTemplate
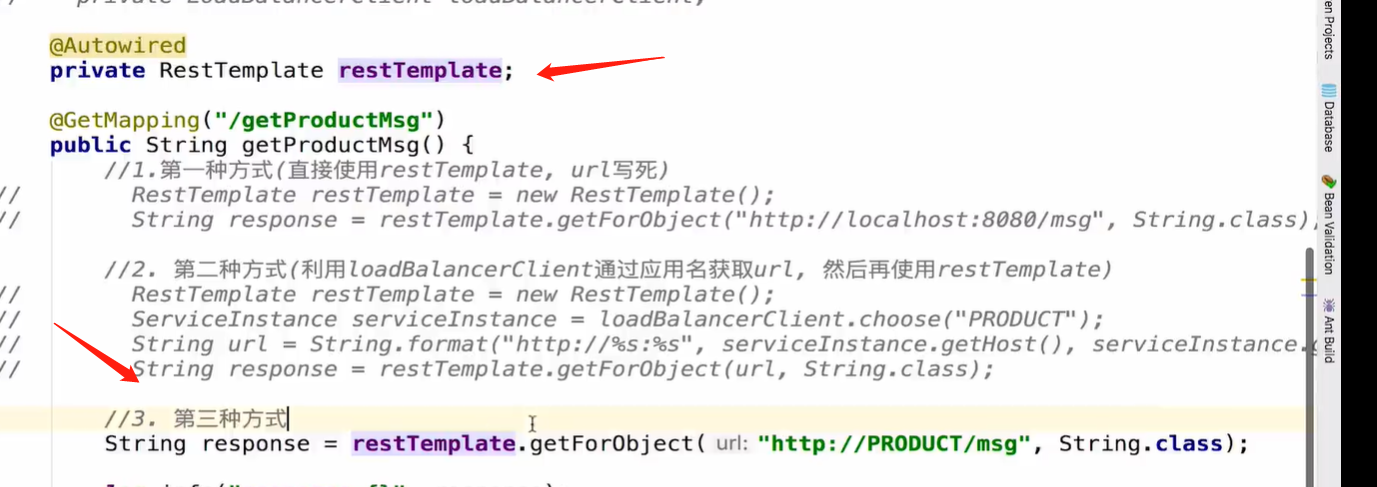
Ribbon
封装了 RestTemplate 和OK http 两种请求端实现。 默认使用 Ribbon 对 eureka 服务发现的负载均衡
服务发现: 发现依赖服务的列表,
服务选择规则 :策略选择即负载均衡的时候选择服务的策略 。
服务监听: 做到高效剔除服务
使用到的 负载均衡 都是 使用的 ribbon 去实现的.
# 配置 负载访问 product 服务的ribbon 负载均衡策略
product:
ribbon:
NIWSServerListClassName: com.netflix.loadbalancer.RandomRule
Feign
1, 基于接口的注解
2, 声明式REST 客户端 (伪RPC)
3. Feign 也使用 了 ribbon 做负载均衡
微服务和容器天生一对
docker 可以做到进程隔离 , 可以通过镜像来交付环境

统一配置中心
为什么需要
1, 不方便维护
2, 配置内容安全与权限
3, 更新配置项目需重启
配置文件说明
/{name}-{profiles}.yml
/{lable}/{name}-{profiles}.yml
name 服务名, profiles 环境, lable 分支 branch
两种方式都无所谓,
config-server 会在本地存一份 配置文件的
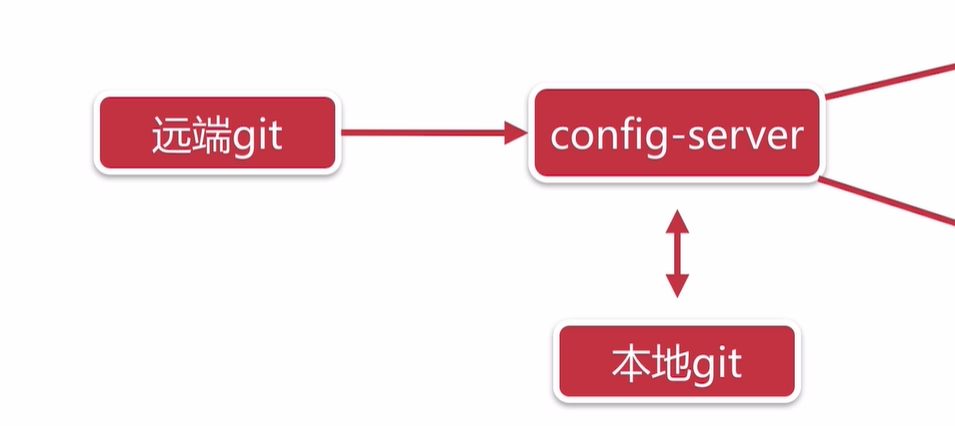
spring cloud bus
为了能够 实现 改变 git 上面的配置,是其他 服务 能够动态更新配置,就需要用到 这个 bus
就是 公交车的意思,谁都可以上。
异步
客户端请求不会阻塞进程,服务端的响应可以是非即时的
异步形态
1, 通知, 2, 请求/异步响应, 3 ,消息
MQ 应用场景
1, 异步处理, 2, 流量削峰 , 3: 日志处理 , 4 应用解耦
spring cloud Stream
也可以使用 spring cloud stream 操作 rabbitmq
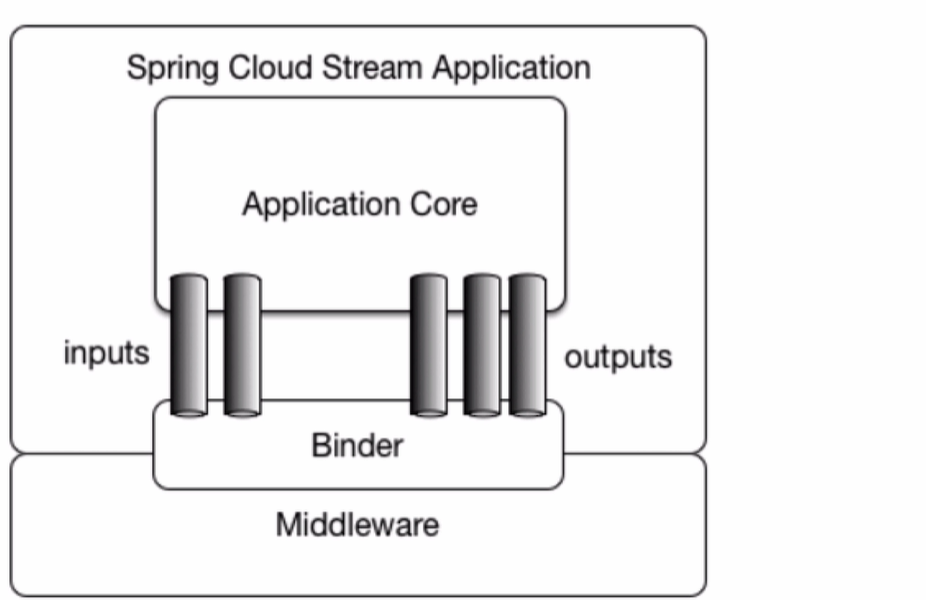
application core 应用, Binder 抽象概念, 是 应用与 消息中间件 的 粘合件
stream 是对消息中间件 的进一步封装, 可以做到代码中 对中间件的无感知,甚至 动态切换中间件
目前只支持 rabbitMQ, kafka
网关
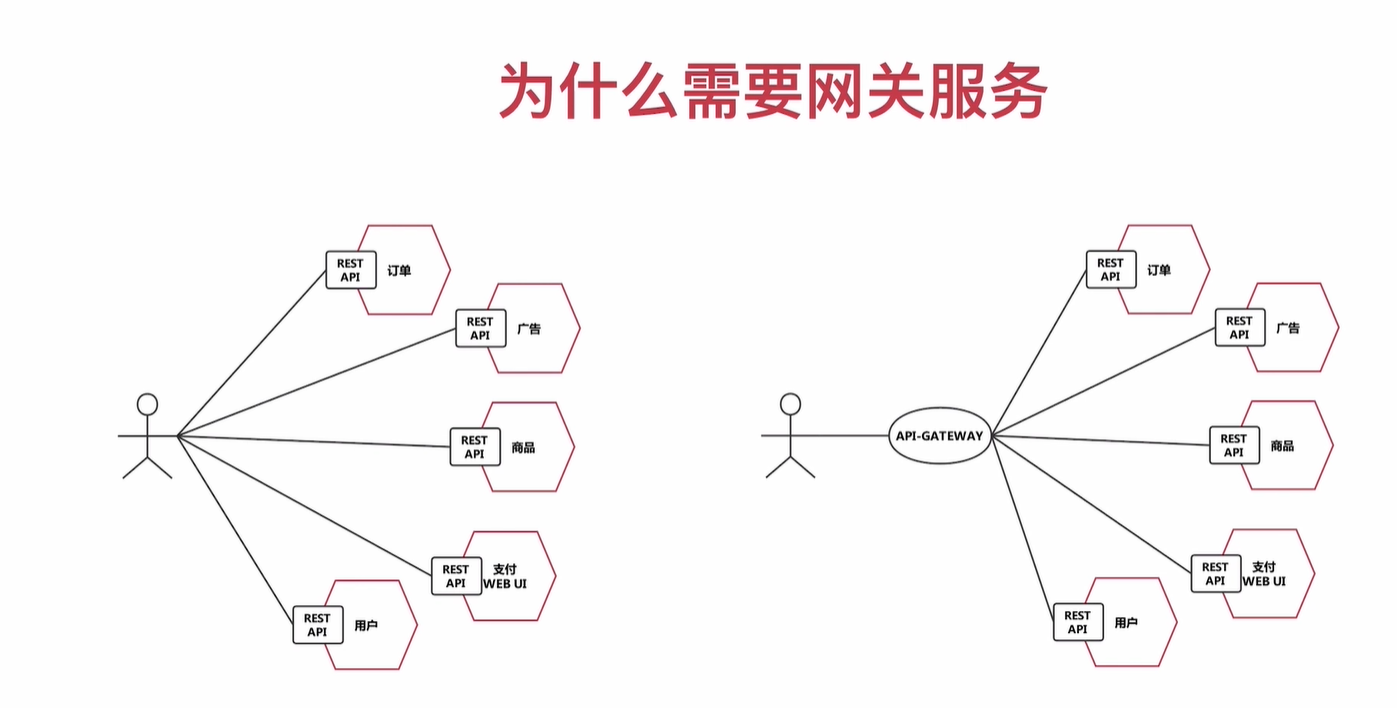
网关要素
1, 稳定性, 高可用
2, 性能,并发性
3, 安全性, 扩展性
4, 是处理非业务处理的 地方
网关方案
1, nginx , kong (商业), Tyk , spring cloud Zuul (一代阻塞,二代 异步)
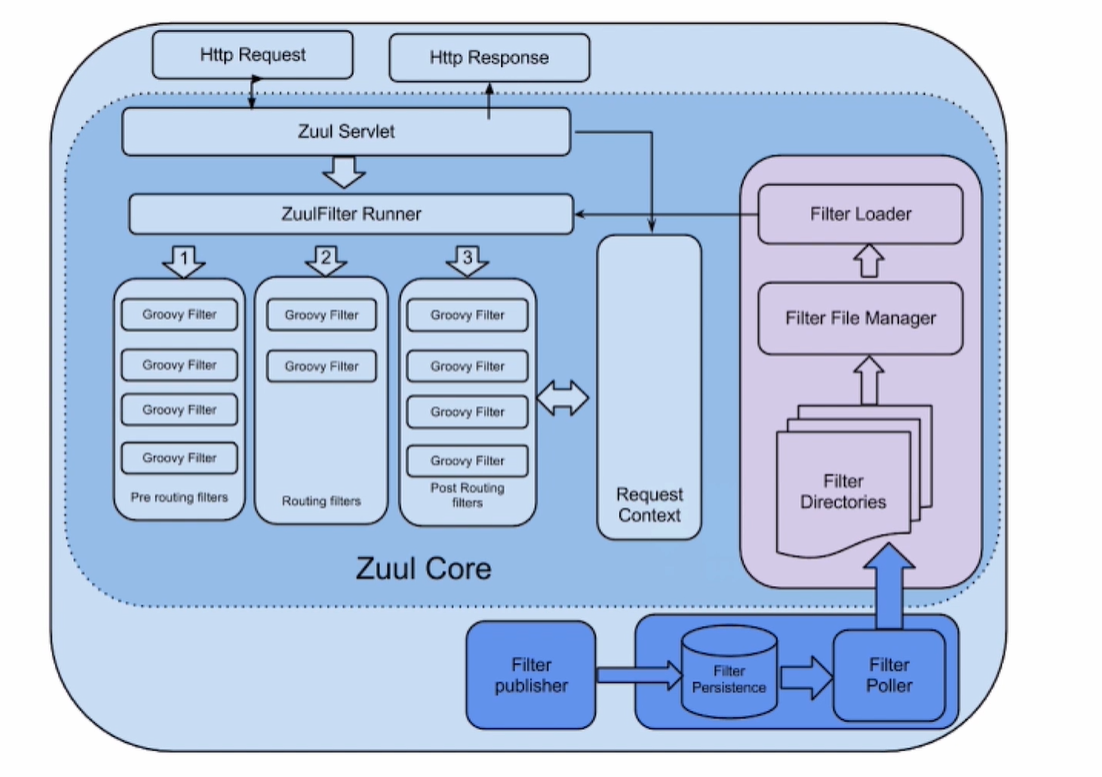
zuul
路由 + 过滤器 =Zuul
核心就是 一系列的过滤器
四种过滤器: 前置(Pre), 路由(Route), 后置(post), 错误(Error)
zuul 一次请求生命周期
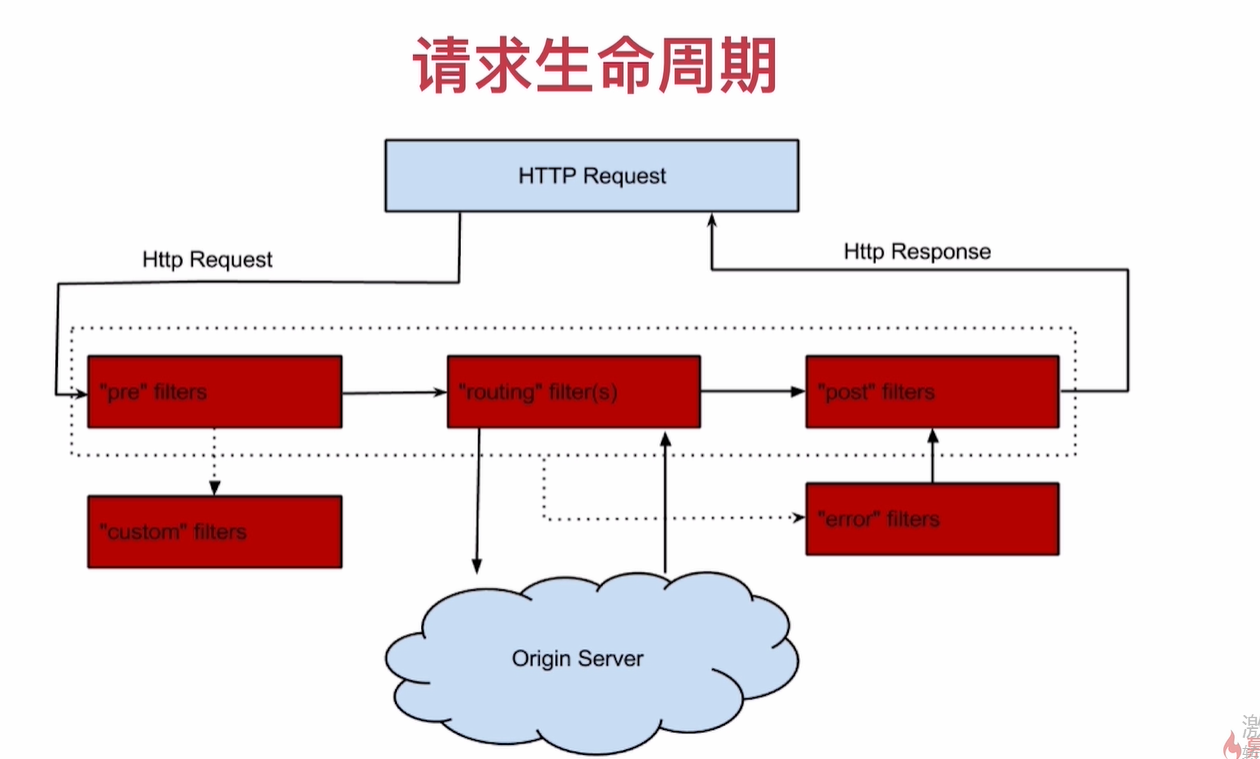
routing fillter 可以在 进入 对应服务时候对 请求 进行处理, 加工
post fillters 可以最后对响应进行 处理
使用
@EnableZuulProxy
//可以什么都不用配置就可以转发了的。比如 有个服务 product, // 访问的时候 域名 + /product/+ 对应的 product 的具体地址就可以转发 : 域名/ 应用名称 /
可以通过 /application/routes 访问 ,查看到路由规则
#排除某些路由
ignored-patterns:
- /**/product/listForOrder
默认zuul 是不能传递 cookie 给后端服务的, 设置过滤的敏感头内容为空即可
sensitiveHeaders:
默认是: Arrays.asList("Cookie", "Set-Cookie", "Authorization")
应用场景

限流可以用 令牌桶算法
可以使用谷歌 实现的 令牌桶算法
com.google.common.util.concurrent @ThreadSafe
@Beta
public abstract class RateLimiter
后置: 统计, 日志
高可用
多个zuul 节点注册到 Eureka server
Nginx 和 Zuul 混搭
zuul 超时
zuul 使用时候,可能 在第一次 请求的时候会出现 超时的异常。
是因为zuul 的懒加载,在第一次请求的时候才会去加载对应的内容,默认时间比较短,加载其他类要时间,所以就出现超时提示
zuul 依赖了 hystrix , 可以配置 hystrix 的全局超时
#解决 zuul 第一次请求可能 超时的 bug
hystrix:
command:
default: # 默认全局作用
execution:
isolation:
thread:
timeoutInMilliseconds: 5000
Hystrix 服务容错
防雪崩利器 : 服务降级,服务熔断,依赖隔离,监控
服务降级
优先核心服务,非核心服务不可用或弱可用
通过HystrixCommand 注解指定, fallbackMethod (回退函数)中具体实现降级逻辑
配置超时时间 默认1s
依赖隔离
线程池隔离, Hystrix 自动实现了依赖隔离

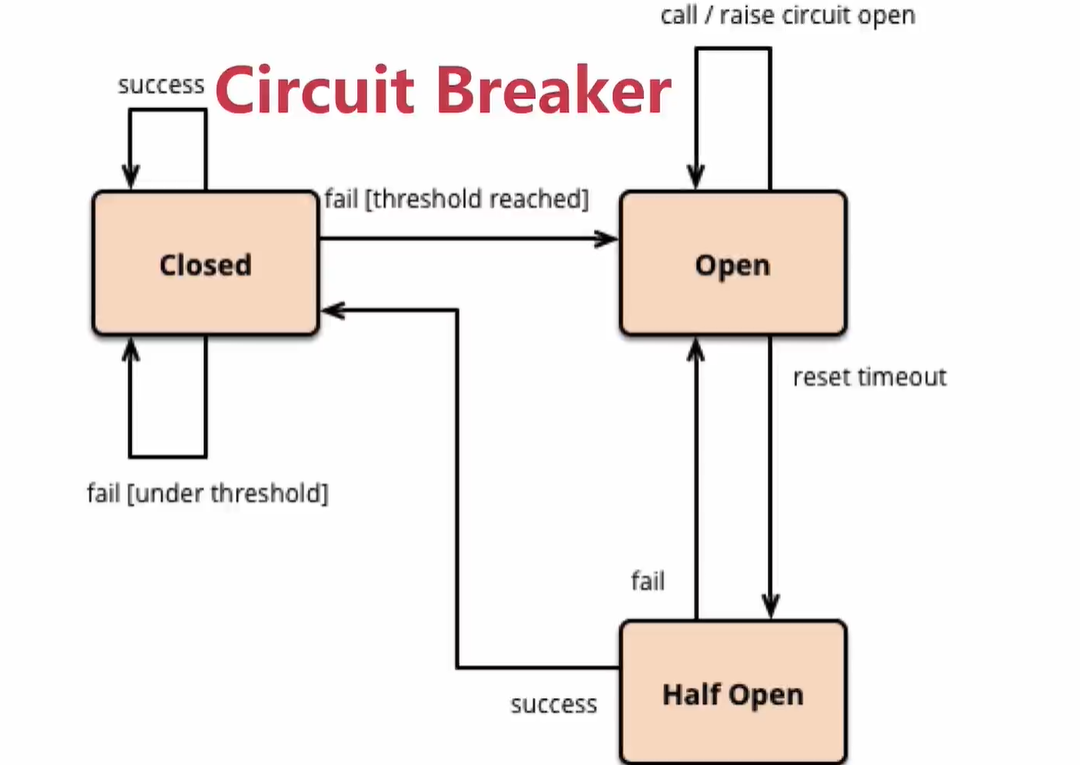
circuitBreaker.sleepWindowInMilliseconds 即休眠时间,当断路器打开的时候, 会进行休眠一定时间,休眠一定时间之后,断路器就半打开,如果还是失败就继续打开断路器,继续休眠,到半打开。。。
feign-hystrix
feign 已经集成了 hystrix
不过需要开启配置 ,默认是 false
#配置 feign 可以结合 hystrix 使用
feign:
hystrix:
enabled: true
服务追踪 : 链路监控
sleuth
docker 使用 zipkin
docker run -d -p 9411:9411 openzipkin/zipkin分布式追踪核心
数据采集, 数据存储, 查询展示
OpenTracing : zipkin, tracer, jaeger, grpc 等
annotation: 事件类型

客户端调用时间= CR-CS , 服务端 处理时间 = sr - ss
部署 项目到 docker
1, 本地必须安装docker
使用 阿里云 docker 镜像中心
将项目打成jar .
FROM hub.c.163.com/library/java:8-alpine 镜像中心,并指定java 镜像
ADD target/*.jar app.jar 项目jar目录app.jar 即重命名jar 名称
EXPOSE 8761 端口
ENTRYPOINT ["java", "-jar", "/app.jar"] 执行比如 在当前路径 构建 docker 项目eureka 镜像:
docker build -t springcloud2/eureka .
. 就是当前路径的意思, springcloud2/eureka 即目录
构建好之后,启动docker 项目: docker run -p 8761:8761 -d spring/cloud2/eureka
然后就可以 传到 镜像到 云上面了,这样其他人就可以用了。
rancher 部署 docker 平台
需要先在 Linux 安装 docker ,
yum install docker
启动docker : systemctl start docker
安装 rancher 文档
https://www.cnrancher.com/docs/rancher/v1.x/cn/installing/installing-server/#single-container
目前不要使用 预览版,
安装命令
sudo docker run -d --restart=unless-stopped -p 8080:8080 rancher/server:stable
如果下载比较慢,就 使用镜像加速地址,但是下面的 这个镜像地址已经关了。 我是不用配置的,也是下载很快的
vim /etc/docker/daemon.json
```
{
"registry-mirrors": ["https://fy707np5.mirror.aliyuncs.com"]
}
```
再执行 下面两个命令
```
systemctl daemon-reload
systemctl restart docker
```重启docker 之后, rancher 也会自动 启动的
然后添加 主机, 直接一路 选择即可
使用自定义服务器
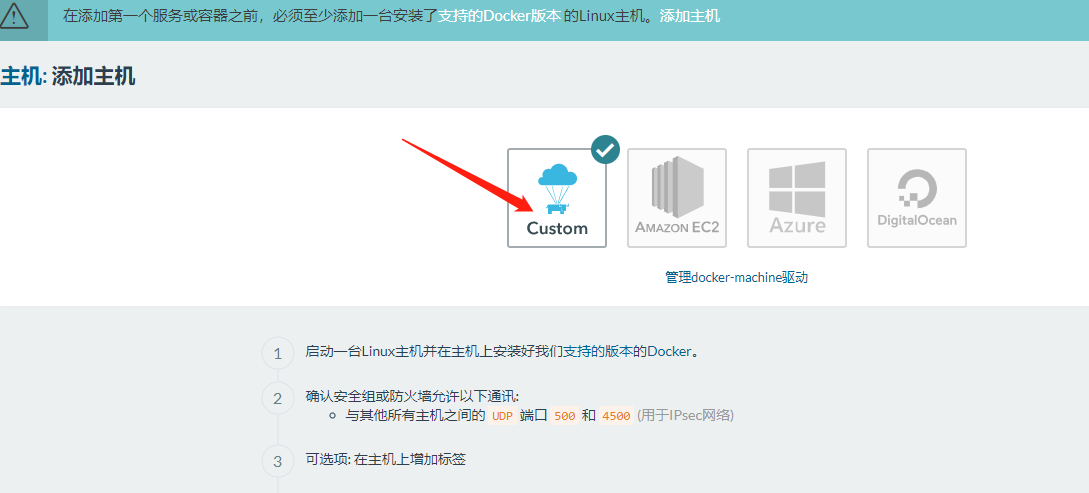
接着安装 rancher-agent
因为 上面的是 rancher-server , 不会和 rancher-agent 在同一台服务器上面
填写 rancher agent 的IP地址
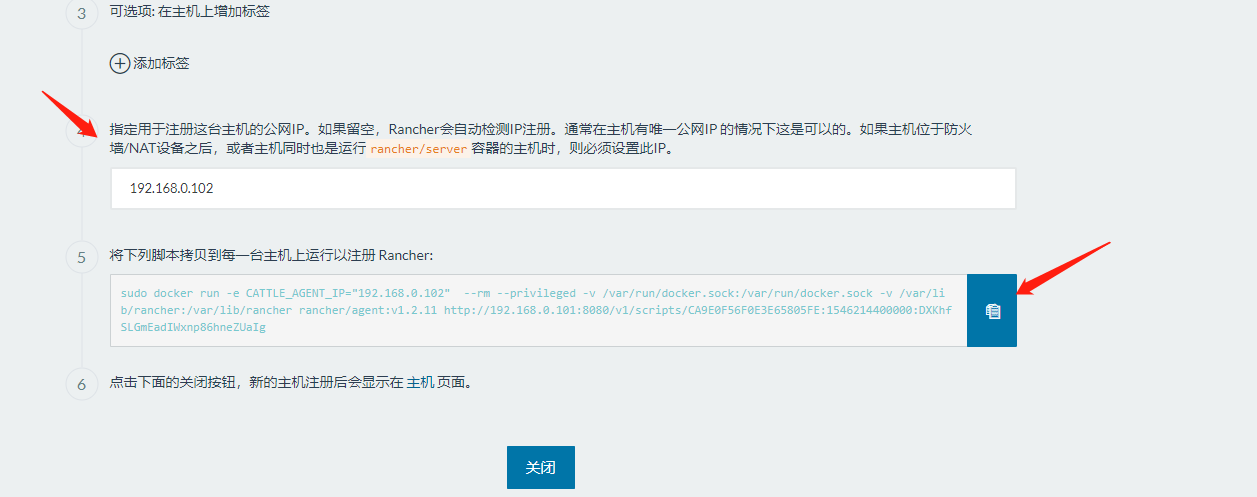
执行比如
sudo docker run -e CATTLE_AGENT_IP="192.168.0.102" --rm --privileged -v /var/run/docker.sock:/var/run/docker.sock -v /var/lib/rancher:/var/lib/rancher rancher/agent:v1.2.11 http://192.168.0.101:8080/v1/scripts/CA9E0F56F0E3E65805FE:1546214400000:DXKhfSLGmEadIWxnp86hneZUaIg之后 点击 关闭,在 基础架构 主机 点击 就看到了
默认容器编排 工具 使用 cattle , 可以自己选择
spring cloud 版本号了解
GA : general availability 面向大众的可用版本 release
M : milestone 里程碑版本
SNAPSHOT 快照 , 代码可变
Graylog
graylog 集成 spring boot 即可
主要是 部署在 docker 上面查看日志很不方便
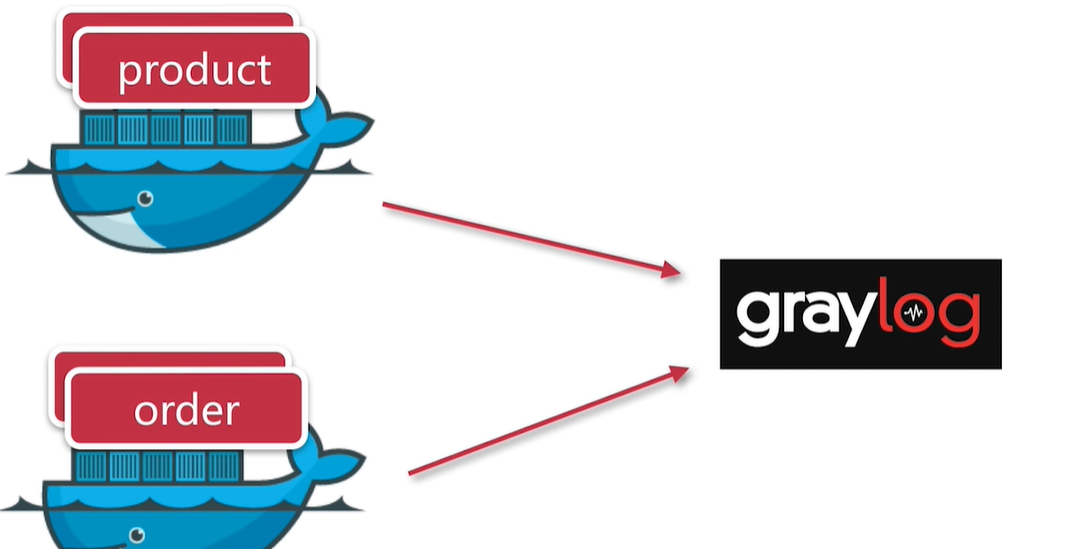
架构图
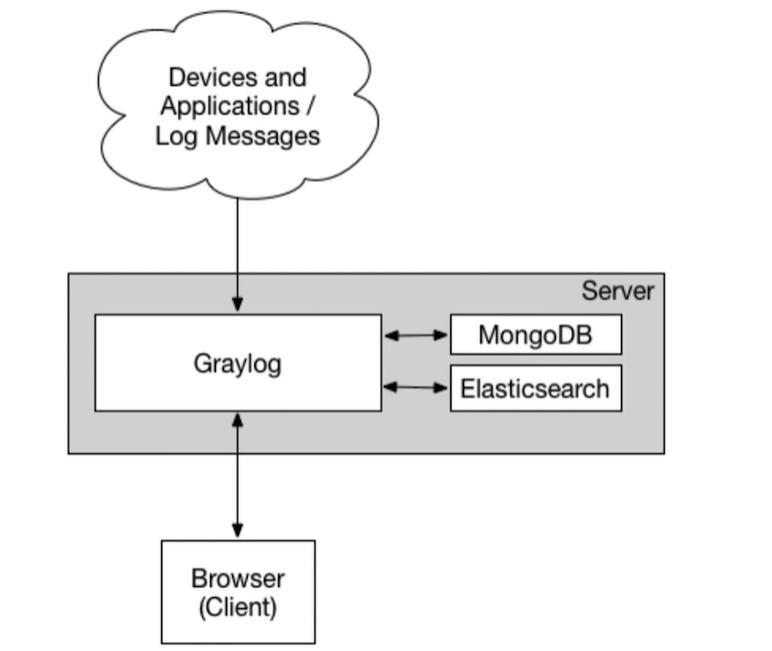
设备和应用的日志内容,可发送到 graylog ,
graylog 需要 MongoDB 和 Elasticesearch 两个,
mongdb 主要存储 配置信息, Elasticesearch 存储日志信息数据
然后通过浏览器可用查看日志了
使用docker 安装
https://hub.docker.com/r/graylog/graylog/
安装文档 http://docs.graylog.org/en/stable/pages/installation/docker.html
搭建可以参考 , 这里搭建是的 旧一点的版本 3.0.0
在 Linux 下 某个文件夹里面 新建一个 docker-compose.yml 这个文件夹
里面加上 这些内容, 下面是 安装的 内容
version: '2'
services:
# MongoDB: https://hub.docker.com/_/mongo/
mongodb:
image: mongo:3
# Elasticsearch: https://www.elastic.co/guide/en/elasticsearch/reference/6.6/docker.html
# elasticsearch:
# image: docker.elastic.co/elasticsearch/elasticsearch-oss:6.6.1
# environment:
# - http.host=0.0.0.0
# - transport.host=localhost
# - network.host=0.0.0.0
# - "ES_JAVA_OPTS=-Xms512m -Xmx512m"
# ulimits:
# memlock:
# soft: -1
# hard: -1
# mem_limit: 1g
# Graylog: https://hub.docker.com/r/graylog/graylog/
graylog:
image: graylog/graylog:3.0
environment:
# CHANGE ME (must be at least 16 characters)!
- GRAYLOG_PASSWORD_SECRET=somepasswordpepper
# Password: 123456 下面是加密命令
# echo -n "Enter Password: " && head -1 </dev/stdin | tr -d '\n' | sha256sum | cut -d" " -f1
- GRAYLOG_ROOT_PASSWORD_SHA2=8c6976e5b5410415bde908bd4dee15dfb167a9c873fc4bb8a81f6f2ab448a918
- GRAYLOG_HTTP_EXTERNAL_URI=http://127.0.0.1:9000/
- GRAYLOG_ELASTICSEARCH_HOSTS=http://192.168.31.32:9200
- GRAYLOG_ROOT_TIMEZONE=Asia/Shanghai
links:
- mongodb:mongo
# - elasticsearch
depends_on:
- mongodb
# - elasticsearch
ports:
# Graylog web interface and REST API
- 9000:9000
# Syslog TCP
- 1514:1514
# Syslog UDP
- 1514:1514/udp
# GELF TCP
- 12201:12201
# GELF UDP
- 12201:12201/udp生产上面 elastcsearche 肯定不是 使用 docker 的 , 包括 mongoDb 也是 一样不会使用 docker的
这里将 elasticsearch 使用 另一个 docker ,而 MongoDB 还是 和 gralog 在一个 docker 里面
下面是 命令,并开放两个端口。 如果是win的docker 可能 9200 被占用了,可以改为其他端口
docker run -d -p 9200:9200 -p 9300:9300 docker.elastic.co/elasticsearch/elasticsearch-oss:6.6.1
执行之后, 访问 localhost:9200 如果成功访问到,说明 已经成功启动了
如果比较慢,可以去阿里云里面配置自己的容器镜像加速地址
比如我的 https://dvefqd9d.mirror.aliyuncs.com
参考 https://blog.csdn.net/sinat_32247833/article/details/79767263
https://cr.console.aliyun.com/cn-hangzhou/instances/mirrors
说明配置
GRAYLOG_HTTP_EXTERNAL_URI 、
如果你要供外网访问gralog , 那么 GRAYLOG_HTTP_EXTERNAL_URI 就需要配置成外网的ip
GRAYLOG_ELASTICSEARCH_HOSTS 外部的 elasticsearch 地址
安装 docker-compose
https://blog.51cto.com/9291927/2310444
在 docker-compose.yml 目录 下执行
docker-compose down
docker-compose up 或者 docker-compose up -d (在后台运行,不会打日志出来)
grylog 启动会比较慢
graylog 默认用户名 密码 admin admin
graylog 整合spring boot
1. 引入 依赖
<dependency> <groupId>de.siegmar</groupId> <artifactId>logback-gelf</artifactId> <version>2.0.0</version> </dependency>
然后 logback 加上 配置
<appender name="GELF" class="de.siegmar.logbackgelf.GelfUdpAppender">
<graylogHost>localhost</graylogHost>
<graylogPort>12201</graylogPort>
<maxChunkSize>508</maxChunkSize>
<useCompression>true</useCompression>
<encoder class="de.siegmar.logbackgelf.GelfEncoder">
<!-- <originHost>localhost</originHost>-->
<includeRawMessage>false</includeRawMessage>
<includeMarker>true</includeMarker>
<includeMdcData>true</includeMdcData>
<includeCallerData>false</includeCallerData>
<includeRootCauseData>false</includeRootCauseData>
<includeLevelName>true</includeLevelName>
<shortPatternLayout class="ch.qos.logback.classic.PatternLayout">
<pattern>%d - %m%nopex</pattern>
</shortPatternLayout>
<fullPatternLayout class="ch.qos.logback.classic.PatternLayout">
<pattern>%d - %m%n</pattern>
</fullPatternLayout>
<staticField>app_name:eureka</staticField>
<staticField>os_arch:${os.arch}</staticField>
<staticField>os_name:${os.name}</staticField>
<staticField>os_version:${os.version}</staticField>
</encoder>
</appender>这里graylog 配置的 是 udp
graylogHost 就是 graylog的地址
启动项目之后
http://192.168.0.102:9000/search ,即访问 graylog 后台的 点击 searched 里面就有日志内容了
TIP docker
网易镜像服务 必须企业才可以用, 不过阿里云的容器镜像服务 是免费的,可以去搞来用。不然就用 docker hub 了
虽然可能网络问题,慢一点。